Участница:Эльвира Ахиярова/Итерационный метод решения системы линейных алгебраических уравнений GMRES (обобщенный метод минимальных невязок): различия между версиями
| Строка 157: | Строка 157: | ||
Граф алгоритма умножения плотной матрицы на вектор состоит из одной группы вершин, расположенной в целочисленных узлах двумерной области, соответствующая ей операция <math>a+bc</math>. | Граф алгоритма умножения плотной матрицы на вектор состоит из одной группы вершин, расположенной в целочисленных узлах двумерной области, соответствующая ей операция <math>a+bc</math>. | ||
| − | Описанный граф выполнен для случая <math>m = 4, n = 5</math>. | + | Описанный граф выполнен для случая <math>m = 4, n = 5</math>. Изображена подача только входных данных из вектора <math>x</math>, подача элементов матрицы <math>A</math>, идущая во все вершины, на рисунке не представлена. |
| − | Граф алгоритма нахождения скалярного произведения двух векторов состоит из двух групп вершин | + | Граф алгоритма нахождения скалярного произведения двух векторов состоит из двух групп вершин, им соответсвуют операции <math>a*b, \quad c+d</math>. Данный граф изображен для случая <math>n = 24</math>. |
=== Ресурс параллелизма алгоритма === | === Ресурс параллелизма алгоритма === | ||
Версия 15:24, 24 ноября 2016
| Обобщеннный метод минимальных невязок | |
| Последовательный алгоритм | |
| Последовательная сложность | O(mn+m^2+n^2) |
| Объём входных данных | n^2+n+1 |
| Объём выходных данных | n |
Основные авторы описания: Э.А.Ахиярова
Содержание
- 1 Свойства и структура алгоритма
- 1.1 Общее описание алгоритма
- 1.2 Математическое описание алгоритма
- 1.3 Вычислительное ядро алгоритма
- 1.4 Макроструктура алгоритма
- 1.5 Схема реализации последовательного алгоритма
- 1.6 Последовательная сложность алгоритма
- 1.7 Информационный граф
- 1.8 Ресурс параллелизма алгоритма
- 1.9 Входные и выходные данные алгоритма
- 1.10 Свойства алгоритма
- 2 Программная реализация алгоритма
- 2.1 Особенности реализации последовательного алгоритма
- 2.2 Локальность данных и вычислений
- 2.3 Возможные способы и особенности параллельной реализации алгоритма
- 2.4 Масштабируемость алгоритма и его реализации
- 2.5 Динамические характеристики и эффективность реализации алгоритма
- 2.6 Выводы для классов архитектур
- 2.7 Существующие реализации алгоритма
- 3 Литература
1 Свойства и структура алгоритма
1.1 Общее описание алгоритма
Обобщенный метод минимальных невязок (GMRES) - это итерационный метод для нахождения приближенного решения системы линейных алгебраических уравнений Ax = b с произвольной матрицей A. Алгоритм был преложен в 1986 году Йозефом Саадом и Мартином Г. Шульцем [1].
В то время как применение классических итерационных алгоритмов для решения СЛАУ ограничивается либо диагональным преобладанием, либо положительной определенностью матрицы, GMRES может быть использован для систем с произвольной невырожденной матрицей A. Данный метод опирается на итерации Арнольди для нахождения минимизирующего невязку вектора из подпространства Крылова [2].
Основным недостатком метода GMRES является поитерационное увеличение объема требуемой памяти. В связи с этим, для некоторых вычислительных систем выполенние программы метода может быть невозможным. Для некоторых систем используют модифицированный обобщенный метод минимальных невязок - GMRES(m), который подразумевает использование рестартов, существенно сокращающих объемы необходимой памяти.
Ключевая идея обобщенного метода минимальных невязок основана на решении задачи наименьших квадратов на каждом итерационном шаге. На каждом k-м шаге точное решение x^* = A^{-1}b аппроксимируется вектором x_k \in K_k, таким образом, что:
- \|r_k{\|}_2 = \|Ax_k-b{\|}_2 \to \min ,
где K_k - подпространство Крылова k - го порядка.
1.2 Математическое описание алгоритма
Исходные данные: Матрица A \in R^{n\times n}, вектор правой части b \in R^n.
Вычисляемые данные: Приближенное решение \tilde{x} \in R^n системы Ax = b.
На каждом k-м шаге метода решение x_k рассматривается в виде x_0+Vy_k, где столбцы v_k матрицы V находятся с помощью процесса Арнольди для построения ортонормированного базиса \{v_1, v_2, \dots, v_k\} подпространства Крылова K_k(A, v_1), вектор y_k представляет собой решение системы H_ky_k = \beta_k e_1, где H_k - верхняя матрица Хессенберга[3] размера k\times k, элементы которой формируются в процессе ортогонализации Арнольди, \beta_k = \|r_0{\|}_2, \ r_0 = b - Ax_0 , и, наконец, e_1 - канонический вектор {\begin{pmatrix}1&0&\dots 0\end{pmatrix}}^T размерности k
Рассмотрим подробнее процесс ортогонализации Арнольди:
1.2.1 Процесс Арнольди
Исходные данные: начальный ортонормированный вектор v_1 и размерность k
Вычисляемые данные: Ортонормированный базис \{v_1, v_2, \dots, v_k\} подпространства K_k(A, v_1)
Формулы метода:
- \begin{align} &\omega = Av_j \\ &h_{ij} = (\omega, v_i) \\ &\omega = \omega - h_{ij}v_i \\ &h_{(i+1)j} = \|\omega\| \\ &v_{j+1} = \frac{\omega}{h_{(i+1)j}} \\ &j = \overline{1,k}, \ i = \overline{1,j} \end{align}
В результате выполнения процесса Арнольди получаем:
- V_k =\{v_1, v_2, \dots, v_k\} - ортонормированный базис подпространства Крылова
- \overline{V_k} = \{v_1, v_2, \dots, v_k, v_{k+1}\} - матрица, расширенная последним вычисленным вектором v_{k+1}
- H_k - верхняя Хессенбергова матрица, элементы которой равны коэффициентам ортогонализации:
- H_k = \begin{pmatrix} h_{11} & h_{12} & h_{13} & h_{14} & \dots & h_{1k} \\ h_{21} & h_{22} & h_{23} & h_{24} & \dots & h_{2k} \\ 0 & h_{32} & h_{33} & h_{34} & \dots & h_{3k} \\ \vdots & &\ddots & \ddots & & \vdots \\ 0 & \dots & 0 & h_{k-1,k-2}& h_{k-1, k-1} & h_{k-1, k} \\ 0 & \dots & 0 & 0 & h_{k, k-1} & h_{k, k} \\ 0 & \dots & & & 0& h_{k+1, k} \end{pmatrix}
1.2.2 Минимизация нормы невязки
Выполнив несложные преобразования можно получить выражение для невязки на k- й итерации:
- r_k = \beta e_1 - H_ky_k
Очевидно, что для задачи
- \|r_k{\|}_2 \to \min
минимум достигается при
- H_ky_k = \beta e_1
Для решения последней системы матрица H_k приводится к верхнему треугольному виду с помощью k вращений Гивенса:
- R_k = \Omega_k\Omega_{k-1}\dots \Omega_1 ,
- \Omega_i = \begin{pmatrix} 1 & &&&&&& \\ &\ddots &&&&&&\\ &&1&&&&& \\ &&&c_i&s_i &&& \\ &&&-s_i& c_i &&&\\ &&&&&1&&& \\ &&&&&&\ddots&\\ &&&&&&&1 \\ \end{pmatrix}, \quad s_i = \frac{h_{i+1,i}}{\sqrt{h_{ii}^2+h_{i+1,i}^2}}, \quad c_i = \frac{h_{ii}}{\sqrt{h_{ii}^2+h_{i+1,i}^2}}
1.3 Вычислительное ядро алгоритма
Вычислительное ядро последовательной версии метода GMRES состоит из вычислений произведений матрицы на вектор и скалярного произведения в процессе Арнольди и произведений матрицы на вектор, обращений верхней треугольной матрицы для нахождения решения задачи минимизации невязки.
1.4 Макроструктура алгоритма
В методе используются следующие макрооперции:
- Умножение матрицы на вектор
- Вычисление скалярного произведение двух векторов
- Нахождени l_2-нормы вектора
- Умножение матриц специальной структуры
- Решение системы уравнений с верхней треугольной матрицей
1.5 Схема реализации последовательного алгоритма
Для обобщенного метода мимнимальных невязок число векторов порядка n, которых необходимо хранить в памяти, растет линейно с ростом k, в то время как число умножений имеет квадратичную зависимость от числа итераций. Этот факт является мотивацией для того, чтобы использовать метод минимальных невязок с рестартами. Вместо того, чтобы формировать базис размерности k, выбирается параметр m \lt \lt n и с помощью ортонормированного базиса размерности m строится приближенное решение. Посредством такой схемы необходимое количество памяти может быть оценено заранее и оставаться внутри определенных пределов. Приведем подробное описание алгоритма GMRES c рестартами:
1. k = 0 ; инициализировать x_0; r_0=b-Ax_0 и v_1=\frac{r_0}{\|r_0 \|}
2. Выполнить m шагов процессса Арнольди:
Для [math] j = \overline{1,m} [/math] выполнять: [math] \omega = Av_j [/math] Для [math] i = \overline{1,j} [/math] выполнять: [math] \begin{align} &h_{ij} = (\omega, v_i) \\ &\omega = \omega - h_{ij}v_i \\ \end{align} [/math] [math] \begin{align} h_{(i+1)j} = \|\omega\| \\ v_{j+1} = \frac{\omega}{h_{(i+1)j}} \\ \end{align} [/math]
3. Вычислить y_m=\arg\min_{y} \| \beta e_1 - H_m y \|,\ y \in \R^m и x_m=x_0+V_my_m
4. Вычислить r_m=b-Ax_m. Если требуемая точность достигнута, остановиться
5. Рестарт:
[math]x_0 = x_m[/math] [math]r_m = \frac{r_m}{\|r_m\|}[/math] Перейти к шагу 2.
1.6 Последовательная сложность алгоритма
Вычислительная сложность метода GMRES складывается из сложности решения задачи минимизации невязки и сложности процесса Арнольди. Так как в задаче минимизации невязки матрица системы имеет размер m+1 \times m, для нахождения решения требуется O(m^2) операций. Процесс Арнольди предполагает выполнение O(mn) операций плюс O(n^2) операций для умножений матрицы на вектор.
1.7 Информационный граф
Основным ресурсом параллелизма будут являться умножение матрицы на вектор[4] и вычисление скалярных произведений[5]. Представим информационные графы для данных алгоритмов:
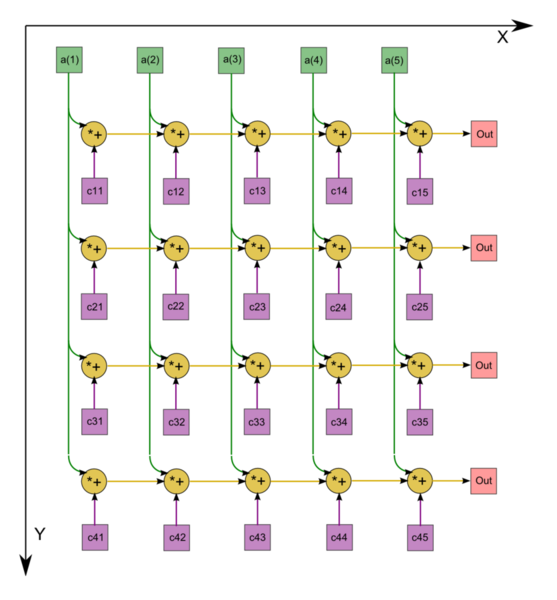
Рисунок 1. Граф последовательного умножения плотной матрицы на вектор с отображением входных и выходных данных
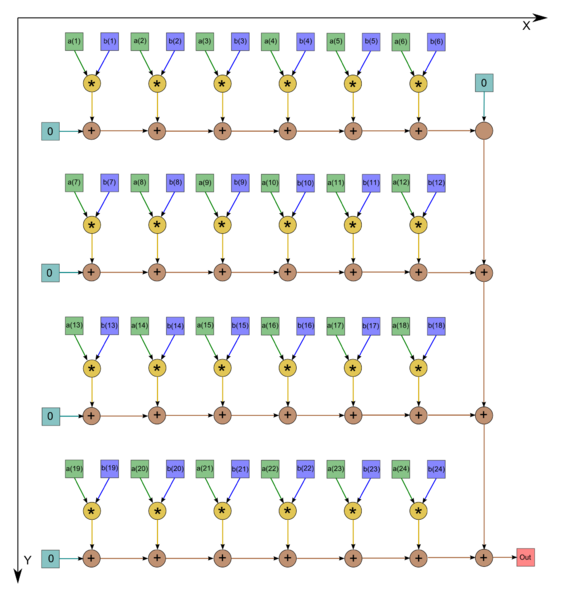
Рисунок 2. Последовательно-параллельное вычисление скалярного произведения


Граф алгоритма умножения плотной матрицы на вектор состоит из одной группы вершин, расположенной в целочисленных узлах двумерной области, соответствующая ей операция a+bc.
Описанный граф выполнен для случая m = 4, n = 5. Изображена подача только входных данных из вектора x, подача элементов матрицы A, идущая во все вершины, на рисунке не представлена.
Граф алгоритма нахождения скалярного произведения двух векторов состоит из двух групп вершин, им соответсвуют операции a*b, \quad c+d. Данный граф изображен для случая n = 24.
1.8 Ресурс параллелизма алгоритма
Для умножения квадратной матрицы на вектор порядка n в параллельном варианте требуется последовательно выполнить следующие ярусы:
- по n ярусов умножений и сложений (в каждом из ярусов — n операций).
Для умножения матрицы размером n строк на n столбцов на вектор порядка n в последовательном (наиболее быстром) варианте требуется:
- по n ярусов умножений и сложений (в каждом из ярусов — n операций).
При этом использование режима накопления требует совершения умножений и сложений в режиме двойной точности, а в параллельном варианте это означает, что практически все промежуточные вычисления для выполнения алгоритма в режиме накопления должны быть двойной точности. В отличие от последовательного варианта это означает некоторое увеличение требуемой памяти.
При классификации по высоте ЯПФ, таким образом, алгоритм умножения матрицы на вектор относится к алгоритмам с линейной сложностью. При классификации по ширине ЯПФ его сложность также будет линейной.
Для вычисления скалярного произведения векторов размерности n параллельном варианте требуется последовательно выполнить следующие ярусы:
- 1 ярус вычисления произведений,
- k - 1 ярусов суммирования по частям массивов (p ветвей),
- p - 1 ярусов суммирования (одна последовательная ветвь),
где p - количество процессоров, k- номер процессора.
Таким образом, в параллельном варианте критический путь алгоритма (и соответствующая ему высота ЯПФ) будет зависеть от произведённого разбиения массива на части. В оптимальном случае (p = \sqrt{n}) высота ЯПФ будет равна 2 \sqrt{n} - 1. При классификации по высоте ЯПФ, таким образом, последовательно-параллельный метод относится к алгоритмам со сложностью «корень квадратный». При классификации по ширине ЯПФ его сложность также будет «корень квадратный».
1.9 Входные и выходные данные алгоритма
Входные данные: Матрица A \in R^{n\times n}, вектор b \in R^n, точность \varepsilon. Объём: n^2 + n + 1
Выходные данные: Вектор x_m \in R^n. Объём: n
1.10 Свойства алгоритма
В точной арифметике GMRES всегда сходится не более чем за n итераций (т.к. K_n = R^n = Im(A)). При этом последовательность решений сходится монотонно, в связи с тем, что \|r_{m+1}\| \le \|r_m\|. Этот факт справедлив из-за того, что подпространства, по которым минимизируется \|r_m\|, вложены друг в друга: K_m \subset K_{m+1}. Таким образом, минимизация по подпрастранствам большей размерности приведет нас к меньшей норме невязки.
Скорость сходимости метода зависит от расположения собственных значений матрицы A на комплексной плоскости. Для быстрой сходимости, собственные значения должны быть сконцентрированны на достаточном расстоянии от начала координат. Заметим, что расположение собственных чисел намного важнее, чем число обусловленности матрицы A, являющимся главным критерием быстрой сходимости для метода сопряженных градиентов.
Если обобщенный метод минимальных невязок применяется к СЛАУ с матрицами, обладающими "хорошим" распределением собственных чисел, то он может работать быстрее чем стандартное LU разложение даже в том случае, если матрица плотна и неструктурированна.
2 Программная реализация алгоритма
2.1 Особенности реализации последовательного алгоритма
2.2 Локальность данных и вычислений
2.3 Возможные способы и особенности параллельной реализации алгоритма
2.4 Масштабируемость алгоритма и его реализации
2.5 Динамические характеристики и эффективность реализации алгоритма
2.6 Выводы для классов архитектур
2.7 Существующие реализации алгоритма
Реализации обобщенного метода минимальных невязок (GMRES) присутствуют во многих пакетах. Приведем некоторые из них:
3 Литература
[1] A parallel implementation of the restarted GMRES iterative algorithm for nonsymmetric systems of linear equations, Rudnei Dias da Cunha, Centro de Processamento de Dados, Universidade Federal do Rio Grande do Sul, Brazil and Computing Laboratory, University of Kent, Canterbury, UK and Tim Hopkins, Computing Laboratory, University of Kent, Canterbury, UK, 1993
[2] Gene H. Golub, Charles F. Van Loan, Matrix and Computations, 4th edition
- ↑ Y. Saad and M.H. Schultz, "GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems", SIAM J. Sci. Stat. Comput., 7:856-869, 1986. doi:10.1137/0907058.
- ↑ https://en.wikipedia.org/wiki/Krylov_subspace
- ↑ https://en.wikipedia.org/wiki/Hessenberg_matrix
- ↑ https://algowiki-project.org/ru/Умножение_плотной_неособенной_матрицы_на_вектор_(последовательный_вещественный_вариант)
- ↑ https://algowiki-project.org/ru/Скалярное_произведение_векторов,_вещественная_версия,_последовательно-параллельный_вариант