|
|
| (не показано 50 промежуточных версий этого же участника) |
| Строка 3: |
Строка 3: |
| | == Свойства и структура алгоритмов == | | == Свойства и структура алгоритмов == |
| | === Общее описание алгоритма === | | === Общее описание алгоритма === |
| − | Данный алгоритм находит равновесие Нэша в игре двух лиц с конечным числом стратегий | + | Данный алгоритм находит равновесия Нэша в игре двух лиц с конечным числом стратегий |
| | | | |
| | === Математическое описание алгоритма === | | === Математическое описание алгоритма === |
| | | | |
| − | Определим игру двух лиц. Пусть первый игрок имеет в своём распоряжении стратегии <math> x </math> из множества стратегий <math> X </math>, а второй игрок стратегии <math> y </math> из множества стратегий <math> Y </math>. Будем рассматривать ''игру в нормальной форме''. Это означает, что каждый из игроков выбирает стратегию, не зная выбора партнёра. Пару стратегий <math> (x, y) </math> будем называть ''ситуацией''. у первого игрока имеется функция выигрыша <math> F(x, y) </math>, а у второго <math> G(x, y) </math>. определённые на на множестве всех ситуаций <math> X × Y </math>. каждый игрок стремится, по возможности, максимизировать свою функцию выигрыша. Таким образом, игра двух лиц в нормальной форме может быть задаётся набором | + | Определим игру двух лиц. Пусть первый игрок имеет в своём распоряжении стратегии <math> x </math> из множества стратегий <math> X </math>, а второй игрок стратегии <math> y </math> из множества стратегий <math> Y </math>. Будем рассматривать ''игру в нормальной форме''. Это означает, что каждый из игроков выбирает стратегию, не зная выбора партнёра. Пару стратегий <math> (x, y) </math> будем называть ''ситуацией''. У первого игрока имеется функция выигрыша <math> F(x, y) </math>, а у второго <math> G(x, y) </math>, определённые на на множестве всех ситуаций <math> X × Y </math>. каждый игрок стремится, по возможности, максимизировать свою функцию выигрыша. Таким образом, игра двух лиц в нормальной форме задаётся набором |
| | <math> \Gamma \langle X, Y, F(x, y), G(x, y) \rangle </math>. Ситуация <math> (x^0, y^0) </math> называется ''равновесием по Нэшу'' игры <math> \Gamma </math> если: | | <math> \Gamma \langle X, Y, F(x, y), G(x, y) \rangle </math>. Ситуация <math> (x^0, y^0) </math> называется ''равновесием по Нэшу'' игры <math> \Gamma </math> если: |
| | <math> | | <math> |
| − | \max_{x \in X} F(x, y^0) = F(x^0, y^0) \quad , \quad \max_{y \in Y} F(x^0, y) = G(x^0, y^0) | + | \max_{x \in X} F(x, y^0) = F(x^0, y^0) \quad , \quad \max_{y \in Y} G(x^0, y) = G(x^0, y^0) |
| | </math> | | </math> |
| | | | |
| Строка 19: |
Строка 19: |
| | | | |
| | === Вычислительное ядро алгоритма === | | === Вычислительное ядро алгоритма === |
| − | Сначала будет естественно для каждого столбца матрицы <math> F </math> найти максимум в нём и для каждой строки матрицы <math> G </math> найти максимум в ней. Т.е. мы ищем для каждого из <math> m </math> векторов <math> R^n </math> мы ищем максимум и для каждого из <math> n </math> векторов <math> R^m </math> мы ищем максимум. | + | Сначала будет естественно для каждого столбца матрицы <math> F </math> найти максимум в нём (таким образом мы находим наилучший ответ 1-го игрока, при фиксированной стратегии 2-го) и для каждой строки матрицы <math> G </math> найти максимум в ней (ищем наилучшие ответы 2-го игрока). Т.е. мы ищем для каждого из <math> m </math> векторов <math> R^n </math> мы ищем максимум и для каждого из <math> n </math> векторов <math> R^m </math> мы ищем максимум. |
| | После этого для каждой ситуации <math> (x^0, y^0) </math> несложно понять, является ли она равновесием Нэша: нужно просто проверить, что <math> F(x^0, y^0) </math> - максимальный элемент в <math> y^0 </math>-м столбце матрицы <math> F </math> и <math> G(x^0, y^0) </math> - максимальный элемент в <math> x^0 </math>-ой строке матрицы <math> G </math>. | | После этого для каждой ситуации <math> (x^0, y^0) </math> несложно понять, является ли она равновесием Нэша: нужно просто проверить, что <math> F(x^0, y^0) </math> - максимальный элемент в <math> y^0 </math>-м столбце матрицы <math> F </math> и <math> G(x^0, y^0) </math> - максимальный элемент в <math> x^0 </math>-ой строке матрицы <math> G </math>. |
| | | | |
| | === Макроструктура алгоритма === | | === Макроструктура алгоритма === |
| − | Если алгоритм использует в качестве составных частей другие алгоритмы, то это указывается в данном разделе. Если в дальнейшем имеет смысл описывать алгоритм не в максимально детализированном виде (т.е. на уровне арифметических операций), а давать только его макроструктуру, то здесь описывается структура и состав макроопераций. Если в других разделах описания данного алгоритма в рамках AlgoWiki используются введенные здесь макрооперации, то здесь даются пояснения, необходимые для однозначной интерпретации материала. Типичные варианты макроопераций, часто встречающиеся на практике: нахождение суммы элементов вектора, скалярное произведение векторов, умножение матрицы на вектор, решение системы линейных уравнений малого порядка, сортировка, вычисление значения функции в некоторой точке, поиск минимального значения в массиве, транспонирование матрицы, вычисление обратной матрицы и многие другие.
| |
| | | | |
| − | Описание макроструктуры очень полезно на практике. Параллельная структура алгоритмов может быть хорошо видна именно на макроуровне, в то время как максимально детальное отображение всех операций может сильно усложнить картину. Аналогичные аргументы касаются и многих вопросов реализации, и если для алгоритма эффективнее и/или технологичнее оставаться на макроуровне, оформив макровершину, например, в виде отдельной процедуры, то это и нужно отразить в данном разделе.
| + | Алгоритм в качестве подзадачи многократно использует поис максимума в массиве (<math> n </math> раз в массиве длины <math> m </math> и <math> m </math> раз в массиве длины <math> n </math>). Затем, для все возможных позиций проверяется, является она равноесием по нэшу, как это описывалось в разделе выше. |
| − | Выбор макроопераций не однозначен, причем, выделяя различные макрооперации, можно делать акценты на различных свойствах алгоритмов. С этой точки зрения, в описании одного алгоритма может быть представлено несколько вариантов его макроструктуры, дающих дополнительную информацию о его структуре. На практике, подобные альтернативные формы представления макроструктуры алгоритма могут оказаться исключительно полезными для его эффективной реализации на различных вычислительных платформах.
| |
| | | | |
| | === Схема реализации последовательного алгоритма === | | === Схема реализации последовательного алгоритма === |
| Строка 45: |
Строка 43: |
| | const std::vector<std::vector<double> > &g) | | const std::vector<std::vector<double> > &g) |
| | { | | { |
| | + | //f and g are payoff matrices for first and second players respectively |
| | + | |
| | std::list<std::pair<int, int> > res; | | std::list<std::pair<int, int> > res; |
| | | | |
| Строка 50: |
Строка 50: |
| | int m = g[0].size(); | | int m = g[0].size(); |
| | | | |
| | + | //find best response for first player for each fixed second player's strategy |
| | std::vector<double> maxf(m); | | std::vector<double> maxf(m); |
| | for (int i = 0; i < m; ++i) { | | for (int i = 0; i < m; ++i) { |
| Строка 58: |
Строка 59: |
| | } | | } |
| | | | |
| | + | |
| | + | //and best response for second player |
| | std::vector<double> maxg(n); | | std::vector<double> maxg(n); |
| | for (int i = 0; i < n; ++i) { | | for (int i = 0; i < n; ++i) { |
| Строка 67: |
Строка 70: |
| | | | |
| | | | |
| | + | // consinering best responses for both player check each position if it's nash equilibrium |
| | for (int i = 0; i < n; ++i) { | | for (int i = 0; i < n; ++i) { |
| | for (int j = 0; j < m; ++j) { | | for (int j = 0; j < m; ++j) { |
| Строка 77: |
Строка 81: |
| | return res; | | return res; |
| | } | | } |
| | + | |
| | | | |
| | | | |
| Строка 82: |
Строка 87: |
| | | | |
| | === Последовательная сложность алгоритма === | | === Последовательная сложность алгоритма === |
| − | Очевидно, сложность данного алгоритма будет <math> 2nm </math>
| + | Сложность поиска максима во всех строках(стоблцах) в этих матрицах составит <math> O(nm) </math>. |
| | + | после этого проверка каждого элемента на равновесие имеет сложность <math> O(1) </math>, а всех соответственно <math> O(nm) </math>. |
| | | | |
| | === Информационный граф === | | === Информационный граф === |
| − | Это очень важный раздел описания. Именно здесь можно показать (увидеть) как устроена параллельная структура алгоритма, для чего приводится описание и изображение его информационного графа ([[глоссарий#Граф алгоритма|''графа алгоритма'']] <ref name="VVVVVV">Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. - СПб.: БХВ-Петербург, 2002. - 608 с. </ref>). Для рисунков с изображением графа будут составлены рекомендации по их формированию, чтобы все информационные графы, внесенные в энциклопедию, можно было бы воспринимать и интерпретировать одинаково. Дополнительно можно привести полное параметрическое описание графа в терминах покрывающих функций <ref name="VVVVVV" />.
| + | Для начала был создан граф поиска максимума для каждого столбца матрицы F. поиск максимума для каждой строки матрицы G делается аналогично. |
| | | | |
| − | Интересных вариантов для отражения информационной структуры алгоритмов много. Для каких-то алгоритмов нужно показать максимально подробную структуру, а иногда важнее макроструктура. Много информации несут разного рода проекции информационного графа, выделяя его регулярные составляющие и одновременно скрывая несущественные детали. Иногда оказывается полезным показать последовательность в изменении графа при изменении значений внешних переменных (например, размеров матриц): мы часто ожидаем "подобное" изменение информационного графа, но это изменение не всегда очевидно на практике.
| |
| | | | |
| − | В целом, задача изображения графа алгоритма весьма нетривиальна. Начнем с того, что это потенциально бесконечный граф, число вершин и дуг которого определяется значениями внешних переменных, а они могут быть весьма и весьма велики. В такой ситуации, как правило, спасают упомянутые выше соображения подобия, делающие графы для разных значений внешних переменных "похожими": почти всегда достаточно привести лишь один граф небольшого размера, добавив, что графы для остальных значений будут устроены "точно также". На практике, увы, не всегда все так просто, и здесь нужно быть аккуратным.
| + | [[file:plot.png|thumb|center|600px|Рис.1. поиск максимума для каждого столбца матрицы F]] |
| | | | |
| − | Далее, граф алгоритма - это потенциально многомерный объект. Наиболее естественная система координат для размещения вершин и дуг информационного графа опирается на структуру вложенности циклов в реализации алгоритма. Если глубина вложенности циклов не превышает трех, то и граф размещается в привычном трехмерном пространстве, однако для более сложных циклических конструкций с глубиной вложенности 4 и больше необходимы специальные методы представления и изображения графов.
| + | === Ресурс параллелизма алгоритма === |
| | + | Для нахождения максимума в каждой из <math> n </math> строк матрицы <math> F </math> понадобится <math> m - 1 </math> операция сравнения для вещественных чисел. |
| | + | Аналогично, для нахождения максимума в каждом из <math> m </math> столбцов матрицы <math> G </math> понадобится <math> n - 1 </math> операция сравнения для вещественных чисел. |
| | + | при неограниченном числе ресурсов, все строки столбцы обрабатываются отдельно, поэтому сложность будет <math> max(m, n) </math>. |
| | + | Далее, для определения каждой ситуации на равновесие нужно просто сравнить значение в <math> F </math> с максимумом в столбце и в <math> G </math> с максимумом в строке, т.е. для каждой ситуации это <math> O(1) </math>, а так как, для каждой ситуации это независимые действия, при неограниченном числе ресурсов все вычисления имеют сложность <math> O(1) </math>. |
| | | | |
| − | В данном разделе AlgoWiki могут использоваться многие интересные возможности, которые еще подлежат обсуждению: возможность повернуть граф при его отображении на экране компьютера для выбора наиболее удобного угла обзора, разметка вершин по типу соответствующим им операций, отражение [[глоссарий#Ярусно-параллельная форма графа алгоритма|''ярусно-параллельной формы графа'']] и другие. Но в любом случае нужно не забывать главную задачу данного раздела - показать информационную структуру алгоритма так, чтобы стали понятны все его ключевые особенности, особенности параллельной структуры, особенности множеств дуг, участки регулярности и, напротив, участки с недерминированной структурой, зависящей от входных данных.
| + | === Входные и выходные данные алгоритма === |
| | | | |
| − | На рис.1 показана информационная структура алгоритма умножения матриц, на рис.2 - информационная структура одного из вариантов алгоритма решения систем линейных алгебраических уравнений с блочно-двухдиагональной матрицей.
| + | '''Входные данные:''' |
| | + | две матрицы <math> R^{n × m} </math> |
| | | | |
| − | [[file:plot.png|thumb|center|1200px|Рис.1. Информационная структура алгоритма умножения матриц]] | + | '''Выходные данные:''' |
| − | [[file:Fig2.svg|thumb|center|300px|Рис.2. Информационная структура одного из вариантов алгоритма решения систем линейных алгебраических уравнений с блочно-двухдиагональной матрицей]] | + | список пар <math> (i, j) </math>, где <math> i \in [1 .. n], j \in [1 .. m] </math> |
| | | | |
| − | === Ресурс параллелизма алгоритма === | + | === Свойства алгоритма === |
| − | Здесь приводится оценка [[глоссарий#Параллельная сложность|''параллельной сложности'']] алгоритма: числа шагов, за которое можно выполнить данный алгоритм в предположении доступности неограниченного числа необходимых процессоров (функциональных устройств, вычислительных узлов, ядер и т.п.). Параллельная сложность алгоритма понимается как высота канонической ярусно-параллельной формы <ref name="VVVVVV" />. Необходимо указать, в терминах каких операций дается оценка. Необходимо описать сбалансированность параллельных шагов по числу и типу операций, что определяется шириной ярусов канонической ярусно-параллельной формы и составом операций на ярусах.
| + | |
| | + | == Программная реализация алгоритма == |
| | + | |
| | + | === Особенности реализации последовательного алгоритма === |
| | + | |
| | + | === Локальность данных и вычислений === |
| | + | |
| | + | === Возможные способы и особенности параллельной реализации алгоритма === |
| | + | |
| | + | === Масштабируемость алгоритма и его реализации === |
| | + | на графике показана зависимость времени работы программы от размеров матриц (в тестах они задавались квадратными) и от числа процессоров. |
| | + | диапазоны: |
| | + | |
| | + | '''число процессоров''': [1, 32] |
| | + | |
| | + | '''сторона матриц''': числа от 100 до 24100 с шагом 1000 |
| | + | |
| | + | [[File:Plot.jpg|thumb|center|800px|Рис.1. график зависимости времени работы программы от числа процессоров и стороны матрицы]] |
| | + | |
| | + | На графике видно, что в данных тестах процессы нагружаются оптимально, т.к. их увеличение приводит к сильному уменьшению времени. При данных параметрах можно считать, что время обратно пропорцинально числу процессов. |
| | | | |
| − | Параллелизм в алгоритме часто имеет естественную иерархическую структуру. Этот факт очень полезен на практике, и его необходимо отразить в описании. Как правило, подобная иерархическая структура параллелизма хорошо отражается в последовательной реализации алгоритма через циклический профиль результирующей программы (конечно же, с учетом графа вызовов), поэтому циклический профиль ([[#Описание схемы реализации последовательного алгоритма|п.1.5]]) вполне может быть использован и для отражения ресурса параллелизма.
| + | === Динамические характеристики и эффективность реализации алгоритма === |
| | | | |
| − | Для описания ресурса параллелизма алгоритма (ресурса параллелизма информационного графа) необходимо указать ключевые параллельные ветви в терминах [[глоссарий#Конечный параллелизм|''конечного'']] и [[глоссарий#Массовый параллелизм|''массового'']] параллелизма. Далеко не всегда ресурс параллелизма выражается просто, например, через [[глоссарий#Кооодинатный параллелизм|''координатный параллелизм'']] или, что то же самое, через независимость итераций некоторых циклов (да-да-да, циклы - это понятие, возникающее лишь на этапе реализации, но здесь все так связано… В данном случае, координатный параллелизм означает, что информационно независимые вершины лежат на гиперплоскостях, перпендикулярных одной из координатных осей). С этой точки зрения, не менее важен и ресурс [[глоссарий#Скошенный параллелизм|''скошенного параллелизма'']]. В отличие от координатного параллелизма, скошенный параллелизм намного сложнее использовать на практике, но знать о нем необходимо, поскольку иногда других вариантов и не остается: нужно оценить потенциал алгоритма, и лишь после этого, взвесив все альтернативы, принимать решение о конкретной параллельной реализации. Хорошей иллюстрацией может служить алгоритм, структура которого показана на рис.2: координатного параллелизма нет, но есть параллелизм скошенный, использование которого снижает сложность алгоритма с <math>n\times m</math> в последовательном случае до <math>(n+m-1)</math> в параллельном варианте.
| + | === Выводы для классов архитектур === |
| | | | |
| − | Рассмотрим алгоритмы, последовательная сложность которых уже оценивалась в [[#Последовательная сложность алгоритма|п.1.6]]. Параллельная сложность алгоритма суммирования элементов вектора сдваиванием равна <math>\log_2n</math>, причем число операций на каждом ярусе убывает с <math>n/2</math> до <math>1</math>. Параллельная сложность быстрого преобразования Фурье (базовый алгоритм Кули-Тьюки) для векторов с длиной, равной степени двойки - <math>\log_2n</math>. Параллельная сложность базового алгоритма разложения Холецкого (точечный вариант для плотной симметричной и положительно-определенной матрицы) это <math>n</math> шагов для вычислений квадратного корня, <math>(n-1)</math> шагов для операций деления и <math>(n-1)</math> шагов для операций умножения и сложения.
| + | === Существующие реализации алгоритма === |
| | + | Данный код реализует параллельную версию алгоритма |
| | | | |
| − | === Входные и выходные данные алгоритма === | + | <source lang="C++"> |
| | + | #include <iostream> |
| | + | #include <vector> |
| | + | #include <list> |
| | + | #include <algorithm> |
| | + | #include <mpi.h> |
| | | | |
| − | '''Входные данные:'''
| |
| − | две матрицы <math> R^{n × m} </math>
| |
| | | | |
| − | '''Выходные данные:'''
| + | using namespace std; |
| − | список пар <math> (i, j) </math>, где <math> i \in [1 .. n], j \in [1 .. m] </math>
| |
| | | | |
| − | === Свойства алгоритма ===
| |
| − | Описываются прочие свойства алгоритма, на которые имеет смысл обратить внимание на этапе реализации. Как и ранее, никакой привязки к конкретной программно-аппаратной платформе не предполагается, однако вопросы реализации в проекте AlgoWiki всегда превалируют, и необходимость обсуждения каких-либо свойств алгоритмов определяется именно этим.
| |
| | | | |
| − | Весьма полезным является ''соотношение последовательной и параллельной сложности'' алгоритма. Оба понятия мы рассматривали ранее, но здесь делается акцент на том выигрыше, который теоретически может дать параллельная реализация алгоритма. Не менее важно описать и те сложности, которые могут возникнуть в процессе получения параллельной версии алгоритма.
| + | vector<vector<double> > |
| | + | create_local_matrix( |
| | + | int n, |
| | + | int m, |
| | + | int n_proc, |
| | + | int rank) |
| | + | { |
| | + | int loc_n = rank < n % n_proc ? n / n_proc + 1 : n / n_proc; |
| | | | |
| − | [[глоссарий#Вычислительная мощность|''Вычислительная мощность'']] алгоритма равна отношению числа операций к суммарному объему входных и выходных данных. Она показывает, сколько операций приходится на единицу переданных данных. Несмотря на простоту данного понятия, это значение исключительно полезно на практике: чем выше вычислительная мощность, тем меньше накладных расходов вызывает перемещение данных для их обработки, например, на сопроцессоре, ускорителе или другом узле кластера. Например, вычислительная мощность скалярного произведения двух векторов равна всего лишь <math>1</math>, а вычислительная мощность алгоритма умножения двух квадратных матриц равна <math>2n/3</math>.
| + | vector<vector<double> > F(loc_n, vector<double>(m)); |
| | + | for (auto &i: F) { |
| | + | for (auto &j: i) { |
| | + | j = rand() % 1000; |
| | + | } |
| | + | } |
| | | | |
| − | Вопрос первостепенной важности на последующем этапе реализации - это [[глоссарий#Устойчивость|''устойчивость'']] алгоритма. Все, что касается различных сторон этого понятия, в частности, оценки устойчивости, должно быть описано в данном разделе.
| + | return F; |
| | + | } |
| | | | |
| − | ''Сбалансированность'' вычислительного процесса можно рассматривать с разных сторон. Здесь и сбалансированность типов операций, в частности, арифметических операций между собой (сложение, умножение, деление) или же арифметических операций по отношению к операциям обращения к памяти (чтение/запись). Здесь и сбалансированность операций между параллельными ветвями алгоритма. С одной стороны, балансировка нагрузки является необходимым условием эффективной реализации алгоритма. Вместе с этим, это очень непростая задача, и в описании должно быть отмечено явно, насколько алгоритм обладает этой особенностью. Если обеспечение сбалансированности не очевидно, желательно описать возможные пути решения этой задачи.
| + | vector<double> |
| | + | calc_max_in_rows(const vector<vector<double> > &G) |
| | + | { |
| | + | vector<double> G_max(G.size()); |
| | + | for (int i = 0; i < G.size(); ++i) { |
| | + | G_max[i] = G[i][0]; |
| | + | for (int j = 1; j < G[i].size(); ++j) { |
| | + | G_max[i] = max(G_max[i], G[i][j]); |
| | + | } |
| | + | } |
| | | | |
| − | На практике важна [[глоссарий#Детерминированность|''детерминированность алгоритмов'']], под которой будем понимать постоянство структуры вычислительного процесса. С этой точки зрения, классическое умножение плотных матриц является детерминированным алгоритмом, поскольку его структура при фиксированном размере матриц никак не зависит от элементов входных матриц. Умножение разреженных матриц, когда матрица хранятся в одном из специальных форматов, свойством детерминированности уже не обладает: его свойства, например, степень локальности данных зависит от структуры разреженности входных матриц. Итерационный алгоритм с выходом по точности также не является детерминированным: число итераций, а значит и число операций, меняется в зависимости от входных данных. В этом же ряду стоит использование датчиков случайных чисел, меняющих вычислительный процесс для различных запусков программы. Причина выделения свойства детерминированности понятна: работать с детерминированным алгоритмом проще, поскольку один раз найденная структура и будет определять качество его реализации. Если детерминированность нарушается, то это должно быть здесь описано вместе с описанием того, как недетерминированность влияет на структуру вычислительного процесса.
| + | return G_max; |
| | + | } |
| | | | |
| − | Серьезной причиной недетерминированности работы параллельных программ является изменение порядка выполнения ассоциативных операций. Типичный пример - это использование глобальных MPI-операций на множестве параллельных процессов, например, суммирование элементов распределенного массива. Система времени исполнения MPI сама выбирает порядок выполнения операций, предполагая выполнение свойства ассоциативности, из-за чего ошибки округления меняются от запуска программы к запуску, внося изменения в конечный результат ее работы. Это очень серьезная проблема, которая сегодня встречается часто на системах с массовым параллелизмом и определяет отсутствие повторяемости результатов работы параллельных программ. Данная особенность характерна для [[#ЧАСТЬ. Программная реализация алгоритмов|второй части AlgoWiki]], посвященной реализации алгоритмов, но вопрос очень важный, и соответствующие соображения, по возможности, должны быть отмечены и здесь.
| + | vector<double> |
| | + | calc_max_in_cols(const vector<vector<double> > &F) |
| | + | { |
| | + | vector<double> F_max(F[0].size()); |
| | | | |
| − | Заметим, что, в некоторых случаях, недетерминированность в структуре алгоритмов можно "убрать" введением соответствующих макроопераций, после чего структура становится не только детерминированной, но и более понятной для восприятия. Подобное действие также следует отразить в данном разделе.
| + | for (int i = 0; i < F_max.size(); ++i) { |
| | + | F_max[i] = F[0][i]; |
| | + | for (int j = 1; j < F.size(); ++j) { |
| | + | F_max[i] = max(F_max[i], F[j][i]); |
| | + | } |
| | + | } |
| | + | return F_max; |
| | + | } |
| | | | |
| − | [[глоссарий#Степень исхода|''Степень исхода вершины информационного графа'']] показывает, в скольких операциях ее результат будет использоваться в качестве аргумента. Если степень исхода вершины велика, то на этапе реализации алгоритма нужно позаботиться об эффективном доступе к результату ее работы. В этом смысле, особый интерес представляют рассылки данных, когда результат выполнения одной операции используется во многих других вершинах графа, причем число таких вершин растет с увеличением значения внешних переменных.
| |
| | | | |
| − | ''"Длинные" дуги в информационном графе'' <ref name="VVVVVV" /> говорят о потенциальных сложностях с размещением данных в иерархии памяти компьютера на этапе выполнения программы. С одной стороны, длина дуги зависит от выбора конкретной системы координат, в которой расположены вершины графа, а потому в другой системе координат они попросту могут исчезнуть (но не появится ли одновременно других длинных дуг?). А с другой стороны, вне зависимости от системы координат их присутствие может быть сигналом о необходимости длительного хранения данных на определенном уровне иерархии, что накладывает дополнительные ограничения на эффективность реализации алгоритма. Одной из причин возникновения длинных дуг являются рассылки скалярных величин по всем итерациям какого-либо цикла: в таком виде длинные дуги не вызывают каких-либо серьезных проблем на практике.
| |
| | | | |
| − | Для проектирования специализированных процессоров или реализации алгоритма на ПЛИС представляют интерес ''компактные укладки информационного графа'' <ref name="VVVVVV" />, которые также имеет смысл привести в данном разделе.
| + | int |
| | + | main(int argc, char *argv[]) |
| | + | { |
| | + | int n_proc; |
| | + | int rank; |
| | + | int n, m; |
| | | | |
| − | == Программная реализация алгоритма ==
| |
| − | Вторая часть описания алгоритмов в рамках AlgoWiki рассматривает все составные части процесса их реализации. Рассматривается как последовательная реализация алгоритма, так и параллельная. Описывается взаимосвязь свойств программ, реализующих алгоритм, и особенностей архитектуры компьютера, на которой они выполняются. Исследуется работа с памятью, локальность данных и вычислений, описывается масштабируемость и эффективность параллельных программ, производительность компьютеров, достигаемая на данной программе. Обсуждаются особенности реализации для разных классов архитектур компьютеров, приводятся ссылки на реализации в существующих библиотеках.
| |
| | | | |
| − | === Особенности реализации последовательного алгоритма ===
| |
| − | Здесь описываются особенности и варианты реализации алгоритма в виде последовательной программы, которые влияют на [[глоссарий#Эффективность реализации|''эффективность ее выполнения'']]. В частности, в данном разделе имеет смысл ''сказать о существовании блочных вариантов реализации алгоритма'', дополнительно описав потенциальные преимущества или недостатки, сопровождающие такую реализацию. Важный вопрос - это ''возможные варианты организации работы с данными'', варианты структур данных, наборов временных массивов и другие подобные вопросы. Для различных вариантов реализации следует оценить доступный ресурс параллелизма и объем требуемой памяти.
| |
| | | | |
| − | Важным нюансом является ''описание необходимой разрядности выполнения операций алгоритма'' (точности). На практике часто нет никакой необходимости выполнять все арифметические операции над вещественными числами с двойной точностью, т.к. это не влияет ни на устойчивость алгоритма, ни на точность получаемого результата. В таком случае, если значительную часть операций можно выполнять над типом float, и лишь в некоторых фрагментах необходим переход к типу double, это обязательно нужно отметить. Это прямое указание не только на правильную реализацию с точки зрения устойчивости по отношению к ошибкам округления, но и на более эффективную.
| + | MPI_Init(&argc, &argv); |
| | + | MPI_Comm_size(MPI_COMM_WORLD, &n_proc); |
| | + | MPI_Comm_rank(MPI_COMM_WORLD, &rank); |
| | | | |
| − | Опираясь на информацию из [[#Описание ресурса параллелизма алгоритма|п.1.8]] (описание ресурса параллелизма алгоритма), при описании последовательной версии стоит сказать про возможности [[глоссарий#Эквивалентное преобразование|''эквивалентного преобразования программ'']], реализующих данных алгоритм. В дальнейшем, это даст возможность простого использования доступного параллелизма или же просто покажет, как использовать присущий алгоритму параллелизм на практике. Например, параллелизм на уровне итераций самого внутреннего цикла обычно используется для векторизации. Однако, в некоторых случаях этот параллелизм можно поднять "вверх" по структуре вложенности объемлющих циклов, что делает возможной и эффективную реализацию данного алгоритма на многоядерных SMP-компьютерах.
| |
| | | | |
| − | С этой же точки зрения, в данном разделе весьма полезны соображения по реализации алгоритма на различных параллельных вычислительных платформах. Высокопроизводительные кластеры, многоядерные узлы, возможности для векторизации или использования ускорителей - особенности этих архитектур не только опираются на разные свойства алгоритмов, но и по-разному должны быть выражены в программах, что также желательно описать в данном разделе.
| |
| | | | |
| − | === Локальность данных и вычислений === | + | //reading and sending n and m; |
| − | Вопросы локальности данных и вычислений не часто изучаются на практике, но именно локальность определяет эффективность выполнения программ на современных вычислительных платформах <ref>Воеводин В.В., Воеводин Вад.В. Спасительная локальность суперкомпьютеров //Открытые системы. - 2013. - № 9. - С. 12-15.</ref><ref>Воеводин Вад.В., Швец П. Метод покрытий для оценки локальности использования данных в программах // Вестник УГАТУ. — 2014. — Т. 18, № 1(62). — С. 224–229.</ref>. В данном разделе приводятся оценки степени [[глоссарий#Локальность использования данных|''локальности данных'']] и [[глоссарий#Локальность вычислений|вычислений]] в программе, причем рассматривается как [[глоссарий#Временная локальность|''временна́я'']], так и [[глоссарий#Пространственная локальность|''пространственная'']] локальность. Отмечаются позитивные и негативные факты, связанные с локальностью, какие ситуации и при каких условиях могут возникать. Исследуется, как меняется локальность при переходе от последовательной реализации к параллельной. Выделяются ключевые шаблоны взаимодействия программы, реализующей описываемый алгоритм, с памятью. Отмечается возможная взаимосвязь между используемыми конструкциями языков программирования и степенью локальности, которыми обладают результирующие программы.
| + | if (rank == 0) { |
| | + | // this is main process |
| | + | cin >> n >> m; |
| | + | if (n < m) { |
| | + | swap(n, m); |
| | + | } |
| | + | } |
| | | | |
| − | Отдельно приводятся профили взаимодействия с памятью для вычислительных ядер и ключевых фрагментов. Если из-за большого числа обращений по общему профилю сложно понять реальную специфику взаимодействия программ с памятью, то проводится последовательная детализация и приводится серия профилей более мелкого масштаба.
| + | MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD); |
| | + | MPI_Bcast(&m, 1, MPI_INT, 0, MPI_COMM_WORLD); |
| | | | |
| − | На рис.3 и рис.4 показаны профили обращения в память для программ, реализующих разложение Холецкого и быстрое преобразование Фурье, по которым хорошо видна разница свойств локальности у данных алгоритмов.
| + | //Create and fill its part of matrices F and G |
| | + | srand(time(NULL)); |
| | + | vector<vector<double> > F = create_local_matrix(n, m, n_proc, rank); |
| | + | vector<vector<double> > G = create_local_matrix(n, m, n_proc, rank); |
| | | | |
| − | [[file:Cholesky_locality1.jpg|thumb|center|700px|Рис.3 Реализация метода Холецкого. Общий профиль обращений в память]]
| + | //every process calculate max in every its rows of matrix G and columns of matrix F |
| − | [[file:fft 1.PNG|thumb|center|700px|Рис.4 Нерекурсивная реализация БПФ для степеней двойки. Общий профиль обращений в память]]
| |
| | | | |
| − | === Возможные способы и особенности параллельной реализации алгоритма === | + | int loc_n = rank < n % n_proc ? n / n_proc + 1 : n / n_proc; |
| − | Раздел довольно обширный, в котором должны быть описаны основные факты и положения, формирующие параллельную программу. К их числу можно отнести:
| |
| − | * представленный иерархически ресурс параллелизма, опирающийся на структуру циклических конструкций и на граф вызовов программы;
| |
| − | * комбинацию (иерархию) массового параллелизма и параллелизма конечного;
| |
| − | * возможные способы распределения операций между процессами/нитями;
| |
| − | * возможные способы распределения данных;
| |
| − | * оценку количества операций, объёма и числа пересылок данных (как общего числа, так и в пересчёте на каждый параллельный процесс);
| |
| | | | |
| − | и другие.
| + | //columns of F |
| | + | vector<double> loc_F_col_max = calc_max_in_cols(F); |
| | | | |
| − | В этом же разделе должны быть даны рекомендации или сделаны комментарии относительно реализации алгоритма с помощью различных технологий параллельного программирования: MPI, OpenMP, CUDA или использования директив векторизации.
| + | //and rows of G |
| | + | vector<double> loc_G_row_max = calc_max_in_rows(G); |
| | | | |
| − | === Масштабируемость алгоритма и его реализации ===
| |
| − | Задача данного раздела - показать пределы [[глоссарий#Масштабируемость|''масштабируемости'']] алгоритма на различных платформах. Очень важный раздел. Нужно выделить, описать и оценить влияние точек барьерной синхронизации, глобальных операций, операций сборки/разборки данных, привести оценки или провести исследование [[глоссарий#Сильная масштабируемость|''сильной'']] и [[глоссарий#Слабая масштабируемость|''слабой'']] масштабируемости алгоритма и его реализаций.
| |
| | | | |
| − | Масштабируемость алгоритма определяет свойства самого алгоритма безотносительно конкретных особенностей используемого компьютера. Она показывает, насколько параллельные свойства алгоритма позволяют использовать возможности растущего числа процессорных элементов. Масштабируемость параллельных программ определяется как относительно конкретного компьютера, так и относительно используемой технологии программирования, и в этом случае она показывает, насколько может вырасти реальная производительность данного компьютера на данной программе, записанной с помощью данной технологии программирования, при использовании бóльших вычислительных ресурсов (ядер, процессоров, вычислительных узлов).
| + | //now we gather this local maximums in on common vector |
| | | | |
| − | Ключевой момент данного раздела заключается в том, чтобы показать ''реальные параметры масштабируемости программы'' для данного алгоритма на различных вычислительных платформах в зависимости от числа процессоров и размера задачи <ref>Антонов А.С., Теплов А.М. О практической сложности понятия масштабируемости параллельных программ// Высокопроизводительные параллельные вычисления на кластерных системах (HPC 2014): Материалы XIV Международной конференции -Пермь: Издательство ПНИПУ, 2014. С. 20-27.</ref>. При этом важно подобрать такое соотношение между числом процессоров и размером задачи, чтобы отразить все характерные точки в поведении параллельной программы, в частности, достижение максимальной производительности, а также тонкие эффекты, возникающие, например, из-за блочной структуры алгоритма или иерархии памяти.
| + | vector<double> F_max(m); |
| | + | MPI_Allreduce(loc_F_col_max.data(), F_max.data(), m, MPI_DOUBLE, MPI_MAX, MPI_COMM_WORLD); |
| | | | |
| − | На рис.5. показана масштабируемость классического алгоритма умножения плотных матриц в зависимости от числа процессоров и размера задачи. На графике хорошо видны области с большей производительностью, отвечающие уровням кэш-памяти.
| + | //find nash equilibriums |
| − | [[file:Масштабируемость перемножения матриц производительность.png|thumb|center|700px|Рис.5 Масштабируемость классического алгоритма умножения плотных матриц в зависимости от числа процессоров и размера задачи]]
| |
| | | | |
| − | === Динамические характеристики и эффективность реализации алгоритма ===
| + | vector<pair<int, int> > loc_ans; |
| − | Это объемный раздел AlgoWiki, поскольку оценка эффективности реализации алгоритма требует комплексного подхода <ref>Никитенко Д.А. Комплексный анализ производительности суперкомпьютерных систем, основанный на данных системного мониторинга // Вычислительные методы и программирование. 2014. 15. 85–97.</ref>, предполагающего аккуратный анализ всех этапов от архитектуры компьютера до самого алгоритма. Основная задача данного раздела заключается в том, чтобы оценить степень эффективности параллельных программ, реализующих данный алгоритм на различных платформах, в зависимости от числа процессоров и размера задачи. Эффективность в данном разделе понимается широко: это и [[глоссарий#Эффективность распараллеливания|''эффективность распараллеливания'']] программы, это и [[глоссарий#Эффективность реализации|''эффективность реализации'']] программ по отношению к пиковым показателям работы вычислительных систем.
| |
| | | | |
| − | Помимо собственно показателей эффективности, нужно описать и все основные причины, из-за которых эффективность работы параллельной программы на конкретной вычислительной платформе не удается сделать выше. Это не самая простая задача, поскольку на данный момент нет общепринятой методики и соответствующего инструментария, с помощью которых подобный анализ можно было бы провести. Требуется оценить и описать эффективность работы с памятью (особенности профиля взаимодействия программы с памятью), эффективность использования заложенного в алгоритм ресурса параллелизма, эффективность использования коммуникационной сети (особенности коммуникационного профиля), эффективность операций ввода/вывода и т.п. Иногда достаточно интегральных характеристик по работе программы, в некоторых случаях полезно показать данные мониторинга нижнего уровня, например, по загрузке процессора, кэш-промахам, интенсивности использования сети Infiniband и т.п. Хорошее представление о работе параллельной MPI-программы дают данные трассировки, полученные, например, с помощью системы Scalasca.
| + | for (int i = 0; i < loc_n; ++i) { |
| | + | for (int j = 0; j < m; ++j) { |
| | + | if (F[i][j] == F_max[j] && G[i][j] == loc_G_row_max[i]) { |
| | + | loc_ans.push_back(make_pair(i, j)); |
| | + | } |
| | + | } |
| | + | } |
| | | | |
| − | === Выводы для классов архитектур ===
| |
| − | В данный раздел должны быть включены рекомендации по реализации алгоритма для разных классов архитектур. Если архитектура какого-либо компьютера или платформы обладает специфическими особенностями, влияющими на эффективность реализации, то это здесь нужно отметить.
| |
| | | | |
| − | На практике это сделать можно по-разному: либо все свести в один текущий раздел, либо же соответствующие факты сразу включать в предшествующие разделы, где они обсуждаются и необходимы по смыслу. В некоторых случаях, имеет смысл делать отдельные варианты всей [[#ЧАСТЬ. Программная реализация алгоритмов|части II]] AlgoWiki применительно к отдельным классам архитектур, оставляя общей машинно-независимую [[#ЧАСТЬ. Свойства и структура алгоритмов|часть I]]. В любом случае, важно указать и позитивные, и негативные факты по отношению к конкретным классам. Можно говорить о возможных вариантах оптимизации или даже о "трюках" в написании программ, ориентированных на целевые классы архитектур.
| + | MPI_Finalize(); |
| | | | |
| − | === Существующие реализации алгоритма ===
| + | } |
| − | Для многих пар алгоритм+компьютер уже созданы хорошие реализации, которыми можно и нужно пользоваться на практике. Данный раздел предназначен для того, чтобы дать ссылки на основные существующие последовательные и параллельные реализации алгоритма, доступные для использования уже сейчас. Указывается, является ли реализация коммерческой или свободной, под какой лицензией распространяется, приводится местоположение дистрибутива и имеющихся описаний. Если есть информация об особенностях, достоинствах и/или недостатках различных реализаций, то это также нужно здесь указать. Хорошими примерами реализации многих алгоритмов являются MKL, ScaLAPACK, PETSc, FFTW, ATLAS, Magma и другие подобные библиотеки.
| |
| | | | |
| | + | </source> |
| | | | |
| | = Литература = | | = Литература = |
Основные авторы описания: К.В.Телегин
1 Свойства и структура алгоритмов
1.1 Общее описание алгоритма
Данный алгоритм находит равновесия Нэша в игре двух лиц с конечным числом стратегий
1.2 Математическое описание алгоритма
Определим игру двух лиц. Пусть первый игрок имеет в своём распоряжении стратегии [math] x [/math] из множества стратегий [math] X [/math], а второй игрок стратегии [math] y [/math] из множества стратегий [math] Y [/math]. Будем рассматривать игру в нормальной форме. Это означает, что каждый из игроков выбирает стратегию, не зная выбора партнёра. Пару стратегий [math] (x, y) [/math] будем называть ситуацией. У первого игрока имеется функция выигрыша [math] F(x, y) [/math], а у второго [math] G(x, y) [/math], определённые на на множестве всех ситуаций [math] X × Y [/math]. каждый игрок стремится, по возможности, максимизировать свою функцию выигрыша. Таким образом, игра двух лиц в нормальной форме задаётся набором
[math] \Gamma \langle X, Y, F(x, y), G(x, y) \rangle [/math]. Ситуация [math] (x^0, y^0) [/math] называется равновесием по Нэшу игры [math] \Gamma [/math] если:
[math]
\max_{x \in X} F(x, y^0) = F(x^0, y^0) \quad , \quad \max_{y \in Y} G(x^0, y) = G(x^0, y^0)
[/math]
Иными словами, каждому из игроков невыгодно отколняться от ситуации равновесия.[1]
В данной статье мы рассмотрим нахождение ситуаций равновесий Нэша в одном специальном случае для множеств [math] X, Y [/math]. Назовём игру [math] \Gamma [/math] биматричной, если [math] X, Y [/math] - конечные множества.
тогда можно считать, что [math] X = [1, ..., n], Y = [1, ..., m] [/math], а [math] F, G [/math] - являются матрицами [math] R^{n × m} [/math]
1.3 Вычислительное ядро алгоритма
Сначала будет естественно для каждого столбца матрицы [math] F [/math] найти максимум в нём (таким образом мы находим наилучший ответ 1-го игрока, при фиксированной стратегии 2-го) и для каждой строки матрицы [math] G [/math] найти максимум в ней (ищем наилучшие ответы 2-го игрока). Т.е. мы ищем для каждого из [math] m [/math] векторов [math] R^n [/math] мы ищем максимум и для каждого из [math] n [/math] векторов [math] R^m [/math] мы ищем максимум.
После этого для каждой ситуации [math] (x^0, y^0) [/math] несложно понять, является ли она равновесием Нэша: нужно просто проверить, что [math] F(x^0, y^0) [/math] - максимальный элемент в [math] y^0 [/math]-м столбце матрицы [math] F [/math] и [math] G(x^0, y^0) [/math] - максимальный элемент в [math] x^0 [/math]-ой строке матрицы [math] G [/math].
1.4 Макроструктура алгоритма
Алгоритм в качестве подзадачи многократно использует поис максимума в массиве ([math] n [/math] раз в массиве длины [math] m [/math] и [math] m [/math] раз в массиве длины [math] n [/math]). Затем, для все возможных позиций проверяется, является она равноесием по нэшу, как это описывалось в разделе выше.
1.5 Схема реализации последовательного алгоритма
Данный код реализует последовательную версию алгоритма
#include <vector>
#include <algorithm>
#include <list>
#include <utility>
std::list<std::pair<int, int> >
nash_equilibrium(
const std::vector<std::vector<double> > &f,
const std::vector<std::vector<double> > &g)
{
//f and g are payoff matrices for first and second players respectively
std::list<std::pair<int, int> > res;
int n = f.size();
int m = g[0].size();
//find best response for first player for each fixed second player's strategy
std::vector<double> maxf(m);
for (int i = 0; i < m; ++i) {
maxf[i] = f[0][i];
for (int j = 1; j < n; ++j) {
maxf[i] = std::max(maxf[i], f[j][i]);
}
}
//and best response for second player
std::vector<double> maxg(n);
for (int i = 0; i < n; ++i) {
maxg[i] = g[i][0];
for (int j = 1; j < m; ++j) {
maxg[i] = std::max(maxg[i], g[i][j]);
}
}
// consinering best responses for both player check each position if it's nash equilibrium
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (f[i][j] == maxf[j] && g[i][j] == maxg[i]) {
res.emplace_back(i, j);
}
}
}
return res;
}
1.6 Последовательная сложность алгоритма
Сложность поиска максима во всех строках(стоблцах) в этих матрицах составит [math] O(nm) [/math].
после этого проверка каждого элемента на равновесие имеет сложность [math] O(1) [/math], а всех соответственно [math] O(nm) [/math].
1.7 Информационный граф
Для начала был создан граф поиска максимума для каждого столбца матрицы F. поиск максимума для каждой строки матрицы G делается аналогично.

Рис.1. поиск максимума для каждого столбца матрицы F
1.8 Ресурс параллелизма алгоритма
Для нахождения максимума в каждой из [math] n [/math] строк матрицы [math] F [/math] понадобится [math] m - 1 [/math] операция сравнения для вещественных чисел.
Аналогично, для нахождения максимума в каждом из [math] m [/math] столбцов матрицы [math] G [/math] понадобится [math] n - 1 [/math] операция сравнения для вещественных чисел.
при неограниченном числе ресурсов, все строки столбцы обрабатываются отдельно, поэтому сложность будет [math] max(m, n) [/math].
Далее, для определения каждой ситуации на равновесие нужно просто сравнить значение в [math] F [/math] с максимумом в столбце и в [math] G [/math] с максимумом в строке, т.е. для каждой ситуации это [math] O(1) [/math], а так как, для каждой ситуации это независимые действия, при неограниченном числе ресурсов все вычисления имеют сложность [math] O(1) [/math].
1.9 Входные и выходные данные алгоритма
Входные данные:
две матрицы [math] R^{n × m} [/math]
Выходные данные:
список пар [math] (i, j) [/math], где [math] i \in [1 .. n], j \in [1 .. m] [/math]
1.10 Свойства алгоритма
2 Программная реализация алгоритма
2.1 Особенности реализации последовательного алгоритма
2.2 Локальность данных и вычислений
2.3 Возможные способы и особенности параллельной реализации алгоритма
2.4 Масштабируемость алгоритма и его реализации
на графике показана зависимость времени работы программы от размеров матриц (в тестах они задавались квадратными) и от числа процессоров.
диапазоны:
число процессоров: [1, 32]
сторона матриц: числа от 100 до 24100 с шагом 1000
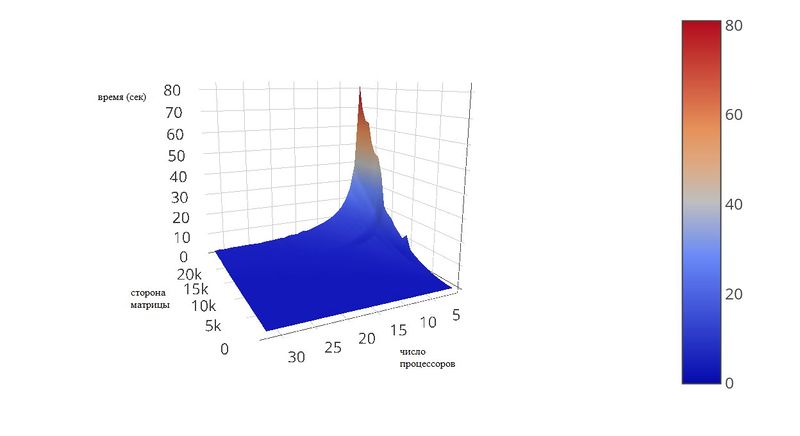
Рис.1. график зависимости времени работы программы от числа процессоров и стороны матрицы
На графике видно, что в данных тестах процессы нагружаются оптимально, т.к. их увеличение приводит к сильному уменьшению времени. При данных параметрах можно считать, что время обратно пропорцинально числу процессов.
2.5 Динамические характеристики и эффективность реализации алгоритма
2.6 Выводы для классов архитектур
2.7 Существующие реализации алгоритма
Данный код реализует параллельную версию алгоритма
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
#include <mpi.h>
using namespace std;
vector<vector<double> >
create_local_matrix(
int n,
int m,
int n_proc,
int rank)
{
int loc_n = rank < n % n_proc ? n / n_proc + 1 : n / n_proc;
vector<vector<double> > F(loc_n, vector<double>(m));
for (auto &i: F) {
for (auto &j: i) {
j = rand() % 1000;
}
}
return F;
}
vector<double>
calc_max_in_rows(const vector<vector<double> > &G)
{
vector<double> G_max(G.size());
for (int i = 0; i < G.size(); ++i) {
G_max[i] = G[i][0];
for (int j = 1; j < G[i].size(); ++j) {
G_max[i] = max(G_max[i], G[i][j]);
}
}
return G_max;
}
vector<double>
calc_max_in_cols(const vector<vector<double> > &F)
{
vector<double> F_max(F[0].size());
for (int i = 0; i < F_max.size(); ++i) {
F_max[i] = F[0][i];
for (int j = 1; j < F.size(); ++j) {
F_max[i] = max(F_max[i], F[j][i]);
}
}
return F_max;
}
int
main(int argc, char *argv[])
{
int n_proc;
int rank;
int n, m;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &n_proc);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
//reading and sending n and m;
if (rank == 0) {
// this is main process
cin >> n >> m;
if (n < m) {
swap(n, m);
}
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&m, 1, MPI_INT, 0, MPI_COMM_WORLD);
//Create and fill its part of matrices F and G
srand(time(NULL));
vector<vector<double> > F = create_local_matrix(n, m, n_proc, rank);
vector<vector<double> > G = create_local_matrix(n, m, n_proc, rank);
//every process calculate max in every its rows of matrix G and columns of matrix F
int loc_n = rank < n % n_proc ? n / n_proc + 1 : n / n_proc;
//columns of F
vector<double> loc_F_col_max = calc_max_in_cols(F);
//and rows of G
vector<double> loc_G_row_max = calc_max_in_rows(G);
//now we gather this local maximums in on common vector
vector<double> F_max(m);
MPI_Allreduce(loc_F_col_max.data(), F_max.data(), m, MPI_DOUBLE, MPI_MAX, MPI_COMM_WORLD);
//find nash equilibriums
vector<pair<int, int> > loc_ans;
for (int i = 0; i < loc_n; ++i) {
for (int j = 0; j < m; ++j) {
if (F[i][j] == F_max[j] && G[i][j] == loc_G_row_max[i]) {
loc_ans.push_back(make_pair(i, j));
}
}
}
MPI_Finalize();
}
3 Литература
- ↑ Васин А.А., Морозов В.В. "Введение в теорию игр с приложениями в экономике"(учебное пособие). - М.: 2003. - 278 с. Pages 91-92

