Компактная схема метода Гаусса для трёхдиагональной матрицы, последовательный вариант: различия между версиями
| [непроверенная версия] | [досмотренная версия] |
Frolov (обсуждение | вклад) |
ASA (обсуждение | вклад) |
||
| (не показано 25 промежуточных версий 5 участников) | |||
| Строка 1: | Строка 1: | ||
{{algorithm | {{algorithm | ||
| − | | name = Компактная схема метода Гаусса для трёхдиагональной матрицы | + | | name = Компактная схема метода Гаусса<br /> для трёхдиагональной матрицы |
| serial_complexity = <math>3n-3</math> | | serial_complexity = <math>3n-3</math> | ||
| pf_height = <math>3n-3</math> | | pf_height = <math>3n-3</math> | ||
| Строка 13: | Строка 13: | ||
=== Общее описание алгоритма === | === Общее описание алгоритма === | ||
| − | '''Компактная схема метода Гаусса для трёхдиагональной матрицы'''<ref>Воеводин В.В. Вычислительные основы линейной алгебры. М.: Наука, 1977.</ref><ref>Воеводин В.В., Кузнецов Ю.А. Матрицы и вычисления. М.: Наука, 1984.</ref> вычисляет такое <math>LU</math>-разложение трёхдиагональной матрицы | + | '''Компактная схема метода Гаусса для трёхдиагональной матрицы'''<ref>Воеводин В.В. Вычислительные основы линейной алгебры. М.: Наука, 1977.</ref><ref>Воеводин В.В., Кузнецов Ю.А. Матрицы и вычисления. М.: Наука, 1984.</ref> вычисляет такое <math>LU</math>-разложение трёхдиагональной матрицы |
| − | |||
| − | + | {{Шаблон:Трёхдиагональная матрица стандартной формы}} | |
| − | + | на две двухдиагональные: | |
| − | :<math> | + | {{Шаблон:L2dUniDiag}} |
| − | u_{11} = a_{11} | + | и |
| − | u_{i i+1} = a_{i i+1}, \quad i \in [1, n-1] | + | {{Шаблон:U2dCommon}}. |
| − | l_{i+1 i} = a_{i+1 i} / u_{i i} , \quad i \in [1, n-1] | + | |
| − | u_{ii} = a_{ii} - l_{i i-1} u_{i-1 i}, \quad i \in [2, n] | + | При такой фиксации диагонали матрицы <math>L</math> все элементы разложения становятся строго предопределёнными, с точностью до ошибок округления. Компактная схема даёт естественные формулы нахождения остальных элементов получающихся двухдиагональных матриц. |
| − | </math> | + | <math>LU</math>-разложение трёхдиагональной матрицы является частным случаем для [[Компактная схема метода Гаусса для плотных матриц|компактной схемы метода Гаусса]] общего вида, однако из-за специфики матрицы характеристики алгоритма кардинально меняются по сравнению с компактной схемой для плотных матриц. |
| + | |||
| + | === Математическое описание алгоритма === | ||
| + | |||
| + | Формулы алгоритма следующие: | ||
| + | |||
| + | <math>u_{11} = a_{11} </math> | ||
| + | |||
| + | <math>u_{i i+1} = a_{i i+1}, \quad i \in [1, n-1] </math> | ||
| + | |||
| + | <math>l_{i+1 i} = a_{i+1 i} / u_{i i} , \quad i \in [1, n-1] </math> | ||
| + | |||
| + | <math>u_{ii} = a_{ii} - l_{i i-1} u_{i-1 i}, \quad i \in [2, n] </math> | ||
=== Вычислительное ядро алгоритма === | === Вычислительное ядро алгоритма === | ||
| Строка 35: | Строка 46: | ||
В качестве макровершины можно взять последовательность трёх операций: деление, умножение, вычитание. Эти макровершины выполняются в алгоритме n-1 раз. | В качестве макровершины можно взять последовательность трёх операций: деление, умножение, вычитание. Эти макровершины выполняются в алгоритме n-1 раз. | ||
| − | === | + | === Схема реализации последовательного алгоритма === |
В схеме учтено, что ряд выходных данных вычислять не нужно - они совпадают с входными. В частности, | В схеме учтено, что ряд выходных данных вычислять не нужно - они совпадают с входными. В частности, | ||
| − | + | <math>u_{11} = a_{11} </math> | |
| − | u_{11} = a_{11} | + | |
| − | u_{i i+1} = a_{i i+1}, \quad i \in [1, n-1] | + | <math>u_{i i+1} = a_{i i+1}, \quad i \in [1, n-1]</math>. |
| − | </math> | ||
В начале процесса <math>i = 1</math> | В начале процесса <math>i = 1</math> | ||
| Строка 65: | Строка 75: | ||
=== Информационный граф === | === Информационный граф === | ||
| − | + | <div class="thumb"> | |
| + | <div class="thumbinner" style="width:{{#expr: 2 * (500 + 35) + 3 * (3 - 1) + 8}}px"> | ||
| + | <gallery widths=500px heights=500px> | ||
| + | File:3dLU.png|Рисунок 1. Граф алгоритма без отображения входных и выходных данных. / - деление, * - умножение, - - вычитание. | ||
| + | File:3dLU_input.png| Рисунок 2. Граф алгоритма с отображением входных данных. / - деление, * - умножение, - - вычитание. | ||
| + | </gallery> | ||
| + | </div> | ||
| + | </div> | ||
| − | Как видно из | + | Как видно из рис.1, на котором одна из операций разложена на 2 составляющие, информационный граф является чисто последовательным. |
| − | === | + | === Ресурс параллелизма алгоритма === |
При разложении трёхдиагональной матрицы порядка n компактной схемой метода Гаусса в требуется выполнить: | При разложении трёхдиагональной матрицы порядка n компактной схемой метода Гаусса в требуется выполнить: | ||
| Строка 79: | Строка 96: | ||
В каждом ярусе - ровно по одной операции. При классификации по параллельной сложности, таким образом, компактная схема метода Гаусса для разложения трёхдиагональной матрицы в последовательном варианте относится к алгоритмам ''с линейной сложностью''. Ширина ярусов везде равна 1, и, таким образом, весь алгоритм представляет собой сплошное "узкое место". | В каждом ярусе - ровно по одной операции. При классификации по параллельной сложности, таким образом, компактная схема метода Гаусса для разложения трёхдиагональной матрицы в последовательном варианте относится к алгоритмам ''с линейной сложностью''. Ширина ярусов везде равна 1, и, таким образом, весь алгоритм представляет собой сплошное "узкое место". | ||
| − | === | + | === Входные и выходные данные алгоритма === |
| + | |||
| + | '''Входные данные''': трёхдиагональная матрица <math>A</math> (элементы <math>a_{ij}</math>). | ||
| + | |||
| + | '''Объём входных данных''': <math>3n-2</math>. В разных реализациях размещение для экономии хранения может быть выполнено разным образом. Например, каждая диагональ может быть строкой массива. | ||
| + | |||
| + | '''Выходные данные''': нижняя двухдиагональная матрица <math>L</math> (элементы <math>l_{ij}</math>, причём <math>l_{ii}=1</math>) и верхняя двухдиагональная матрица <math>U</math> (элементы <math>u_{ij}</math>). | ||
| + | |||
| + | '''Объём выходных данных''': формально <math>3n-2</math>. Однако благодаря совпадению <math>n</math> входных и выходных данных реально вычисляется лишь <math>2n-2</math> элементов. | ||
| + | |||
=== Свойства алгоритма=== | === Свойства алгоритма=== | ||
| + | |||
| + | Соотношение последовательной и параллельной сложности в случае любых ресурсов, как хорошо видно, является '''единицей''' (алгоритм не является распараллеливаемым). | ||
| + | |||
| + | При этом вычислительная мощность алгоритма, как отношение числа операций к суммарному объему входных и выходных данных – всего лишь '''константа''' (арифметических операций столько же, сколько данных). | ||
| + | |||
| + | Описываемый алгоритм является полностью детерминированным. | ||
| + | |||
| + | [[Глоссарий#Эквивалентное возмущение|Эквивалентное возмущение]] <math>M</math> у алгоритма не более возмущения <math>\delta A</math>, вносимому в матрицу при вводе чисел в компьютер: | ||
| + | <math> | ||
| + | ||M||_{E} \leq ||\delta A||_{E} | ||
| + | </math> | ||
== Программная реализация алгоритмов == | == Программная реализация алгоритмов == | ||
| Строка 92: | Строка 129: | ||
END DO | END DO | ||
</source> | </source> | ||
| − | Разложение размещается там же, где размещалась исходная матрица. | + | Разложение размещается там же, где размещалась исходная матрица. |
| − | Однако | + | Индексация такая же как и для плотной матрицы. |
| + | |||
| + | Однако чаще трёхдиагональную матрицу, естественно, хранят более экономно. Например, если диагонали нумеруются слева направо и каждая хранится в одной строке массива, то получается такая версия: | ||
<source lang="fortran"> | <source lang="fortran"> | ||
DO I = 1, N-1 | DO I = 1, N-1 | ||
| Строка 100: | Строка 139: | ||
END DO | END DO | ||
</source> | </source> | ||
| − | в которой также | + | в которой разложение также сохраняется на месте исходных данных. |
| − | + | Элементы A(1,N) и A(3,N) при данном способе хранения не адресуются. | |
| − | |||
| − | |||
| − | |||
| − | === Возможные способы и особенности реализации | + | === Возможные способы и особенности параллельной реализации алгоритма === |
Компактная схема метода Гаусса в применении к разложению трёхдиагональной матрицы - это чисто последовательный алгоритм. Его невозможно исполнять параллельно из-за того, что каждая из операций требует в качестве данных результат предыдущей и сама, в свою очередь, отдаёт результат как входное данное для следующей. | Компактная схема метода Гаусса в применении к разложению трёхдиагональной матрицы - это чисто последовательный алгоритм. Его невозможно исполнять параллельно из-за того, что каждая из операций требует в качестве данных результат предыдущей и сама, в свою очередь, отдаёт результат как входное данное для следующей. | ||
| Строка 114: | Строка 150: | ||
Кроме этого, возможен случай, когда нужны многие разложения разных трёхдиагональных матриц, тогда этот последовательный алгоритм может быть параллельно выполнен для этих матриц на разных узлах вычислительной системы. | Кроме этого, возможен случай, когда нужны многие разложения разных трёхдиагональных матриц, тогда этот последовательный алгоритм может быть параллельно выполнен для этих матриц на разных узлах вычислительной системы. | ||
| − | + | По приведённым фрагментам программ видно, что степень локальности данных и вычислений очень высока. Особенно это выражено для второго варианта, в котором все данные, как используемые операцией, так и вычисляемые ей, хранятся и используются "рядом". Однако выигрыш от столь высокой локальности, однако, ограничен тем, что каждое перевычисляемое данное используется затем только однажды. Это вызвано простой причиной: количество обрабатываемых алгоритмом данных, как уже описано выше, равно количеству арифметических операций. | |
| − | + | === Результаты прогонов === | |
| + | === Выводы для классов архитектур === | ||
| − | + | Из-за последовательной структуры более или менее эффективно алгоритм в своём неизменном виде может быть выполнен только на вычислителе классической фон-неймановской архитектуры. | |
| − | |||
| − | |||
== Литература == | == Литература == | ||
| Строка 126: | Строка 161: | ||
<references /> | <references /> | ||
| − | [[Категория: | + | [[Категория:Законченные статьи]] |
| + | [[Категория:Алгоритмы с низким уровнем параллелизма]] | ||
| + | [[Категория:Разложения матриц]] | ||
| + | [[Категория:Решение систем линейных уравнений]] | ||
| + | |||
| + | [[en:Gaussian elimination, compact scheme for tridiagonal matrices, serial version]] | ||
Текущая версия на 15:43, 8 июля 2022
| Компактная схема метода Гаусса для трёхдиагональной матрицы | |
| Последовательный алгоритм | |
| Последовательная сложность | [math]3n-3[/math] |
| Объём входных данных | [math]3n-2[/math] |
| Объём выходных данных | [math]3n-2[/math] |
| Параллельный алгоритм | |
| Высота ярусно-параллельной формы | [math]3n-3[/math] |
| Ширина ярусно-параллельной формы | [math]1[/math] |
Основные авторы описания: А.В.Фролов
Содержание
- 1 Свойства и структура алгоритмов
- 1.1 Общее описание алгоритма
- 1.2 Математическое описание алгоритма
- 1.3 Вычислительное ядро алгоритма
- 1.4 Макроструктура алгоритма
- 1.5 Схема реализации последовательного алгоритма
- 1.6 Последовательная сложность алгоритма
- 1.7 Информационный граф
- 1.8 Ресурс параллелизма алгоритма
- 1.9 Входные и выходные данные алгоритма
- 1.10 Свойства алгоритма
- 2 Программная реализация алгоритмов
- 3 Литература
1 Свойства и структура алгоритмов
1.1 Общее описание алгоритма
Компактная схема метода Гаусса для трёхдиагональной матрицы[1][2] вычисляет такое [math]LU[/math]-разложение трёхдиагональной матрицы
- [math] A = \begin{bmatrix} a_{11} & a_{12} & 0 & \cdots & \cdots & 0 \\ a_{21} & a_{22} & a_{23}& \cdots & \cdots & 0 \\ 0 & a_{32} & a_{33} & \cdots & \cdots & 0 \\ \vdots & \vdots & \ddots & \ddots & \ddots & 0 \\ 0 & \cdots & \cdots & a_{n-1 n-2} & a_{n-1 n-1} & a_{n-1 n} \\ 0 & \cdots & \cdots & 0 & a_{n n-1} & a_{n n} \\ \end{bmatrix} [/math]
на две двухдиагональные:
- [math] L = \begin{bmatrix} 1 & 0 & 0 & \cdots & \cdots & 0 \\ l_{21} & 1 & 0 & \cdots & \cdots & 0 \\ 0 & l_{32} & 1 & \cdots & \cdots & 0 \\ \vdots & \vdots & \ddots & \ddots & \ddots & 0 \\ 0 & \cdots & \cdots & l_{n-1 n-2} & 1 & 0 \\ 0 & \cdots & \cdots & 0 & l_{n n-1} & 1 \\ \end{bmatrix} [/math]
и
- [math] U = \begin{bmatrix} u_{11} & u_{12} & 0 & \cdots & \cdots & 0 \\ 0 & u_{22} & u_{23}& \cdots & \cdots & 0 \\ 0 & 0 & u_{33} & \cdots & \cdots & 0 \\ \vdots & \vdots & \ddots & \ddots & \ddots & 0 \\ 0 & \cdots & \cdots & 0 & u_{n-1 n-1} & u_{n-1 n} \\ 0 & \cdots & \cdots & 0 & 0 & u_{n n} \\ \end{bmatrix} [/math].
При такой фиксации диагонали матрицы [math]L[/math] все элементы разложения становятся строго предопределёнными, с точностью до ошибок округления. Компактная схема даёт естественные формулы нахождения остальных элементов получающихся двухдиагональных матриц. [math]LU[/math]-разложение трёхдиагональной матрицы является частным случаем для компактной схемы метода Гаусса общего вида, однако из-за специфики матрицы характеристики алгоритма кардинально меняются по сравнению с компактной схемой для плотных матриц.
1.2 Математическое описание алгоритма
Формулы алгоритма следующие:
[math]u_{11} = a_{11} [/math]
[math]u_{i i+1} = a_{i i+1}, \quad i \in [1, n-1] [/math]
[math]l_{i+1 i} = a_{i+1 i} / u_{i i} , \quad i \in [1, n-1] [/math]
[math]u_{ii} = a_{ii} - l_{i i-1} u_{i-1 i}, \quad i \in [2, n] [/math]
1.3 Вычислительное ядро алгоритма
Как видно из формул, n-1 раз повторяется одна и та же последовательность трёх операций: деление, умножение, вычитание.
1.4 Макроструктура алгоритма
В качестве макровершины можно взять последовательность трёх операций: деление, умножение, вычитание. Эти макровершины выполняются в алгоритме n-1 раз.
1.5 Схема реализации последовательного алгоритма
В схеме учтено, что ряд выходных данных вычислять не нужно - они совпадают с входными. В частности,
[math]u_{11} = a_{11} [/math]
[math]u_{i i+1} = a_{i i+1}, \quad i \in [1, n-1][/math].
В начале процесса [math]i = 1[/math]
1. Вычисляется [math]l_{i+1 i} = a_{i+1 i} / u_{i i}[/math]
[math]i[/math] увеличивается на 1
2. Вычисляется [math]u_{ii} = a_{ii} - l_{i i-1} u_{i-1 i}[/math]
Если [math]i = n[/math], то конец, иначе возврат к п.1.
1.6 Последовательная сложность алгоритма
Для разложения трёхдиагональной матрицы порядка n компактной схемой метода Гаусса в последовательном варианте требуется:
- [math]n-1[/math] делений,
- [math]n-1[/math] умножений,
- [math]n-1[/math] сложений (вычитаний).
При классификации по последовательной сложности, таким образом, компактная схема метода Гаусса для разложения трёхдиагональной матрицы в последовательном варианте относится к алгоритмам с линейной сложностью.
1.7 Информационный граф
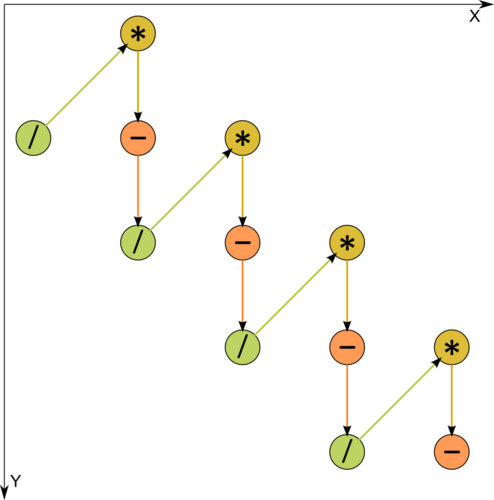
Рисунок 1. Граф алгоритма без отображения входных и выходных данных. / - деление, * - умножение, - - вычитание.
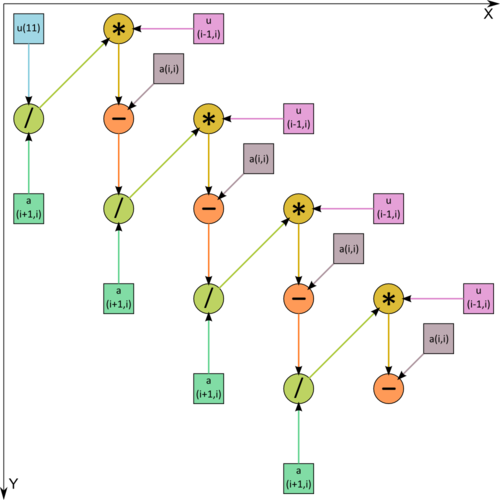
Рисунок 2. Граф алгоритма с отображением входных данных. / - деление, * - умножение, - - вычитание.


Как видно из рис.1, на котором одна из операций разложена на 2 составляющие, информационный граф является чисто последовательным.
1.8 Ресурс параллелизма алгоритма
При разложении трёхдиагональной матрицы порядка n компактной схемой метода Гаусса в требуется выполнить:
- [math]n-1[/math] ярусов делений,
- [math]n-1[/math] ярусов умножений,
- [math]n-1[/math] ярусов сложений (вычитаний).
В каждом ярусе - ровно по одной операции. При классификации по параллельной сложности, таким образом, компактная схема метода Гаусса для разложения трёхдиагональной матрицы в последовательном варианте относится к алгоритмам с линейной сложностью. Ширина ярусов везде равна 1, и, таким образом, весь алгоритм представляет собой сплошное "узкое место".
1.9 Входные и выходные данные алгоритма
Входные данные: трёхдиагональная матрица [math]A[/math] (элементы [math]a_{ij}[/math]).
Объём входных данных: [math]3n-2[/math]. В разных реализациях размещение для экономии хранения может быть выполнено разным образом. Например, каждая диагональ может быть строкой массива.
Выходные данные: нижняя двухдиагональная матрица [math]L[/math] (элементы [math]l_{ij}[/math], причём [math]l_{ii}=1[/math]) и верхняя двухдиагональная матрица [math]U[/math] (элементы [math]u_{ij}[/math]).
Объём выходных данных: формально [math]3n-2[/math]. Однако благодаря совпадению [math]n[/math] входных и выходных данных реально вычисляется лишь [math]2n-2[/math] элементов.
1.10 Свойства алгоритма
Соотношение последовательной и параллельной сложности в случае любых ресурсов, как хорошо видно, является единицей (алгоритм не является распараллеливаемым).
При этом вычислительная мощность алгоритма, как отношение числа операций к суммарному объему входных и выходных данных – всего лишь константа (арифметических операций столько же, сколько данных).
Описываемый алгоритм является полностью детерминированным.
Эквивалентное возмущение [math]M[/math] у алгоритма не более возмущения [math]\delta A[/math], вносимому в матрицу при вводе чисел в компьютер: [math] ||M||_{E} \leq ||\delta A||_{E} [/math]
2 Программная реализация алгоритмов
2.1 Особенности реализации последовательного алгоритма
В простейшем варианте алгоритм на Фортране можно записать так:
DO I = 1, N-1
A(I+1,I) = A(I+1,I)/A(I,I)
A(I+1,I+1) = A(I+1,I+1) - A(I+1,I)*A(I,I+1)
END DO
Разложение размещается там же, где размещалась исходная матрица. Индексация такая же как и для плотной матрицы.
Однако чаще трёхдиагональную матрицу, естественно, хранят более экономно. Например, если диагонали нумеруются слева направо и каждая хранится в одной строке массива, то получается такая версия:
DO I = 1, N-1
A(1,I) = A(1,I)/A(2,I)
A(2,I+1) = A(2,I+1) - A(1,I)*A(3,I)
END DO
в которой разложение также сохраняется на месте исходных данных. Элементы A(1,N) и A(3,N) при данном способе хранения не адресуются.
2.2 Возможные способы и особенности параллельной реализации алгоритма
Компактная схема метода Гаусса в применении к разложению трёхдиагональной матрицы - это чисто последовательный алгоритм. Его невозможно исполнять параллельно из-за того, что каждая из операций требует в качестве данных результат предыдущей и сама, в свою очередь, отдаёт результат как входное данное для следующей.
Варианты распараллеливания компактной схемы метода Гаусса для трёхдиагональной матрицы используют ассоциативность операций, и, следовательно, представляют собой совсем другие алгоритмы, которые можно изучить на соответствующей странице.
Кроме этого, возможен случай, когда нужны многие разложения разных трёхдиагональных матриц, тогда этот последовательный алгоритм может быть параллельно выполнен для этих матриц на разных узлах вычислительной системы.
По приведённым фрагментам программ видно, что степень локальности данных и вычислений очень высока. Особенно это выражено для второго варианта, в котором все данные, как используемые операцией, так и вычисляемые ей, хранятся и используются "рядом". Однако выигрыш от столь высокой локальности, однако, ограничен тем, что каждое перевычисляемое данное используется затем только однажды. Это вызвано простой причиной: количество обрабатываемых алгоритмом данных, как уже описано выше, равно количеству арифметических операций.
2.3 Результаты прогонов
2.4 Выводы для классов архитектур
Из-за последовательной структуры более или менее эффективно алгоритм в своём неизменном виде может быть выполнен только на вычислителе классической фон-неймановской архитектуры.