|
|
| (не показано 29 промежуточных версий этого же участника) |
| Строка 9: |
Строка 9: |
| | 1. Выбрать подпространство значений параметров, на котором будет рассматриваться поведение системы. | | 1. Выбрать подпространство значений параметров, на котором будет рассматриваться поведение системы. |
| | | | |
| − | 2. Для каждого набора значений параметров вычислить N последовательных состояний системы, начиная с начального состояния, где N - достаточно большое число квантов времени. Этот шаг выполняется для стабилизации системы, в случае если для данного значения параметров система не ведет себя хаотично (имеет устойчивую точку, цикл, аттрактор и т.п.). | + | 2. Для каждого набора значений параметров вычислить <math>N</math> последовательных состояний системы, начиная с начального состояния, где <math>N</math> - достаточно большое число квантов времени. Этот шаг выполняется для стабилизации системы, в случае если для данного значения параметров система не ведет себя хаотично (имеет устойчивую точку, цикл, аттрактор и т.п.). |
| | | | |
| − | 3. Вычислить еще K состояний системы, начиная с N-го состояния и вывести соответствующие результаты вместе со значениями параметров в файл. Чем больше число K, тем точнее будет бифуркационная диаграмма. | + | 3. Вычислить еще <math>K</math> состояний системы, начиная с <math>N</math>-го состояния и вывести соответствующие результаты вместе со значениями параметров в файл. Чем больше число <math>K</math>, тем точнее будет бифуркационная диаграмма. |
| | | | |
| | 4. Отобразить полученные результаты графически. | | 4. Отобразить полученные результаты графически. |
| | | | |
| | == Вычислительное ядро алгоритма == | | == Вычислительное ядро алгоритма == |
| − | В описываемом алгоритме выделяется и описывается [[глоссарий#Вычислительное ядро|''вычислительное ядро'']], т.е. та часть алгоритма, на которую приходится основное время работы алгоритма. Если в алгоритме несколько вычислительных ядер, то отдельно описывается каждое ядро. Описание может быть сделано в достаточно произвольной форме: словесной или с использованием языка математических формул. Вычислительное ядро может полностью совпадать с описываемым алгоритмом.
| + | Вычислительным ядром алгоритма является цикл прохода по сетке рассматриваемых значений параметров. На каждой итерации внешнего цикла проходятся два цикла, последовательно вычисляющие последующие состояния системы на основании рассматриваемых значений параметров и необходимого количества предыдущих состояний системы. В первом цикле рассчитываются <math>N</math> состояний системы без вывода полученных данных, где <math>N</math> — достаточно большое число итераций, необходимое для того, чтобы система стабилизировалась. Во втором цикле рассчитываются следующие <math>K</math> состояний системы, полученные значения выводятся. Здесь <math>K</math> задается исходя из желаемого качества отображения бифуркационной диаграммы. |
| | | | |
| | == Макроструктура алгоритма == | | == Макроструктура алгоритма == |
| − | Если алгоритм использует в качестве составных частей другие алгоритмы, то это указывается в данном разделе. Если в дальнейшем имеет смысл описывать алгоритм не в максимально детализированном виде (т.е. на уровне арифметических операций), а давать только его макроструктуру, то здесь описывается структура и состав макроопераций. Если в других разделах описания данного алгоритма в рамках AlgoWiki используются введенные здесь макрооперации, то здесь даются пояснения, необходимые для однозначной интерпретации материала. Типичные варианты макроопераций, часто встречающиеся на практике: нахождение суммы элементов вектора, скалярное произведение векторов, умножение матрицы на вектор, решение системы линейных уравнений малого порядка, сортировка, вычисление значения функции в некоторой точке, поиск минимального значения в массиве, транспонирование матрицы, вычисление обратной матрицы и многие другие.
| + | Как уже сказано в описании ядра алгоритма, основную часть метода составляют вычисления состояний системы в зависимости от значений параметров и характерного для рассматриваемой системы числа предыдущих состояний. |
| − | | |
| − | Описание макроструктуры очень полезно на практике. Параллельная структура алгоритмов может быть хорошо видна именно на макроуровне, в то время как максимально детальное отображение всех операций может сильно усложнить картину. Аналогичные аргументы касаются и многих вопросов реализации, и если для алгоритма эффективнее и/или технологичнее оставаться на макроуровне, оформив макровершину, например, в виде отдельной процедуры, то это и нужно отразить в данном разделе.
| |
| − | Выбор макроопераций не однозначен, причем, выделяя различные макрооперации, можно делать акценты на различных свойствах алгоритмов. С этой точки зрения, в описании одного алгоритма может быть представлено несколько вариантов его макроструктуры, дающих дополнительную информацию о его структуре. На практике, подобные альтернативные формы представления макроструктуры алгоритма могут оказаться исключительно полезными для его эффективной реализации на различных вычислительных платформах.
| |
| | | | |
| | == Схема реализации последовательного алгоритма == | | == Схема реализации последовательного алгоритма == |
| − | Здесь описываются все шаги, которые нужно выполнить при последовательной реализации данного алгоритма. В некотором смысле, данный раздел является избыточным, поскольку математическое описание уже содержит всю необходимую информацию. Однако он, несомненно, полезен: схема реализации алгоритма выписывается явно, помогая однозначной интерпретации приводимых далее оценок и свойств.
| + | Рассмотрим фрагмент реализации алгоритма на c++ для системы <math>u_t = ru_{t - 1}(1 - u_{t-1}), u_0 = u^0</math> на области изменения параметра <math>0\leqslant r \leqslant 4</math>. |
| | | | |
| − | Описание может быть выполнено в виде блок-схемы, последовательности математических формул, обращений к описанию других алгоритмов, фрагмента кода на Фортране, Си или другом языке программирования, фрагмента кода на псевдокоде и т.п. Главное - это сделать схему реализации последовательного алгоритма полностью понятной. Совершенно не обязательно все шаги детализировать до элементарных операций, отдельные шаги могут соответствовать макрооперациям, отвечающим другим алгоритмам.
| + | <source lang="c++"> |
| | + | double system_func(double u0, double r) //задаем систему |
| | + | { |
| | + | return r*u0*(1 - u0); |
| | + | } |
| | | | |
| − | Описание схемы реализации вполне может содержать и словесные пояснения, отражающие какие-либо тонкие нюансы самого алгоритма или его реализации. Уже в данном разделе можно сказать про возможный компромисс между объемом требуемой оперативной памяти и временем работы алгоритма, между используемыми структурами данных и степенью доступного параллелизма. В частности, часто возникает ситуация, когда можно ввести дополнительные временные массивы или же отказаться от использования специальных компактных схем хранения данных, увеличивая степень доступного параллелизма.
| + | int main() |
| | + | { |
| | + | int t_stabilize = 900; //номер кванта времени, после которого считаем, что система стабильна |
| | + | int t_print = 1000; //номер кванта времени, на котором преращаем вывод полученных точек для системы при конкретном значении параметра |
| | + | double rmin = 0; //минимальное рассматриваемое значение параметра |
| | + | double rmax = 4; //максимальное рассматриваемое значение параметра |
| | + | double r; |
| | + | double u0; |
| | + | int N = 1024; |
| | + | double coef = (rmax - rmin)/N; //расчет шага сетки |
| | + | int i; |
| | + | double t; |
| | + | double u; |
| | + | for (i = 1; i <= N; i++) |
| | + | { |
| | + | r = rmin + coef*i; //взятие нового значения параметра на сетке |
| | + | u0 = 0.1; //взятие начального состояния системы |
| | + | u = u0; |
| | + | for (t = 1; t <= t_stabilize; t++) //расчет последовательных состояний системы до момента стабилизации |
| | + | { |
| | + | u = system_func(u0, r); //расчет следующего состояния системы |
| | + | u0 = u; //фиксация предыдущего состояния системы для следующей итерации |
| | + | } |
| | + | for (t = t_stabilize + 1; t <= t_print; t++) //расчет заданного количества состояний системы после момент стабилизации для вывода |
| | + | { |
| | + | u = system_func(u0, r); |
| | + | cout << r << ' ' << u << end; //вывод значения параметра и состояния системы для последующей визуализации |
| | + | u0 = u; |
| | + | } |
| | + | } |
| | + | } |
| | + | </source> |
| | | | |
| | == Последовательная сложность алгоритма == | | == Последовательная сложность алгоритма == |
| − | В данном разделе описания свойств алгоритма приводится оценка его [[глоссарий#Последовательная сложность|''последовательной сложности'']], т.е. числа операций, которые нужно выполнить при последовательном исполнении алгоритма (в соответствии с [[#Описание схемы реализации последовательного алгоритма|п.1.5]]). Для разных алгоритмов понятие операции, в терминах которой оценивается его сложность, может существенно различаться. Это могут быть операции для работы с вещественными числами, целыми числами, поразрядные операции, обращения в память, обновления элементов массива, элементарные функции, макрооперации и другие. В LU-разложении преобладают арифметические операции над вещественными числами, а для транспонирования матриц важны лишь обращения к памяти: это и должно найти отражение в описании.
| + | Рассмотрим сложность последовательной реализации ядра алгоритма в терминах арифметических операций: сложений/вычитаний и умножений/делений. |
| | + | |
| | + | Пусть на сетке значений параметра <math>P</math> узлов, система стабилизируется за <math>N</math> квантов времени, выводится <math>K</math> состояний системы. Пусть для вычисления следующего значения функции нужно привести <math>m</math> умножений/делений и <math>a</math> сложений/вычитаний. Тогда сложность последовательной реализации составляет <math>P(1 +(N + K)m)</math> умножений/делений и <math>P(1 + (N + K)a)</math> сложений/вычитаний. |
| | + | |
| | + | == Информационный граф == |
| | + | [[file: inf_graph.png|400px]] |
| | + | |
| | + | Синим цветом обозначен блок инициализации начальных условий (например, шага сетки), красным - взятие текущего значения параметров на сетке, желтым - блок стабилизации системы (проход первого внутреннего цикла), зеленым - расчет последующих состояний системы с выводом (проход второго внутреннего цикла). |
| | + | |
| | + | == Ресурс параллелизма алгоритма == |
| | + | Ресурс параллелизма алгоритма заключается в информационной независимости итераций внешнего цикла. Таким образом можно разделить внешний цикл по значениям параметра на разные процессы. |
| | + | |
| | + | == Входные и выходные данные алгоритма == |
| | + | Входные данные: |
| | + | |
| | + | <math>N</math> - количество узлов сетки значений параметров; |
| | | | |
| − | Если выбор конкретного типа операций для оценки сложности алгоритма не очевиден, то нужно привести обоснование возможных вариантов. В некоторых случаях можно приводить оценку не всего алгоритма, а лишь его вычислительного ядра: в таком случае это нужно отметить, сославшись [[#Общее описание алгоритма|на п.1.1]].
| + | <math>t_{stabilize}</math> - номер кванта времени, после которого считаем систему стабильной; |
| | | | |
| − | Например, сложность алгоритма суммирования элементов вектора сдваиванием равна <math>n-1</math>. Сложность быстрого преобразования Фурье (базовый алгоритм Кули-Тьюки) для векторов с длиной, равной степени двойки – <math>n\log_2n</math> операций комплексного сложения и <math>(n\log_2n)/2</math> операций комплексного умножения. Сложность базового алгоритма разложения Холецкого (точечный вариант для плотной симметричной и положительно-определенной матрицы) это <math>n</math> вычислений квадратного корня, <math>n(n-1)/2</math> операций деления, по <math>(n^3-n)/6</math> операций умножения и сложения (вычитания).
| + | <math>t_{print}</math> - номер кванта времени, после которого прекращается вывод результатов; |
| | | | |
| − | == Информационный граф ==
| + | <math>rmin, rmax</math> - краевые значения параметров; |
| − | Это очень важный раздел описания. Именно здесь можно показать (увидеть) как устроена параллельная структура алгоритма, для чего приводится описание и изображение его информационного графа ([[глоссарий#Граф алгоритма|''графа алгоритма'']] <ref name="VVVVVV">Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. - СПб.: БХВ-Петербург, 2002. - 608 с. </ref>). Для рисунков с изображением графа будут составлены рекомендации по их формированию, чтобы все информационные графы, внесенные в энциклопедию, можно было бы воспринимать и интерпретировать одинаково. Дополнительно можно привести полное параметрическое описание графа в терминах покрывающих функций <ref name="VVVVVV" />.
| + | |
| | + | Функция, описывающая поведение системы. |
| | + | |
| | + | Выходные данные: |
| | | | |
| − | Интересных вариантов для отражения информационной структуры алгоритмов много. Для каких-то алгоритмов нужно показать максимально подробную структуру, а иногда важнее макроструктура. Много информации несут разного рода проекции информационного графа, выделяя его регулярные составляющие и одновременно скрывая несущественные детали. Иногда оказывается полезным показать последовательность в изменении графа при изменении значений внешних переменных (например, размеров матриц): мы часто ожидаем "подобное" изменение информационного графа, но это изменение не всегда очевидно на практике.
| + | Наборы, представляющие собой состояние системы и соответствующие значения параметров. |
| | | | |
| − | В целом, задача изображения графа алгоритма весьма нетривиальна. Начнем с того, что это потенциально бесконечный граф, число вершин и дуг которого определяется значениями внешних переменных, а они могут быть весьма и весьма велики. В такой ситуации, как правило, спасают упомянутые выше соображения подобия, делающие графы для разных значений внешних переменных "похожими": почти всегда достаточно привести лишь один граф небольшого размера, добавив, что графы для остальных значений будут устроены "точно также". На практике, увы, не всегда все так просто, и здесь нужно быть аккуратным.
| + | == Свойства алгоритма == |
| | | | |
| − | Далее, граф алгоритма - это потенциально многомерный объект. Наиболее естественная система координат для размещения вершин и дуг информационного графа опирается на структуру вложенности циклов в реализации алгоритма. Если глубина вложенности циклов не превышает трех, то и граф размещается в привычном трехмерном пространстве, однако для более сложных циклических конструкций с глубиной вложенности 4 и больше необходимы специальные методы представления и изображения графов.
| + | = Программная реализация алгоритма = |
| | | | |
| − | В данном разделе AlgoWiki могут использоваться многие интересные возможности, которые еще подлежат обсуждению: возможность повернуть граф при его отображении на экране компьютера для выбора наиболее удобного угла обзора, разметка вершин по типу соответствующим им операций, отражение [[глоссарий#Ярусно-параллельная форма графа алгоритма|''ярусно-параллельной формы графа'']] и другие. Но в любом случае нужно не забывать главную задачу данного раздела - показать информационную структуру алгоритма так, чтобы стали понятны все его ключевые особенности, особенности параллельной структуры, особенности множеств дуг, участки регулярности и, напротив, участки с недерминированной структурой, зависящей от входных данных.
| + | Алгоритм реализован на C++ с использованием средств OpenMP. |
| | + | [https://github.com/vvprokopenko/bifurcation] - исходный код. |
| | | | |
| − | На рис.1 показана информационная структура алгоритма умножения матриц, на рис.2 - информационная структура одного из вариантов алгоритма решения систем линейных алгебраических уравнений с блочно-двухдиагональной матрицей.
| + | == Особенности реализации последовательного алгоритма == |
| | | | |
| − | [[file:Fig1.svg|thumb|center|300px|Рис.1. Информационная структура алгоритма умножения матриц]]
| + | == Локальность данных и вычислений == |
| − | [[file:Fig2.svg|thumb|center|300px|Рис.2. Информационная структура одного из вариантов алгоритма решения систем линейных алгебраических уравнений с блочно-двухдиагональной матрицей]]
| |
| | | | |
| − | == Ресурс параллелизма алгоритма == | + | == Возможные способы и особенности параллельной реализации алгоритма == |
| − | Здесь приводится оценка [[глоссарий#Параллельная сложность|''параллельной сложности'']] алгоритма: числа шагов, за которое можно выполнить данный алгоритм в предположении доступности неограниченного числа необходимых процессоров (функциональных устройств, вычислительных узлов, ядер и т.п.). Параллельная сложность алгоритма понимается как высота канонической ярусно-параллельной формы <ref name="VVVVVV" />. Необходимо указать, в терминах каких операций дается оценка. Необходимо описать сбалансированность параллельных шагов по числу и типу операций, что определяется шириной ярусов канонической ярусно-параллельной формы и составом операций на ярусах.
| + | |
| | + | == Масштабируемость алгоритма и его реализации == |
| | | | |
| − | Параллелизм в алгоритме часто имеет естественную иерархическую структуру. Этот факт очень полезен на практике, и его необходимо отразить в описании. Как правило, подобная иерархическая структура параллелизма хорошо отражается в последовательной реализации алгоритма через циклический профиль результирующей программы (конечно же, с учетом графа вызовов), поэтому циклический профиль ([[#Описание схемы реализации последовательного алгоритма|п.1.5]]) вполне может быть использован и для отражения ресурса параллелизма.
| + | === Масштабируемость алгоритма === |
| | | | |
| − | Для описания ресурса параллелизма алгоритма (ресурса параллелизма информационного графа) необходимо указать ключевые параллельные ветви в терминах [[глоссарий#Конечный параллелизм|''конечного'']] и [[глоссарий#Массовый параллелизм|''массового'']] параллелизма. Далеко не всегда ресурс параллелизма выражается просто, например, через [[глоссарий#Кооодинатный параллелизм|''координатный параллелизм'']] или, что то же самое, через независимость итераций некоторых циклов (да-да-да, циклы - это понятие, возникающее лишь на этапе реализации, но здесь все так связано… В данном случае, координатный параллелизм означает, что информационно независимые вершины лежат на гиперплоскостях, перпендикулярных одной из координатных осей). С этой точки зрения, не менее важен и ресурс [[глоссарий#Скошенный параллелизм|''скошенного параллелизма'']]. В отличие от координатного параллелизма, скошенный параллелизм намного сложнее использовать на практике, но знать о нем необходимо, поскольку иногда других вариантов и не остается: нужно оценить потенциал алгоритма, и лишь после этого, взвесив все альтернативы, принимать решение о конкретной параллельной реализации. Хорошей иллюстрацией может служить алгоритм, структура которого показана на рис.2: координатного параллелизма нет, но есть параллелизм скошенный, использование которого снижает сложность алгоритма с <math>n\times m</math> в последовательном случае до <math>(n+m-1)</math> в параллельном варианте.
| + | Рассматривается система <math>u_t = ru_{t - 1}(1 - u_{t-1}), u_0 = u^0</math> на области изменения параметра <math>0\leqslant r \leqslant 4</math>, на сетке 1024 узла, система стабилизируется на 900 кванте времени, расчет и вывод останавливается на 1000 кванте времени. |
| | | | |
| − | Рассмотрим алгоритмы, последовательная сложность которых уже оценивалась в [[#Последовательная сложность алгоритма|п.1.6]]. Параллельная сложность алгоритма суммирования элементов вектора сдваиванием равна <math>\log_2n</math>, причем число операций на каждом ярусе убывает с <math>n/2</math> до <math>1</math>. Параллельная сложность быстрого преобразования Фурье (базовый алгоритм Кули-Тьюки) для векторов с длиной, равной степени двойки - <math>\log_2n</math>. Параллельная сложность базового алгоритма разложения Холецкого (точечный вариант для плотной симметричной и положительно-определенной матрицы) это <math>n</math> шагов для вычислений квадратного корня, <math>(n-1)</math> шагов для операций деления и <math>(n-1)</math> шагов для операций умножения и сложения.
| + | {| class="wikitable" |
| | + | |- |
| | + | ! Число процессов |
| | + | ! Время (с) |
| | + | |- |
| | + | |128 |
| | + | |0.234 |
| | + | |- |
| | + | |64 |
| | + | |0.24 |
| | + | |- |
| | + | |32 |
| | + | |0.248 |
| | + | |- |
| | + | |16 |
| | + | |0.254 |
| | + | |- |
| | + | |8 |
| | + | |0.272 |
| | + | |- |
| | + | |4 |
| | + | |0.29 |
| | + | |- |
| | + | |2 |
| | + | |0.323 |
| | + | |- |
| | + | |1 |
| | + | |0.34 |
| | + | |- |
| | + | |} |
| | | | |
| − | == Входные и выходные данные алгоритма ==
| + | Очевидно, что система плохо масштабируема за счет того, что вывод результатов довольно трудоемкий, но осуществлять его приходится часто. |
| − | В данном разделе необходимо описать объем, структуру, особенности и свойства входных и выходных данных алгоритма: векторы, матрицы, скаляры, множества, плотные или разреженные структуры данных, их объем. Полезны предположения относительно диапазона значений или структуры, например, диагональное преобладание в структуре входных матриц, соотношение между размером матриц по отдельным размерностям, большое число матриц очень малой размерности, близость каких-то значений к машинному нулю, характер разреженности матриц и другие.
| |
| | | | |
| − | == Свойства алгоритма == | + | === Характеристики программно-аппаратной среды === |
| − | Описываются прочие свойства алгоритма, на которые имеет смысл обратить внимание на этапе реализации. Как и ранее, никакой привязки к конкретной программно-аппаратной платформе не предполагается, однако вопросы реализации в проекте AlgoWiki всегда превалируют, и необходимость обсуждения каких-либо свойств алгоритмов определяется именно этим.
| |
| | | | |
| − | Весьма полезным является ''соотношение последовательной и параллельной сложности'' алгоритма. Оба понятия мы рассматривали ранее, но здесь делается акцент на том выигрыше, который теоретически может дать параллельная реализация алгоритма. Не менее важно описать и те сложности, которые могут возникнуть в процессе получения параллельной версии алгоритма.
| + | Все вычисления были произведены на суперкомпьютере "Ломоносов". |
| | | | |
| − | [[глоссарий#Вычислительная мощность|''Вычислительная мощность'']] алгоритма равна отношению числа операций к суммарному объему входных и выходных данных. Она показывает, сколько операций приходится на единицу переданных данных. Несмотря на простоту данного понятия, это значение исключительно полезно на практике: чем выше вычислительная мощность, тем меньше накладных расходов вызывает перемещение данных для их обработки, например, на сопроцессоре, ускорителе или другом узле кластера. Например, вычислительная мощность скалярного произведения двух векторов равна всего лишь <math>1</math>, а вычислительная мощность алгоритма умножения двух квадратных матриц равна <math>2n/3</math>.
| + | Для компиляции был использован компилятор языка C++ GNU 4.4.6 с ключом -fopenmp. |
| | | | |
| − | Вопрос первостепенной важности на последующем этапе реализации - это [[глоссарий#Устойчивость|''устойчивость'']] алгоритма. Все, что касается различных сторон этого понятия, в частности, оценки устойчивости, должно быть описано в данном разделе.
| + | Вычисления производились в очередях regular4 и test. Ограничений на лимит времени и число процессов на узел наложено не было. |
| | | | |
| − | ''Сбалансированность'' вычислительного процесса можно рассматривать с разных сторон. Здесь и сбалансированность типов операций, в частности, арифметических операций между собой (сложение, умножение, деление) или же арифметических операций по отношению к операциям обращения к памяти (чтение/запись). Здесь и сбалансированность операций между параллельными ветвями алгоритма. С одной стороны, балансировка нагрузки является необходимым условием эффективной реализации алгоритма. Вместе с этим, это очень непростая задача, и в описании должно быть отмечено явно, насколько алгоритм обладает этой особенностью. Если обеспечение сбалансированности не очевидно, желательно описать возможные пути решения этой задачи.
| + | В программе использована библиотека iostream для вывода точек бифуркационной диаграммы, а так же подключен заголовочный файл omp.h для обеспечения доступа к средствам OpenMP. |
| | | | |
| − | На практике важна [[глоссарий#Детерминированность|''детерминированность алгоритмов'']], под которой будем понимать постоянство структуры вычислительного процесса. С этой точки зрения, классическое умножение плотных матриц является детерминированным алгоритмом, поскольку его структура при фиксированном размере матриц никак не зависит от элементов входных матриц. Умножение разреженных матриц, когда матрица хранятся в одном из специальных форматов, свойством детерминированности уже не обладает: его свойства, например, степень локальности данных зависит от структуры разреженности входных матриц. Итерационный алгоритм с выходом по точности также не является детерминированным: число итераций, а значит и число операций, меняется в зависимости от входных данных. В этом же ряду стоит использование датчиков случайных чисел, меняющих вычислительный процесс для различных запусков программы. Причина выделения свойства детерминированности понятна: работать с детерминированным алгоритмом проще, поскольку один раз найденная структура и будет определять качество его реализации. Если детерминированность нарушается, то это должно быть здесь описано вместе с описанием того, как недетерминированность влияет на структуру вычислительного процесса.
| + | == Динамические характеристики и эффективность реализации алгоритма == |
| | | | |
| − | Серьезной причиной недетерминированности работы параллельных программ является изменение порядка выполнения ассоциативных операций. Типичный пример - это использование глобальных MPI-операций на множестве параллельных процессов, например, суммирование элементов распределенного массива. Система времени исполнения MPI сама выбирает порядок выполнения операций, предполагая выполнение свойства ассоциативности, из-за чего ошибки округления меняются от запуска программы к запуску, внося изменения в конечный результат ее работы. Это очень серьезная проблема, которая сегодня встречается часто на системах с массовым параллелизмом и определяет отсутствие повторяемости результатов работы параллельных программ. Данная особенность характерна для [[#ЧАСТЬ. Программная реализация алгоритмов|второй части AlgoWiki]], посвященной реализации алгоритмов, но вопрос очень важный, и соответствующие соображения, по возможности, должны быть отмечены и здесь.
| + | == Выводы для классов архитектур == |
| | | | |
| − | Заметим, что, в некоторых случаях, недетерминированность в структуре алгоритмов можно "убрать" введением соответствующих макроопераций, после чего структура становится не только детерминированной, но и более понятной для восприятия. Подобное действие также следует отразить в данном разделе.
| + | == Существующие реализации алгоритма == |
| | + | Последовательные реализации: |
| | | | |
| − | [[глоссарий#Степень исхода|''Степень исхода вершины информационного графа'']] показывает, в скольких операциях ее результат будет использоваться в качестве аргумента. Если степень исхода вершины велика, то на этапе реализации алгоритма нужно позаботиться об эффективном доступе к результату ее работы. В этом смысле, особый интерес представляют рассылки данных, когда результат выполнения одной операции используется во многих других вершинах графа, причем число таких вершин растет с увеличением значения внешних переменных. | + | [http://www.physics.sfsu.edu/~mstevens/chaos/bifur2.htm] - построение бифуркационной диаграммы для хаотического маятника. |
| | | | |
| − | ''"Длинные" дуги в информационном графе'' <ref name="VVVVVV" /> говорят о потенциальных сложностях с размещением данных в иерархии памяти компьютера на этапе выполнения программы. С одной стороны, длина дуги зависит от выбора конкретной системы координат, в которой расположены вершины графа, а потому в другой системе координат они попросту могут исчезнуть (но не появится ли одновременно других длинных дуг?). А с другой стороны, вне зависимости от системы координат их присутствие может быть сигналом о необходимости длительного хранения данных на определенном уровне иерархии, что накладывает дополнительные ограничения на эффективность реализации алгоритма. Одной из причин возникновения длинных дуг являются рассылки скалярных величин по всем итерациям какого-либо цикла: в таком виде длинные дуги не вызывают каких-либо серьезных проблем на практике.
| + | [https://www.math.utah.edu/~jasonu/code/] - построение бифуркационной диаграммы логистического отображения. |
| | | | |
| − | Для проектирования специализированных процессоров или реализации алгоритма на ПЛИС представляют интерес ''компактные укладки информационного графа'' <ref name="VVVVVV" />, которые также имеет смысл привести в данном разделе.
| + | = Литература = |
| | + | Братусь А.С., Новожилов А.С., Семенов Ю.С. "Динамические системы и модели биологии" |
1 Свойства и структура алгоритма
1.1 Общее описание алгоритма
Алгоритм предназначен для графического изображения смены возможных динамических режимов системы при изменении значений бифуркационных параметров.
1.2 Математическое описание алгоритма
Рассматривается динамическая система: [math]u_{t+1} = f(u_t, \ldots, u_{t - k}, r_0, \ldots, r_l), u_0 = u^0 = const, \ldots, u_k = u^k = const, r_0 = const \gt 0, \ldots, r_l = const \gt 0[/math]. Для построения бифуркационной диаграммы системы необходимо:
1. Выбрать подпространство значений параметров, на котором будет рассматриваться поведение системы.
2. Для каждого набора значений параметров вычислить [math]N[/math] последовательных состояний системы, начиная с начального состояния, где [math]N[/math] - достаточно большое число квантов времени. Этот шаг выполняется для стабилизации системы, в случае если для данного значения параметров система не ведет себя хаотично (имеет устойчивую точку, цикл, аттрактор и т.п.).
3. Вычислить еще [math]K[/math] состояний системы, начиная с [math]N[/math]-го состояния и вывести соответствующие результаты вместе со значениями параметров в файл. Чем больше число [math]K[/math], тем точнее будет бифуркационная диаграмма.
4. Отобразить полученные результаты графически.
1.3 Вычислительное ядро алгоритма
Вычислительным ядром алгоритма является цикл прохода по сетке рассматриваемых значений параметров. На каждой итерации внешнего цикла проходятся два цикла, последовательно вычисляющие последующие состояния системы на основании рассматриваемых значений параметров и необходимого количества предыдущих состояний системы. В первом цикле рассчитываются [math]N[/math] состояний системы без вывода полученных данных, где [math]N[/math] — достаточно большое число итераций, необходимое для того, чтобы система стабилизировалась. Во втором цикле рассчитываются следующие [math]K[/math] состояний системы, полученные значения выводятся. Здесь [math]K[/math] задается исходя из желаемого качества отображения бифуркационной диаграммы.
1.4 Макроструктура алгоритма
Как уже сказано в описании ядра алгоритма, основную часть метода составляют вычисления состояний системы в зависимости от значений параметров и характерного для рассматриваемой системы числа предыдущих состояний.
1.5 Схема реализации последовательного алгоритма
Рассмотрим фрагмент реализации алгоритма на c++ для системы [math]u_t = ru_{t - 1}(1 - u_{t-1}), u_0 = u^0[/math] на области изменения параметра [math]0\leqslant r \leqslant 4[/math].
double system_func(double u0, double r) //задаем систему
{
return r*u0*(1 - u0);
}
int main()
{
int t_stabilize = 900; //номер кванта времени, после которого считаем, что система стабильна
int t_print = 1000; //номер кванта времени, на котором преращаем вывод полученных точек для системы при конкретном значении параметра
double rmin = 0; //минимальное рассматриваемое значение параметра
double rmax = 4; //максимальное рассматриваемое значение параметра
double r;
double u0;
int N = 1024;
double coef = (rmax - rmin)/N; //расчет шага сетки
int i;
double t;
double u;
for (i = 1; i <= N; i++)
{
r = rmin + coef*i; //взятие нового значения параметра на сетке
u0 = 0.1; //взятие начального состояния системы
u = u0;
for (t = 1; t <= t_stabilize; t++) //расчет последовательных состояний системы до момента стабилизации
{
u = system_func(u0, r); //расчет следующего состояния системы
u0 = u; //фиксация предыдущего состояния системы для следующей итерации
}
for (t = t_stabilize + 1; t <= t_print; t++) //расчет заданного количества состояний системы после момент стабилизации для вывода
{
u = system_func(u0, r);
cout << r << ' ' << u << end; //вывод значения параметра и состояния системы для последующей визуализации
u0 = u;
}
}
}
1.6 Последовательная сложность алгоритма
Рассмотрим сложность последовательной реализации ядра алгоритма в терминах арифметических операций: сложений/вычитаний и умножений/делений.
Пусть на сетке значений параметра [math]P[/math] узлов, система стабилизируется за [math]N[/math] квантов времени, выводится [math]K[/math] состояний системы. Пусть для вычисления следующего значения функции нужно привести [math]m[/math] умножений/делений и [math]a[/math] сложений/вычитаний. Тогда сложность последовательной реализации составляет [math]P(1 +(N + K)m)[/math] умножений/делений и [math]P(1 + (N + K)a)[/math] сложений/вычитаний.
1.7 Информационный граф
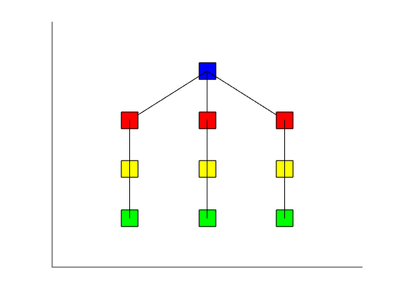
Синим цветом обозначен блок инициализации начальных условий (например, шага сетки), красным - взятие текущего значения параметров на сетке, желтым - блок стабилизации системы (проход первого внутреннего цикла), зеленым - расчет последующих состояний системы с выводом (проход второго внутреннего цикла).
1.8 Ресурс параллелизма алгоритма
Ресурс параллелизма алгоритма заключается в информационной независимости итераций внешнего цикла. Таким образом можно разделить внешний цикл по значениям параметра на разные процессы.
1.9 Входные и выходные данные алгоритма
Входные данные:
[math]N[/math] - количество узлов сетки значений параметров;
[math]t_{stabilize}[/math] - номер кванта времени, после которого считаем систему стабильной;
[math]t_{print}[/math] - номер кванта времени, после которого прекращается вывод результатов;
[math]rmin, rmax[/math] - краевые значения параметров;
Функция, описывающая поведение системы.
Выходные данные:
Наборы, представляющие собой состояние системы и соответствующие значения параметров.
1.10 Свойства алгоритма
2 Программная реализация алгоритма
Алгоритм реализован на C++ с использованием средств OpenMP.
[1] - исходный код.
2.1 Особенности реализации последовательного алгоритма
2.2 Локальность данных и вычислений
2.3 Возможные способы и особенности параллельной реализации алгоритма
2.4 Масштабируемость алгоритма и его реализации
2.4.1 Масштабируемость алгоритма
Рассматривается система [math]u_t = ru_{t - 1}(1 - u_{t-1}), u_0 = u^0[/math] на области изменения параметра [math]0\leqslant r \leqslant 4[/math], на сетке 1024 узла, система стабилизируется на 900 кванте времени, расчет и вывод останавливается на 1000 кванте времени.
| Число процессов
|
Время (с)
|
| 128
|
0.234
|
| 64
|
0.24
|
| 32
|
0.248
|
| 16
|
0.254
|
| 8
|
0.272
|
| 4
|
0.29
|
| 2
|
0.323
|
| 1
|
0.34
|
Очевидно, что система плохо масштабируема за счет того, что вывод результатов довольно трудоемкий, но осуществлять его приходится часто.
2.4.2 Характеристики программно-аппаратной среды
Все вычисления были произведены на суперкомпьютере "Ломоносов".
Для компиляции был использован компилятор языка C++ GNU 4.4.6 с ключом -fopenmp.
Вычисления производились в очередях regular4 и test. Ограничений на лимит времени и число процессов на узел наложено не было.
В программе использована библиотека iostream для вывода точек бифуркационной диаграммы, а так же подключен заголовочный файл omp.h для обеспечения доступа к средствам OpenMP.
2.5 Динамические характеристики и эффективность реализации алгоритма
2.6 Выводы для классов архитектур
2.7 Существующие реализации алгоритма
Последовательные реализации:
[2] - построение бифуркационной диаграммы для хаотического маятника.
[3] - построение бифуркационной диаграммы логистического отображения.
3 Литература
Братусь А.С., Новожилов А.С., Семенов Ю.С. "Динамические системы и модели биологии"
