|
|
| (не показано 38 промежуточных версий 1 участника) |
| Строка 1: |
Строка 1: |
| | + | Автор: Абдулпотиев А.А. |
| | + | |
| | {{algorithm | | {{algorithm |
| − | | name = Разложение Холецкого | + | | name = Алгоритм Ланцоша для арифметики с плавающей точкой с выборочной ортогонализацией |
| − | | serial_complexity = <math>O(n^3)</math> | + | | serial_complexity = <math>O(kn^2 + k^2n)</math> |
| − | | pf_height = <math>O(n)</math> | + | | pf_height = <math>O(kn + k^2)</math> |
| − | | pf_width = <math>O(n^2)</math> | + | | pf_width = <math>O(n)</math> |
| − | | input_data = <math>\frac{n (n + 1)}{2}</math> | + | | input_data = <math>{n (n + 1) \over 2} + n + 1</math> |
| − | | output_data = <math>\frac{n (n + 1)}{2}</math> | + | | output_data = <math>k + nk</math> |
| | }} | | }} |
| | | | |
| − | Автор: [[Участник:Abdulpotiev|А.А. Абдулпотиев]]
| + | = Свойства и структура алгоритма = |
| − | == Свойства и структура алгоритма ==
| + | == Общее описание алгоритма == |
| | | | |
| − | === Общее описание алгоритма ===
| + | Алгоритм Ланцоша это итерационный метод нахождения небольшого количества собственных значений столь больших разреженных симметричных матриц, что к ним нельзя применить прямые методы. Иными словами алгоритм сильно оптимизирует использование памяти и вычислительной мощности, что является критически важным для больших вычислений. |
| | | | |
| − | '''Алгоритм Ланцоша''' впервые предложено французским офицером и математиком Андре-Луи Холецким в конце Первой Мировой войны, незадолго до его гибели в бою в августе 1918 г. Идея этого разложения была опубликована в 1924 г. его сослуживцем<ref>Commandant Benoit, Note sur une méthode de résolution des équations normales provenant de l'application de la méthode des moindres carrés à un système d'équations linéaires en nombre inférieur à celui des inconnues (Procédé du Commandant Cholesky), Bulletin Géodésique 2 (1924), 67-77.</ref>. Потом оно было использовано поляком Т. Банашевичем<ref>Banachiewicz T. Principles d'une nouvelle technique de la méthode des moindres carrês. Bull. Intern. Acad. Polon. Sci. A., 1938, 134-135.</ref><ref>Banachiewicz T. Méthode de résoltution numérique des équations linéaires, du calcul des déterminants et des inverses et de réduction des formes quardatiques. Bull. Intern. Acad. Polon. Sci. A., 1938, 393-401.</ref> в 1938 г. В советской математической литературе называется также методом квадратного корня<ref>Воеводин В.В. Вычислительные основы линейной алгебры. М.: Наука, 1977.</ref><ref>Воеводин В.В., Кузнецов Ю.А. Матрицы и вычисления. М.: Наука, 1984.</ref><ref>Фаддеев Д.К., Фаддева В.Н. Вычислительные основы линейной алгебры. М.-Л.: Физматгиз, 1963.</ref>; название связано с характерными операциями, отсутствующими в родственном разложении Гаусса.
| + | Сам алгоритм объединяет метод Ланцоша для построения крыловского подпространства с процедурой Рэлея-Ритца интерпретации собственных значений некоторой вычисляемой матрицы как приближений к собственным значениям исходной матрицы. |
| | | | |
| − | Первоначально разложение Холецкого использовалось исключительно для плотных симметричных положительно определенных матриц. В настоящее время его использование гораздо шире. Оно может быть применено также, например, к эрмитовым матрицам. Для повышения производительности вычислений часто применяется блочная версия разложения.
| + | Пусть <math>Q = [Q_k,Q_u]</math> - ортогональная матрица порядка <math>n</math>, причем <math>Q_k</math> и <math>Q_u</math> имеют соответственно размеры <math>n \times k</math> и <math>n \times (n-k)</math>. Столбцы матрицы <math>Q_k</math> вычисляются методом Ланцоша.. |
| | | | |
| − | Для разреженных матриц разложение Холецкого также широко применяется в качестве основного этапа прямого метода решения линейных систем. В этом случае используют специальные упорядочивания для уменьшения ширины профиля исключения, а следовательно и уменьшения количества арифметических операций. Другие упорядочивания используются для выделения независимых блоков вычислений при работе на системах с параллельной организацией.
| + | Запишем следующие соотношения: |
| | | | |
| − | Варианты разложения Холецкого нашли успешные применения и в итерационных методах для построения переобусловливателей разреженных симметричных положительно определенных матриц. В неполном треугольном разложении («по позициям») элементы переобусловливателя вычисляются только в заранее заданных позициях, например, в позициях ненулевых элементов исходной матрицы (так называемое разложение IC0). Для получения же более точного разложения применяется приближение, в котором фильтрация малых элементов производится «по значениям». В зависимости от используемого порога фильтрации можно получить более точное, но и более заполненное разложение. Существует и алгоритм разложения второго порядка точности<ref>Kaporin I.E. High quality preconditioning of a general symmetric positive definite matrix based on its UTU + UTR + RTU-decomposition. Numer. Lin. Algebra Appl. (1998) Vol. 5, No. 6, 483-509.</ref>. В нём при таком же заполнении множителей разложения удается улучшить точность. Для такого разложения в параллельном режиме используется специальный вариант аддитивного переобуславливания на основе разложения второго порядка<ref>Капорин И.Е., Коньшин И.Н. Параллельное решение симметричных положительно-определенных систем на основе перекрывающегося разбиения на блоки. Ж. вычисл. матем. и матем. физ., 2001, Т, 41, N. 4, C. 515–528.</ref>.
| + | <math>T = Q^T A Q = [Q_k, Q_u]^T A [Q_k, Q_u] = |
| | + | \left[ \begin{array}{cc} |
| | + | Q_k^T A Q_k & Q_k^T A Q_u\\ |
| | + | Q_u^T A Q_k & Q_u^T A Q_u |
| | + | \end{array} \right] |
| | + | = \left[ \begin{array}{cc} |
| | + | T_{k} & T_{ku}^T\\ |
| | + | T_{ku} & T_{u} |
| | + | \end{array} \right]</math> |
| | | | |
| − | На этой странице представлено исходное разложение Холецкого с новых позиций нашего суперкомпьютерного века. Приведено описание конкретной версии разложения Холецкого — для плотных вещественных симметричных положительно определённых матриц, но структура для ряда других версий, например, для комплексного случая, почти такая же, различия состоят в замене большинства вещественных операций на комплексные. Список остальных основных вариантов разложения можно посмотреть на странице [[Метод Холецкого (нахождение симметричного треугольного разложения)]].
| + | Метод Рэлея-Ритца заключается в интерпретации собственных значений матрицы <math>T_k = Q_k^T A Q_k</math> как приближенных к собственным значениям матрицы <math>A</math>. Эти приближения называются числами Ритца. Если <math>A = V \Lambda V^T</math> есть спектральное разложение матрицы <math>T_k</math>, то столбцы матрицы <math>Q_k V</math> являются приближениями соответствующих собственных векторов и называются векторами Ритца. |
| | | | |
| − | Используется для разложения положительно определённых эрмитовых (''в вещественном случае - симметрических'') матриц в виде <math>A = L L^*</math>, <math>L</math> — нижняя треугольная матрица,
| + | Числа и векторы Ритца являются ''оптимальными'' приближениями к собственным значениям и собственным векторам матрицы <math>A</math>. |
| − | {{Шаблон:LCommon}}
| |
| − | или в виде <math>A = U^* U</math>, <math>U</math> — верхняя треугольная матрица,
| |
| − | {{Шаблон:UCommon}}
| |
| − | Эти разложения совершенно эквивалентны друг другу по вычислениям и различаются только способом представления данных). Он заключается в реализации формул для элементов матрицы <math>L</math>, получающихся из вышеприведённого равенства единственным образом. Получило широкое распространение благодаря следующим особенностям.
| |
| | | | |
| − | ==== Симметричность и положительная определённость матрицы ==== | + | При применении метода Ланцоша в арифметике с плавающей точкой ортогональность в вычисленных векторах Ланцоша <math>q_k</math> пропадает из-за ошибок округления. Потеря ортогональности не заставляет алгоритм вести себя совершенно не предсказуемым образом. В самом деле, мы увидим, что цена, которую мы платим за потерю, это приобретение повторных копий сошедшихся чисел Ритца. Для того чтобы поддержать взаимную ортогональность векторов Ланцоша, существуют две модификации алгоритма. |
| | + | # '''Алгоритм Ланцоша с полной переортогонализацией'''. На каждой итерации запускается повторный процесс ортогонализации Грамма-Шмидта <math>z = z - \textstyle \sum_{i=1}^{j-1} (z^T q_i)q_i \displaystyle</math> |
| | + | # '''Алгоритм Ланцоша с выборочной ортогонализацией'''. Согласно теореме Пейджа векторы <math>q_k</math> теряют ортогональность весьма систематическим образом, а именно, приобретая большие компоненты в направлениях уже сошедшихся векторов Ритца (Именно это приводит к появлению повторных копий сошедшихся чисел Ритца). Поэтому можно выборочно ортогонализировать векторы <math>q_k</math> вместо того, чтобы на каждом шаге ортогонализировать вектор ко всем ранее сошедшимся векторам, как это делается при полной ортогонализации. Таким образом достигается (почти) ортогональности векторов Ланцоша, затрачивая очень небольшая дополнительную работу. |
| | | | |
| − | Симметричность матрицы позволяет хранить и вычислять только чуть больше половины её элементов, что почти вдвое экономит как необходимые для вычислений объёмы памяти, так и количество операций в сравнении с, например, разложением по методу Гаусса. При этом альтернативное (без вычисления квадратных корней) LU-разложение, использующее симметрию матрицы, всё же несколько быстрее метода Холецкого (не использует извлечение квадратных корней), но требует хранения всей матрицы.
| + | == Математическое описание алгоритма == |
| − | Благодаря тому, что разлагаемая матрица не только симметрична, но и положительно определена, её LU-разложения, в том числе и разложение методом Холецкого, имеют наименьшее ''[[Глоссарий#Эквивалентное возмущение|эквивалентное возмущение]]'' из всех известных разложений матриц.
| |
| | | | |
| − | ==== Режим накопления ====
| + | Пусть <math>A</math> - заданная симметричная матрица, <math>b</math> - вектор начального приближения метода Ланцоша. |
| | + | Тогда алгоритм Ланцоша вычисления собственных векторов и собственных значений матрицы <math>A</math> с выборочной ортогонализацией имеет следующий вид: |
| | | | |
| − | Алгоритм позволяет использовать так называемый ''режим накопления'', обусловленный тем, что значительную часть вычислений составляют ''вычисления скалярных произведений''.
| + | <math> |
| − | | |
| − | === Математическое описание алгоритма ===
| |
| − | | |
| − | Исходные данные: положительно определённая симметрическая матрица <math>A</math> (элементы <math>a_{ij}</math>).
| |
| − | | |
| − | Вычисляемые данные: нижняя треугольная матрица <math>L</math> (элементы <math>l_{ij}</math>).
| |
| − | | |
| − | Формулы метода:
| |
| − | :<math>
| |
| | \begin{align} | | \begin{align} |
| − | l_{11} & = \sqrt{a_{11}}, \\
| + | q_1 = & b / \Vert b \Vert_2, \; \beta_0 = 0,\; q_0 = 0\\ |
| − | l_{j1} & = \frac{a_{j1}}{l_{11}}, \quad j \in [2, n], \\
| + | for \; & j = 1 \; to \; k \\ |
| − | l_{ii} & = \sqrt{a_{ii} - \sum_{p = 1}^{i - 1} l_{ip}^2}, \quad i \in [2, n], \\
| + | & z = A\,q_j\\ |
| − | l_{ji} & = \left (a_{ji} - \sum_{p = 1}^{i - 1} l_{ip} l_{jp} \right ) / l_{ii}, \quad i \in [2, n - 1], j \in [i + 1, n].
| + | & \alpha_j = q_j^T z\\ |
| | + | & z = z - \alpha_j q_j - \beta_{j-1}q_{j-1}\\ |
| | + | & for \; i=1 \; to \; k \\ |
| | + | & \; \; \; if \; \beta_k \|v_i (k)\| \le \sqrt{\epsilon} \Vert T_k \Vert_2 \; then\\ |
| | + | & \; \; \; \; \; \; z = z - (y_{i,k} ^ T z) y_{i,k} \;/*\; y_{i,k} = Q_k v_i \;*/ \\ |
| | + | & end \; for\\ |
| | + | & \beta_j = \Vert z \Vert_2\\ |
| | + | & if \; \beta_j = 0 \; then\\ |
| | + | & \; \; \; Stop\; the\; algorithm\\ |
| | + | & q_{j+1} = z / \beta_j\\ |
| | + | & /*Calculate\; eigenvalues\; and\; eigenvektors\; of\; T_j\; */\\ |
| | + | end \; & for |
| | \end{align} | | \end{align} |
| | </math> | | </math> |
| | | | |
| − | Существует также блочная версия метода, однако в данном описании разобран только точечный метод.
| + | Где <math>v_i</math> - это столбцы ортогональной матрицы <math>V</math> из спектрального разложения <math>T_k = V \Lambda V^T</math>, а <math>y_{k,i} = Q_k v_i</math> - столбцы матрицы <math>Q_k V</math> - векторы Ритца. |
| | | | |
| − | В ряде реализаций деление на диагональный элемент выполняется в два этапа: вычисление <math>\frac{1}{l_{ii}}</math> и затем умножение на него всех (видоизменённых) <math>a_{ji}</math> . Здесь мы этот вариант алгоритма не рассматриваем. Заметим только, что он имеет худшие параллельные характеристики, чем представленный.
| + | Матрица <math>T_j</math> |
| | | | |
| − | === Вычислительное ядро алгоритма ===
| + | :<math> |
| − | | + | T_j = \begin{pmatrix} |
| − | Вычислительное ядро последовательной версии метода Холецкого можно составить из множественных (всего их <math>\frac{n (n - 1)}{2}</math>) вычислений скалярных произведений строк матрицы:
| + | \alpha_1 & \beta_1 \\ |
| − | | + | \beta_1 & \alpha_2 & \beta_2 \\ |
| − | :<math>\sum_{p = 1}^{i - 1} l_{ip} l_{jp}</math>
| + | & \beta_2 & \ddots & \ddots \\ |
| − | | + | & & \ddots & \ddots & \beta_{j-1} \\ |
| − | в режиме накопления или без него, в зависимости от требований задачи. Во многих последовательных реализациях упомянутый способ представления не используется. Дело в том, что в них вычисление сумм типа
| + | & & & \beta_{j-1} & \alpha_j |
| − | | + | \end{pmatrix}\; |
| − | :<math>a_{ji} - \sum_{p = 1}^{i - 1} l_{ip} l_{jp}</math><nowiki/>
| |
| − | | |
| − | в которых и встречаются скалярные произведения, ведутся не в порядке «вычислили скалярное произведение, а потом вычли его из элемента», а путём вычитания из элемента покомпонентных произведений, являющихся частями скалярных произведений. Поэтому следует считать вычислительным ядром метода не вычисления скалярных произведений, а вычисления выражений
| |
| − | | |
| − | :<math>a_{ji} - \sum_{p = 1}^{i - 1} l_{ip} l_{jp}</math>
| |
| − | | |
| − | в ''режиме накопления'' или без него.
| |
| − | | |
| − | Тем не менее, в популярных зарубежных реализациях точечного метода Холецкого, в частности, в библиотеках LINPACK и LAPACK, основанных на BLAS, используются именно вычисления скалярных произведений в виде вызова соответствующих подпрограмм BLAS (конкретно — функции SDOT). На последовательном уровне это влечёт за собой дополнительную операцию суммирования на каждый из <math>\frac{n (n + 1)}{2}</math> вычисляемый элемент матрицы <math>L</math> и некоторое замедление работы программы (о других следствиях рассказано ниже в разделе «[[#Существующие реализации алгоритма|Существующие реализации алгоритма]]»). Поэтому в данных вариантах ядром метода Холецкого будут вычисления этих скалярных произведений.
| |
| − | | |
| − | === Макроструктура алгоритма ===
| |
| − | | |
| − | Как записано и в [[#Вычислительное ядро алгоритма|описании ядра алгоритма]], основную часть метода составляют множественные (всего <math>\frac{n (n - 1)}{2}</math>) вычисления сумм
| |
| − | | |
| − | :<math>a_{ji}-\sum_{p=1}^{i-1}l_{ip} l_{jp}</math>
| |
| − | | |
| − | в режиме накопления или без него.
| |
| − | | |
| − | === Схема реализации последовательного алгоритма ===
| |
| − | | |
| − | Последовательность исполнения метода следующая:
| |
| − | | |
| − | 1. <math>l_{11}= \sqrt{a_{11}}</math>
| |
| − | | |
| − | 2. <math>l_{j1}= \frac{a_{j1}}{l_{11}}</math> (при <math>j</math> от <math>2</math> до <math>n</math>).
| |
| − | | |
| − | Далее для всех <math>i</math> от <math>2</math> до <math>n</math> по нарастанию выполняются
| |
| − | | |
| − | 3. <math>l_{ii} = \sqrt{a_{ii} - \sum_{p = 1}^{i - 1} l_{ip}^2}</math> и
| |
| − | | |
| − | 4. (кроме <math>i = n</math>): <nowiki/><math>l_{ji} = \left (a_{ji} - \sum_{p = 1}^{i - 1} l_{ip} l_{jp} \right ) / l_{ii}</math> (для всех <math>j</math> от <math>i + 1</math> до <math>n</math>).
| |
| − | | |
| − | После этого (если <math>i < n</math>) происходит переход к шагу 3 с бо́льшим <math>i</math>.
| |
| − | | |
| − | Особо отметим, что вычисления сумм вида <math>a_{ji} - \sum_{p = 1}^{i - 1} l_{ip} l_{jp}</math> в обеих формулах производят в режиме накопления вычитанием из <math>a_{ji}</math> произведений <math>l_{ip} l_{jp}</math> для <math>p</math> от <math>1</math> до <math>i - 1</math>, c нарастанием <math>p</math>.
| |
| − | | |
| − | === Последовательная сложность алгоритма ===
| |
| − | | |
| − | Для разложения матрицы порядка n методом Холецкого в последовательном (наиболее быстром) варианте требуется:
| |
| − |
| |
| − | * <math>n</math> вычислений квадратного корня,
| |
| − | * <math>\frac{n(n-1)}{2}</math> делений,
| |
| − | * <math>\frac{n^3-n}{6}</math> сложений (вычитаний),
| |
| − | * <math>\frac{n^3-n}{6}</math> умножений.
| |
| − | | |
| − | Умножения и сложения (вычитания) составляют ''основную часть алгоритма''.
| |
| − |
| |
| − | При этом использование режима накопления требует совершения умножений и вычитаний в режиме двойной точности (или использования функции вроде DPROD в Фортране), что ещё больше увеличивает долю умножений и сложений/вычитаний во времени, требуемом для выполнения метода Холецкого.
| |
| − | | |
| − | При классификации по последовательной сложности, таким образом, метод Холецкого относится к алгоритмам ''с кубической сложностью''.
| |
| − | | |
| − | === Информационный граф ===
| |
| − | | |
| − | Опишем [[глоссарий#Граф алгоритма|граф алгоритма]]<ref>Воеводин В.В. Математические основы параллельных вычислений// М.: Изд. Моск. ун-та, 1991. 345 с.</ref><ref>Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. – СПб.: БХВ - Петербург, 2002. – 608 с.</ref><ref>Фролов А.В.. Принципы построения и описание языка Сигма. Препринт ОВМ АН N 236. М.: ОВМ АН СССР, 1989.</ref> как аналитически, так и в виде рисунка.
| |
| − | | |
| − | Граф алгоритма состоит из трёх групп вершин, расположенных в целочисленных узлах трёх областей разной размерности.
| |
| − | | |
| − | '''Первая''' группа вершин расположена в одномерной области, соответствующая ей операция вычисляет функцию SQRT.
| |
| − | Единственная координата каждой из вершин <math>i</math> меняется в диапазоне от <math>1</math> до <math>n</math>, принимая все целочисленные значения.
| |
| − | | |
| − | Аргумент этой функции
| |
| − |
| |
| − | * при <math>i = 1</math> — элемент ''входных данных'', а именно <math>a_{11}</math>;
| |
| − | * при <math>i > 1</math> — результат срабатывания операции, соответствующей вершине из третьей группы, с координатами <math>i - 1</math>, <math>i</math>, <math>i - 1</math>.
| |
| − | Результат срабатывания операции является ''выходным данным'' <math>l_{ii}</math>.
| |
| − | | |
| − | '''Вторая''' группа вершин расположена в двумерной области, соответствующая ей операция <math>a / b</math>.
| |
| − | Естественно введённые координаты области таковы:
| |
| − | * <math>i</math> — меняется в диапазоне от <math>1</math> до <math>n-1</math>, принимая все целочисленные значения;
| |
| − | * <math>j</math> — меняется в диапазоне от <math>i+1</math> до <math>n</math>, принимая все целочисленные значения.
| |
| − | | |
| − | Аргументы операции следующие:
| |
| − | *<math>a</math>:
| |
| − | ** при <math>i = 1</math> — элементы ''входных данных'', а именно <math>a_{j1}</math>;
| |
| − | ** при <math>i > 1</math> — результат срабатывания операции, соответствующей вершине из третьей группы, с координатами <math>i - 1, j, i - 1</math>;
| |
| − | * <math>b</math> — результат срабатывания операции, соответствующей вершине из первой группы, с координатой <math>i</math>.
| |
| − | | |
| − | Результат срабатывания операции является ''выходным данным'' <math>l_{ji}</math>.
| |
| − | | |
| − | '''Третья''' группа вершин расположена в трёхмерной области, соответствующая ей операция <math>a - b * c</math>.
| |
| − | Естественно введённые координаты области таковы:
| |
| − | * <math>i</math> — меняется в диапазоне от <math>2</math> до <math>n</math>, принимая все целочисленные значения;
| |
| − | * <math>j</math> — меняется в диапазоне от <math>i</math> до <math>n</math>, принимая все целочисленные значения;
| |
| − | * <math>p</math> — меняется в диапазоне от <math>1</math> до <math>i - 1</math>, принимая все целочисленные значения.
| |
| − | | |
| − | Аргументы операции следующие:
| |
| − | *<math>a</math>:
| |
| − | ** при <math>p = 1</math> элемент входных данных <math>a_{ji}</math>;
| |
| − | ** при <math>p > 1</math> — результат срабатывания операции, соответствующей вершине из третьей группы, с координатами <math>i, j, p - 1</math>;
| |
| − | *<math>b</math> — результат срабатывания операции, соответствующей вершине из второй группы, с координатами <math>p, i</math>;
| |
| − | *<math>c</math> — результат срабатывания операции, соответствующей вершине из второй группы, с координатами <math>p, j</math>;
| |
| − | | |
| − | Результат срабатывания операции является ''промежуточным данным'' алгоритма.
| |
| − | | |
| − | Описанный граф можно посмотреть на рис.1 и рис.2, выполненных для случая <math>n = 4</math>. Здесь вершины первой группы обозначены жёлтым цветом и буквосочетанием sq, вершины второй — зелёным цветом и знаком деления, третьей — красным цветом и буквой f. Вершины, соответствующие операциям, производящим выходные данные алгоритма, выполнены более крупно. Дублирующие друг друга дуги даны как одна. На рис.1 показан граф алгоритма согласно классическому определению , на рис.2 к графу алгоритма добавлены вершины , соответствующие входным (обозначены синим цветом) и выходным (обозначены розовым цветом) данным.
| |
| − | | |
| − | [[file:Cholesky full.png|thumb|center|1400px|Рисунок 1. Граф алгоритма без отображения входных и выходных данных. SQ - вычисление квадратного корня, F - операция a-bc, Div - деление.]]
| |
| − | [[file:Cholesky full_in_out.png|thumb|center|1400px|Рисунок 2. Граф алгоритма с отображением входных и выходных данных. SQ - вычисление квадратного корня, F - операция a-bc, Div - деление, In - входные данные, Out - результаты.]]
| |
| − | | |
| − | <center>
| |
| − | {{#widget:Iframe
| |
| − | |url=https://algowiki-project.org/html/Algo_viewer_json/cholesky/Algo_viewer_example_2.html
| |
| − | |width=800
| |
| − | |height=600
| |
| − | |border=1
| |
| − | }}
| |
| − | <br/>
| |
| − | Интерактивное изображение графа алгоритма без входных и выходных данных для n = 4.
| |
| − | </center>
| |
| − | | |
| − | === Ресурс параллелизма алгоритма ===
| |
| − | | |
| − | Для разложения матрицы порядка <math>n</math> методом Холецкого в параллельном варианте требуется последовательно выполнить следующие ярусы:
| |
| − | * <math>n</math> ярусов с вычислением квадратного корня (единичные вычисления в каждом из ярусов),
| |
| − | * <math>n - 1</math> ярус делений (в каждом из ярусов линейное количество делений, в зависимости от яруса — от <math>1</math> до <math>n - 1</math>),
| |
| − | * по <math>n - 1</math> ярусов умножений и сложений/вычитаний (в каждом из ярусов — квадратичное количество операций, от <math>1</math> до <math>\frac{n^2 - n}{2}</math>.
| |
| − |
| |
| − | Таким образом, в параллельном варианте, в отличие от последовательного, вычисления квадратных корней и делений будут определять довольно значительную долю требуемого времени. При реализации на конкретных архитектурах наличие в отдельных ярусах [[глоссарий#Ярусно-параллельная форма графа алгоритма|ЯПФ]] отдельных вычислений квадратных корней может породить и другие проблемы. Например, при реализации на ПЛИСах остальные вычисления (деления и тем более умножения и сложения/вычитания) могут быть конвейеризованы, что даёт экономию и по ресурсам на программируемых платах; вычисления же квадратных корней из-за их изолированности приведут к занятию ресурсов на платах, которые будут простаивать большую часть времени. Таким образом, общая экономия в 2 раза, из-за которой метод Холецкого предпочитают в случае симметричных задач тому же методу Гаусса, в параллельном случае уже имеет место вовсе не по всем ресурсам, и главное - не по требуемому времени.
| |
| − | | |
| − | При этом использование режима накопления требует совершения умножений и вычитаний в режиме двойной точности, а в параллельном варианте это означает, что практически все промежуточные вычисления для выполнения метода Холецкого в режиме накопления должны быть двойной точности. В отличие от последовательного варианта это означает увеличение требуемой памяти почти в 2 раза.
| |
| − | | |
| − | При классификации по высоте ЯПФ, таким образом, метод Холецкого относится к алгоритмам со сложностью <math>O(n)</math>. При классификации по ширине ЯПФ его сложность будет <math>O(n^2)</math>.
| |
| − | | |
| − | === Входные и выходные данные алгоритма ===
| |
| − | | |
| − | '''Входные данные''': плотная матрица <math>A</math> (элементы <math>a_{ij}</math>).
| |
| − | Дополнительные ограничения:
| |
| − | * <math>A</math> – симметрическая матрица, т. е. <math>a_{ij}= a_{ji}, i, j = 1, \ldots, n</math>.
| |
| − | * <math>A</math> – положительно определённая матрица, т. е. для любых ненулевых векторов <math>\vec{x}</math> выполняется <math>\vec{x}^T A \vec{x} > 0</math>.
| |
| − | | |
| − | '''Объём входных данных''': <math>\frac{n (n + 1)}{2}</math> (в силу симметричности достаточно хранить только диагональ и над/поддиагональные элементы). В разных реализациях эта экономия хранения может быть выполнена разным образом. Например, в библиотеке, реализованной в НИВЦ МГУ, матрица A хранилась в одномерном массиве длины <math>\frac{n (n + 1)}{2}</math> по строкам своего нижнего треугольника.
| |
| − | | |
| − | '''Выходные данные''': нижняя треугольная матрица <math>L</math> (элементы <math>l_{ij}</math>).
| |
| − | | |
| − | '''Объём выходных данных''': <math>\frac{n (n + 1)}{2}</math> (в силу треугольности достаточно хранить только ненулевые элементы). В разных реализациях эта экономия хранения может быть выполнена разным образом. Например, в той же библиотеке, созданной в НИВЦ МГУ, матрица <math>L</math> хранилась в одномерном массиве длины <math>\frac{n (n + 1)}{2}</math> по строкам своей нижней части.
| |
| − | | |
| − | === Свойства алгоритма ===
| |
| − | | |
| − | Соотношение последовательной и параллельной сложности в случае неограниченных ресурсов, как хорошо видно, является ''квадратичным'' (отношение кубической к линейной).
| |
| − | | |
| − | При этом вычислительная мощность алгоритма, как отношение числа операций к суммарному объему входных и выходных данных – всего лишь ''линейна''.
| |
| − | | |
| − | При этом алгоритм почти полностью детерминирован, это гарантируется теоремой о единственности разложения. Использование другого порядка выполнения ассоциативных операций может привести к накоплению ошибок округления, однако это влияние в используемых вариантах алгоритма не так велико, как, скажем, отказ от использования режима накопления.
| |
| − | | |
| − | Дуги информационного графа, исходящие из вершин, соответствующих операциям квадратного корня и деления, образуют пучки т. н. рассылок линейной мощности (то есть степень исхода этих вершин и мощность работы с этими данными — линейная функция от порядка матрицы и координат этих вершин). При этом естественно наличие в этих пучках «длинных» дуг. Остальные дуги локальны.
| |
| − | | |
| − | Наиболее известной является компактная укладка графа — его проекция на треугольник матрицы, который перевычисляется укладываемыми операциями. При этом «длинные» дуги можно убрать, заменив более дальнюю пересылку комбинацией нескольких ближних (к соседям).
| |
| − | | |
| − | [[Глоссарий#Эквивалентное возмущение|Эквивалентное возмущение]] <math>M</math> у метода Холецкого всего вдвое больше, чем возмущение <math>\delta A</math>, вносимое в матрицу при вводе чисел в компьютер:
| |
| − | <math>
| |
| − | ||M||_{E} \leq 2||\delta A||_{E}
| |
| | </math> | | </math> |
| | | | |
| − | Это явление обусловлено положительной определённостью матрицы. Среди всех используемых разложений матриц это наименьшее из эквивалентных возмущений.
| |
| − |
| |
| − | == Программная реализация алгоритма ==
| |
| − |
| |
| − | === Особенности реализации последовательного алгоритма ===
| |
| − |
| |
| − | В простейшем (без перестановок суммирования) варианте метод Холецкого на Фортране можно записать так:
| |
| − | <source lang="fortran">
| |
| − | DO I = 1, N
| |
| − | S = A(I,I)
| |
| − | DO IP=1, I-1
| |
| − | S = S - DPROD(A(I,IP), A(I,IP))
| |
| − | END DO
| |
| − | A(I,I) = SQRT (S)
| |
| − | DO J = I+1, N
| |
| − | S = A(J,I)
| |
| − | DO IP=1, I-1
| |
| − | S = S - DPROD(A(I,IP), A(J,IP))
| |
| − | END DO
| |
| − | A(J,I) = S/A(I,I)
| |
| − | END DO
| |
| − | END DO
| |
| − | </source>
| |
| − | При этом для реализации режима накопления переменная <math>S</math> должна быть двойной точности.
| |
| | | | |
| − | Отдельно следует обратить внимание на используемую в такой реализации функцию DPROD. Её появление как раз связано с тем, как математики могли использовать режим накопления вычислений. Дело в том, что, как правило, при выполнении умножения двух чисел с плавающей запятой сначала результат получается с удвоенными длинами мантиссы и порядка, и только при выполнении присваивания переменной одинарной точности результат округляется. Эта возможность даёт выполнять умножение действительных чисел с двойной точностью без предварительного приведения их к типу двойной точности. На ранних этапах развития вычислительных библиотек снятие результата без округление реализовали вставками специального кода в фортран-программы, но уже в 70-х гг. XX века в ряде трансляторов Фортрана появилась функция DPROD, реализующая это без обращения программиста к машинным кодам. Она была закреплена среди стандартных функций в стандарте Фортран 77, и реализована во всех современных трансляторах Фортрана.
| + | Согласно теореме Пейджа, <math>y_{k,i}^T q_{k+1} = O(\epsilon \Vert A \Vert_2) / \beta_k \Vert v_i(k) \Vert</math>, то есть компонента <math>y_{k,i}^T q_{k+1}</math> вычисленного вектора Ланцоша <math>q_{k+1}</math> в направлении вектора Ритца <math>y_{k,i} = Q_k v_i</math> обратно пропорциональна величине <math>\beta_k \Vert v_i(k) \Vert</math>, являющейся оценкой погрешности для соответствующего числа Ритца. Поэтому, когда число Ритца сходится, а его оценка погрешности приближается к нулю, вектор Ланцоша приобретает большую компоненту в направлении вектора Ритца <math>q_{k,i}</math>, и следует произвести процедуру переортогонализации. |
| | | | |
| − | Для метода Холецкого существует блочная версия, которая отличается от точечной не тем, что операции над числами заменены на аналоги этих операций над блоками; её построение основано на том, что практически все циклы точечной версии имеют тип SchedDo в терминах методологии, основанной на исследовании информационного графа и, следовательно, могут быть развёрнуты. Тем не менее, обычно блочную версию метода Холецкого записывают не в виде программы с развёрнутыми и переставленными циклами, а в виде программы, подобной реализации точечного метода, в которой вместо соответствующих скалярных операций присутствуют операции над блоками.
| + | Величина погрешности <math>\beta_k \Vert v_i(k) \Vert</math> считается малой, если она меньше, чем <math>\sqrt{\epsilon} \Vert A \Vert_2</math>, так как в этом случае, согласно теореме Пейджа, компонента <math>\Vert y_{i,k}^T q_{k+1} \Vert = \Vert y_{i,k}^T z \Vert / \Vert z \Vert_2</math> скорее всего превосходит уровень <math>\sqrt{\epsilon}</math> (на практике используется <math>\Vert T_k \Vert_2</math> вместо <math>\Vert A \Vert_2</math>, так как первое известно, а второе не всегда). |
| | | | |
| − | Особенностью размещения массивов в Фортране является хранение их "по столбцам" (быстрее всего меняется первый индекс). Поэтому для обеспечения локальности работы с памятью представляется более эффективной такая схема метода Холецкого (полностью эквивалентная описанной), когда исходная матрица и её разложение хранятся не в нижнем, а в верхнем треугольнике. Тогда при вычислениях скалярных произведений программа будет "идти" по последовательным ячейкам памяти компьютера.
| + | == Вычислительное ядро алгоритма == |
| | | | |
| − | Есть и другой вариант точечной схемы: использовать вычисляемые элементы матрицы <math>L</math> в качестве аргументов непосредственно «сразу после» их вычисления. Такая программа будет выглядеть так:
| + | У описанного алгоритма два ядра, на которые приходится основное время работы алгоритма: |
| − | <source lang="fortran">
| |
| − | DO I = 1, N
| |
| − | A(I,I) = SQRT (A(I, I))
| |
| − | DO J = I+1, N
| |
| − | A(J,I) = A(J,I)/A(I,I)
| |
| − | END DO
| |
| − | DO K=I+1,N
| |
| − | DO J = K, N
| |
| − | A(J,K) = A(J,K) - A(J,I)*A(K,I)
| |
| − | END DO
| |
| − | END DO
| |
| − | END DO
| |
| − | </source>
| |
| − | Как видно, в этом варианте для реализации режима накопления одинарной точности мы должны будем объявить двойную точность для массива, хранящего исходные данные и результат. Подчеркнём, что [[глоссарий#Граф алгоритма|граф алгоритма]] обеих схем - один и тот же (из п.1.7), если не считать изменением замену умножения на функцию DPROD!
| |
| | | | |
| − | === Локальность данных и вычислений === | + | * Вычисление вектора <math>z = A q_j</math> |
| | + | * Выборочная переортогонализация <math>z = z - (y_{i,k} ^ T z) y_{i,k}</math> |
| | + | При больших <math>k</math>, сопоставимых с <math>n</math> , к вычислительному ядру можно отнести вычисление собственных значений и собственных векторов трёхдиагональной матрицы. Однако на практике <math>k</math> много меньше <math>n</math>. |
| | | | |
| − | ==== Локальность реализации алгоритма ==== | + | == Макроструктура алгоритма == |
| | | | |
| − | ===== Структура обращений в память и качественная оценка локальности =====
| + | Макроструктура алгоритма Ланцоша с выборочной переортогонализацией представляется в виде совокупности метода Ланцоша с выборочной переортогонализацией построения крыловского подпространства и процедуры Рэлея-Ритца. |
| | | | |
| − | [[file:Cholesky_locality1.jpg|thumb|center|700px|Рисунок 3. Реализация метода Холецкого. Общий профиль обращений в память]]
| + | Каждая итерация первого этапа может быть разложена на следующие макроединицы: |
| | | | |
| − | На рис.3 представлен профиль обращений в память<ref>Воеводин Вад. В. Визуализация и анализ профиля обращений в память // Вестник Южно-Уральского государственного университета. Серия Математическое моделирование и про-граммирование. — 2011. — Т. 17, № 234. — С. 76–84.</ref><ref>Воеводин Вл. В., Воеводин Вад. В. Спасительная локальность суперкомпьютеров // Открытые системы. — 2013. — № 9. — С. 12–15.</ref> для реализации метода Холецкого. В программе задействован только 1 массив, поэтому в данном случае обращения в профиле происходят только к элементам этого массива. Программа состоит из одного основного этапа, который, в свою очередь, состоит из последовательности подобных итераций. Пример одной итерации выделен зеленым цветом.
| + | 1 Умножение матрицы на вектор, <math>z=Aq_j</math>. |
| | | | |
| − | Видно, что на каждой <math>i</math>-й итерации используются все адреса, начиная с некоторого, при этом адрес первого обрабатываемого элемента увеличивается. Также можно заметить, что число обращений в память на каждой итерации растет примерно до середины работы программы, после чего уменьшается вплоть до завершения работы. Это позволяет говорить о том, что данные в программе используются неравномерно, при этом многие итерации, особенно в начале выполнения программы, задействуют большой объем данных, что приводит к ухудшению локальности.
| + | 2. Вычисление вектора <math>q_{j+1} </math> с помощью линейной комбинации других векторов: |
| | | | |
| − | Однако в данном случае основным фактором, влияющим на локальность работы с памятью, является строение итерации. Рассмотрим фрагмент профиля, соответствующий нескольким первым итерациям.
| + | <math>\alpha_j=q_j^Tz, </math> |
| | | | |
| − | [[file:Cholesky_locality2.jpg|thumb|center|700px|Рисунок 4. Реализация метода Холецкого. Фрагмент профиля (несколько первых итераций)]]
| + | <math>z=z-\alpha_jq_j-\beta_{j-1}q_{j-1}, </math> |
| | | | |
| − | Исходя из рис.4 видно, что каждая итерация состоит из двух различных фрагментов. Фрагмент 1 – последовательный перебор (с некоторым шагом) всех адресов, начиная с некоторого начального. При этом к каждому адресу происходит мало обращений. Такой фрагмент обладает достаточно неплохой пространственной локальностью, так как шаг по памяти между соседними обращениями невелик, но плохой временно́й локальностью, поскольку данные редко используются повторно.
| + | <math>q_{j+1}=z/\|z\|_2</math> |
| | | | |
| − | Фрагмент 2 устроен гораздо лучше с точки зрения локальности. В рамках этого фрагмента выполняется большое число обращений подряд к одним и тем же данным, что обеспечивает гораздо более высокую степень как пространственной, так и временно́й локальности по сравнению с фрагментом 1.
| + | 3. Ортогонализация вектора Ланцоша с помощью скалярного произведения: |
| | | | |
| − | После рассмотрения фрагмента профиля на рис.4 можно оценить общую локальность двух фрагментов на каждой итерации. Однако стоит рассмотреть более подробно, как устроен каждый из фрагментов.
| + | <math>z = z-(y^T_{i,k},z)y_{i,k} </math> |
| | | | |
| − | [[file:Cholesky_locality3.jpg|thumb|center|700px|Рисунок 5. Реализация метода Холецкого. Фрагмент профиля (часть одной итерации)]]
| + | 4. Нахождении собственных значений и собственных векторов матрицы и интерпретации их как приближенных значений собственных чисел и собственных векторов исходной матрицы, он может быть выполнен любым способом, например, разделяй и властвуй или же QR-итерацией. |
| | | | |
| − | Рис.5, на котором представлена часть одной итерации общего профиля (см. рис.3), позволяет отметить достаточно интересный факт: строение каждого из фрагментов на самом деле заметно сложнее, чем это выглядит на рис.4. В частности, каждый шаг фрагмента 1 состоит из нескольких обращений к соседним адресам, причем выполняется не последовательный перебор. Также можно увидеть, что фрагмент 2 на самом деле в свою очередь состоит из повторяющихся итераций, при этом видно, что каждый шаг фрагмента 1 соответствует одной итерации фрагмента 2 (выделено зеленым на рис.5). Это лишний раз говорит о том, что для точного понимания локальной структуры профиля необходимо его рассмотреть на уровне отдельных обращений.
| + | == Схема реализации последовательного алгоритма == |
| | | | |
| − | Стоит отметить, что выводы на основе рис.5 просто дополняют общее представлении о строении профиля обращений; сделанные на основе рис.4 выводы относительно общей локальности двух фрагментов остаются верны.
| + | На вход алгоритму подаются исходная матрица <math>A</math>, вектор начального приближения <math>b</math> и число <math>k</math>. |
| | + | Далее последовательно выполняются итерационно для всех <math>j: 1 \le j \le k</math> следующие шаги: |
| | | | |
| − | ===== Количественная оценка локальности =====
| + | # Умножается матрица на вектор для нахождения вектора <math>z</math> |
| | + | # Вычисляется коэффициент <math>\alpha_j</math> посредством скалярного перемножения векторов |
| | + | # Вычисляется новое значение вектора <math>z</math> |
| | + | # Производятся оценка погрешностей <math>\beta_k \Vert v_i(k) \Vert</math> и выборочная переортогонализация |
| | + | # Вычисление очередного значения <math>\beta_j</math> - норма вектора <math>z</math> |
| | + | # Вычисление и добавление к матрице <math>Q</math> нового столбца |
| | + | # Вычисление собственных значений и собственных векторов матрицы <math>T_j</math> |
| | | | |
| − | Основной фрагмент реализации, на основе которого были получены количественные оценки, приведен [http://git.algowiki-project.org/Voevodin/locality/blob/master/benchmarks/holecky/holecky.h здесь] (функция Kernel). Условия запуска описаны [http://git.algowiki-project.org/Voevodin/locality/blob/master/README.md здесь].
| + | == Последовательная сложность алгоритма == |
| | | | |
| − | Первая оценка выполняется на основе характеристики daps, которая оценивает число выполненных обращений (чтений и записей) в память в секунду. Данная характеристика является аналогом оценки flops применительно к работе с памятью и является в большей степени оценкой производительности взаимодействия с памятью, чем оценкой локальности. Однако она служит хорошим источником информации, в том числе для сравнения с результатами по следующей характеристике cvg.
| + | * Вычисление вектора <math>z</math> - <math>n^2</math> операций умножения и <math>n(n-1)</math> операций сложения |
| | + | * Вычисление скалярного произведения векторов - <math>n</math> операций умножения и <math>(n-1)</math> сложений |
| | + | * Вычисление вектора <math>z</math> - <math>2n</math> умножений и <math>2n</math> сложений |
| | + | * Оценка погрешностей - <math>kn</math> операций умножения |
| | + | * Выборочная переортогонализация - <math>O(2nj)</math> умножений и <math>O(2j(n-1) + n)</math> сложений |
| | + | * Вычисление нормы вектора - <math>n</math> операций умножения и <math>(n-1)</math> сложений |
| | + | * Вычисление нового столбца матрицы <math>Q</math> - <math>n</math> операций умножения |
| | | | |
| − | [[file:Cholesky_locality4.jpg|thumb|center|700px|Рисунок 6. Сравнение значений оценки daps]]
| + | Итого на каждой итерации: |
| | | | |
| − | На рис.6 приведены значения daps для реализаций распространенных алгоритмов, отсортированные по возрастанию (чем больше daps, тем в общем случае выше производительность). Можно увидеть, что реализация метода Холецкого характеризуется достаточно высокой скоростью взаимодействия с памятью, однако ниже, чем, например, у теста Линпак или реализации метода Якоби.
| + | * Умножений: <math>n^2 + n + 2n + kn + O(2nj) + n + n = n^2 + 5n + kn + O(2nj)</math> |
| | + | * Сложений: <math>n(n-1) + n-1 + 2n + O(2j(n-1) + n) + n-1 = n^2 + 3n + O(2j(n-1) + n) -2</math> |
| | | | |
| − | Вторая характеристика – cvg – предназначена для получения более машинно-независимой оценки локальности. Она определяет, насколько часто в программе необходимо подтягивать данные в кэш-память. Соответственно, чем меньше значение cvg, тем реже это нужно делать, тем лучше локальность.
| + | Итого за все время выполнения алгоритма: |
| | | | |
| − | [[file:Cholesky_locality5.jpg|thumb|center|700px|Рисунок 7. Сравнение значений оценки cvg]]
| + | * Умножений: <math>kn^2 + 5kn + k^2n + O(k^2n + kn)</math> |
| | + | * Сложений: <math>kn^2 + 3kn + O((k^2+k)(n-1)+kn) = kn^2 + 3kn + O(k^2(n-1)+2kn-k)</math> |
| | | | |
| − | На рис.7 приведены значения cvg для того же набора реализаций, отсортированные по убыванию (чем меньше cvg, тем в общем случае выше локальность). Можно увидеть, что, согласно данной оценке, реализация метода Холецкого оказалась ниже в списке по сравнению с оценкой daps.
| + | Суммарная последовательная сложность алгоритма - <math>O(kn^2 + k^2n)</math>. |
| | | | |
| − | === Возможные способы и особенности параллельной реализации алгоритма === | + | == Информационный граф == |
| | + | [[Файл:Lancos_SO_ingrpah.png|center|frame |рис. 1: Информационный граф]] |
| | | | |
| − | Как нетрудно видеть по структуре графа алгоритма, вариантов распараллеливания алгоритма довольно много. Например, во втором варианте (см. раздел «[[#Особенности реализации последовательного алгоритма|Особенности реализации последовательного алгоритма]]») все внутренние циклы параллельны, в первом — параллелен цикл по <math>J</math>. Тем не менее, простое распараллеливание таким способом «в лоб» вызовет такое количество пересылок между процессорами с каждым шагом по внешнему циклу, которое почти сопоставимо с количеством арифметических операций. Поэтому перед размещением операций и данных между процессорами вычислительной системы предпочтительно разбиение всего пространства вычислений на блоки, с сопутствующим разбиением обрабатываемого массива.
| + | == Ресурс параллелизма алгоритма == |
| | | | |
| − | Многое зависит от конкретного типа вычислительной системы. Присутствие конвейеров на узлах многопроцессорной системы делает рентабельным параллельное вычисление нескольких скалярных произведений сразу. Подобная возможность есть и на программировании ПЛИСов, но там быстродействие будет ограничено медленным последовательным выполнением операции извлечения квадратного корня.
| + | Поскольку алгоритм является итерационным, то выполнять параллельные операции возможно только внутри каждой итерации алгоритма. Сами итерации выполняются в строгой последовательности и не могут быть параллелизованны: |
| − |
| |
| − | В принципе, возможно и использование т. н. «скошенного» параллелизма. Однако его на практике никто не использует, из-за усложнения управляющей структуры программы.
| |
| | | | |
| − | === Масштабируемость алгоритма и его реализации ===
| + | * Вычисление вектора <math>z</math> - умножение матрицы размера <math>n \times n</math> на вектор длины <math>n</math> - <math>n</math> ярусов сложений, <math>n</math> операций умножений в каждом |
| | + | * Вычисление коэффициента <math>\alpha_j</math> - скалярное произведение векторов - <math>n</math> ярусов сложений, 1 операция умножения в каждом |
| | + | * Вычисление нового значения вектора <math>z</math>: 2 яруса умножений длины <math>n</math> (умножение вектора на число), 2 яруса вычитаний длины <math>n</math> |
| | + | * Выборочная переортогонализация: последовательно для всех <math>i \le k</math> выполняется <math>j</math> ярусов сложений, <math>n</math> операций умножений в каждом, <math>n</math> ярусов сложений, <math>j</math> операций умножений в каждом, один ярус вычитаний размера <math>n</math> |
| | + | * Вычисление <math>\beta_j</math> - скалярное произведение векторов - <math>n</math> ярусов сложений, 1 операция умножения в каждом |
| | + | * Вычисление <math>q_j</math> - деление вектора на число - один ярус делений размера <math>n</math> |
| | | | |
| − | ==== Масштабируемость алгоритма ====
| + | Сложность алгоритма по ширине ярусно параллельной формы - <math>O(n)</math>. |
| | | | |
| − | ==== Масштабируемость реализации алгоритма ==== | + | == Входные и выходные данные алгоритма == |
| − | Проведём исследование масштабируемости параллельной реализации разложения Холецкого согласно [[Scalability methodology|методике]]. Исследование проводилось на суперкомпьютере "Ломоносов"<ref name="Lom">Воеводин Вл., Жуматий С., Соболев С., Антонов А., Брызгалов П., Никитенко Д., Стефанов К., Воеводин Вад. Практика суперкомпьютера «Ломоносов» // Открытые системы, 2012, N 7, С. 36-39.</ref> [http://parallel.ru/cluster Суперкомпьютерного комплекса Московского университета].
| |
| | | | |
| − | Набор и границы значений изменяемых [[Глоссарий#Параметры запуска|параметров запуска]] реализации алгоритма:
| + | '''Входные данные''' |
| | | | |
| − | * число процессоров [4 : 256] с шагом 4;
| + | Вещественная матрица <math>A</math> размера <math>n \times n</math>, вектор <math>b</math> длины <math>n</math>, число <math>k</math>, но учитывая что матрица у нас симметричная количество входных данных можно уменьшить в два раза. |
| − | * размер матрицы [1024 : 5120].
| |
| | | | |
| − | В результате проведённых экспериментов был получен следующий диапазон [[Глоссарий#Эффективность реализации|эффективности реализации]] алгоритма:
| + | Объем входных данных: <math>{n (n + 1) \over 2} + n + 1</math> |
| | | | |
| − | * минимальная эффективность реализации 0,11%;
| + | '''Выходные данные''' |
| − | * максимальная эффективность реализации 2,65%.
| |
| | | | |
| − | На следующих рисунках приведены графики [[Глоссарий#Производительность|производительности]] и эффективности выбранной реализации разложения Холецкого в зависимости от изменяемых параметров запуска.
| + | Матрица собственных значений <math> \Lambda = diag(\theta_1 \dots \theta_k) </math>, матрица собственных векторов <math> V = [v_1 \dots v_k] </math> размера <math> n \times k </math> |
| | | | |
| − | [[file:Масштабируемость Параллельной реализации метода Холецкого Производительность3.png|thumb|center|700px|Рисунок 8. Параллельная реализация метода Холецкого. Изменение производительности в зависимости от числа процессоров и размера матрицы.]]
| + | Так, объем выходных данных: <math> k + kn </math> |
| − | [[file:Холецкий масштабируемость эффективность2.png|thumb|center|700px|Рисунок 9. Параллельная реализация метода Холецкого. Изменение эффективности в зависимости от числа процессоров и размера матрицы.]]
| |
| | | | |
| − | Построим оценки масштабируемости выбранной реализации разложения Холецкого:
| + | == Свойства алгоритма == |
| − | * По числу процессов: -0,000593. При увеличении числа процессов эффективность на рассмотренной области изменений параметров запуска уменьшается, однако в целом уменьшение не очень быстрое. Малая интенсивность изменения объясняется крайне низкой общей эффективностью работы приложения с максимумом в 2,65%, и значение эффективности на рассмотренной области значений быстро доходит до десятых долей процента. Это свидетельствует о том, что на большей части области значений нет интенсивного снижения эффективности. Это объясняется также тем, что с ростом [[Глоссарий#Вычислительная сложность|вычислительной сложности]] падение эффективности становится не таким быстрым. Уменьшение эффективности на рассмотренной области работы параллельной программы объясняется быстрым ростом накладных расходов на организацию параллельного выполнения. С ростом вычислительной сложности задачи эффективность снижается так же быстро, но при больших значениях числа процессов. Это подтверждает предположение о том, что накладные расходы начинают сильно превалировать над вычислениями.
| |
| − | * По размеру задачи: 0,06017. При увеличении размера задачи эффективность возрастает. Эффективность возрастает тем быстрее, чем большее число процессов используется для выполнения. Это подтверждает предположение о том, что размер задачи сильно влияет на эффективность выполнения приложения. Оценка показывает, что с ростом размера задачи эффективность на рассмотренной области значений параметров запуска сильно увеличивается. Также, учитывая разницу максимальной и минимальной эффективности в 2,5%, можно сделать вывод, что рост эффективности при увеличении размера задачи наблюдается на большей части рассмотренной области значений.
| |
| − | * По двум направлениям: 0,000403. При рассмотрении увеличения как вычислительной сложности, так и числа процессов на всей рассмотренной области значений эффективность увеличивается, однако скорость увеличения эффективности небольшая. В совокупности с тем фактом, что разница между максимальной и минимальной эффективностью на рассмотренной области значений параметров небольшая, эффективность с увеличением масштабов возрастает, но медленно и с небольшими перепадами.
| |
| | | | |
| − | [http://git.algowiki-project.org/Teplov/Scalability/tree/master/cholesky-decomposition-master Исследованная параллельная реализация на языке C]
| + | * Преимуществом алгоритма является то, что он начинает поиск собственных значений матрицы начиная с максимального в абсолютном смысле значения. Это выгодно отличает данный алгоритм с точки зрения поиска собственных значений матрицы, находящихся по краям её спектра. |
| | + | * Вычислительная мощность алгоритма - отношение числа операций к суммарному объему входных и выходных данных - примерно равно <math>2k</math> при <math>k << n</math> |
| | + | * Алгоритм устойчив, так как операция переортогонализации как раз направлена на исключение проблемы округления вычисляемых значений |
| | + | * Алгоритм не является детерминированным, так как, во-первых, используется для разряженных матриц, и, во-вторых, является итерационным с выходом по точности - число операций заранее не определено |
| | | | |
| − | === Динамические характеристики и эффективность реализации алгоритма === | + | = Программная реализация алгоритма = |
| | | | |
| − | Для проведения экспериментов использовалась реализация разложения Холецкого, представленная в пакете SCALAPACK библиотеки Intel MKL (метод pdpotrf). Все результаты получены на суперкомпьютере «Ломоносов»<ref name="Lom" />. Использовались процессоры Intel Xeon X5570 с пиковой производительностью в 94 Гфлопс, а также компилятор Intel с опцией –O2.
| + | == Особенности реализации последовательного алгоритма == |
| − | На рисунках показана эффективность реализации разложения Холецкого (случай использования нижних треугольников матриц) для разного числа процессов и размерности матрицы 80000, запуск проводился на 256 процессах.
| |
| | | | |
| − | [[file:Cholesky CPU.png|thumb|center|700px|Рисунок 10. График загрузки CPU при выполнении разложения Холецкого]]
| + | == Локальность данных и вычислений == |
| | | | |
| − | На графике загрузки процессора видно, что почти все время работы программы уровень загрузки составляет около 50%. Это хорошая картина для программ, запущенных без использования технологии Hyper Threading.
| + | == Возможные способы и особенности параллельной реализации алгоритма == |
| | | | |
| − | [[file:Cholesky FLOPS.png|thumb|center|700px|Рисунок 11. График операций с плавающей точкой в секунду при выполнении разложения Холецкого]]
| + | == Масштабируемость алгоритма и его реализации == |
| | | | |
| − | На Рисунке 11 показан график количества операций с плавающей точкой в секунду. Видно, что к концу каждой итерации число операций возрастает.
| + | Исследование масштабируемости алгоритма проводилось на суперкомпьютере [//hpc.cmc.msu.ru/ IBM Blue Gene/P ВМК МГУ.] |
| − | [[file:Cholesky L1.png|thumb|center|700px|Рисунок 12. График кэш-промахов L1 в секунду при работе разложения Холецкого]]
| |
| − |
| |
| − | На графике кэш-промахов первого уровня видно, что число промахов достаточно большое и находится на уровне 25 млн/сек в среднем по всем узлам.
| |
| − | [[file:Cholesky L3.png|thumb|center|700px|Рисунок 13. График кэш-промахов L3 в секунду при работе разложения Холецкого]]
| |
| | | | |
| − | На графике кэш-промахов третьего уровня видно, что число промахов все еще достаточно большое и находится на уровне 1,5 млн/сек в среднем по всем узлам. Это указывает на то, что задача достаточно большая, и данные плохо укладываются в кэш-память.
| + | Для компиляции программы использовались компиляторы intel/15.0.090 и Openmpi/1.8.4-icc. |
| − | [[file:Cholesky MemRead.png|thumb|center|700px|Рисунок 14. График количества чтений из оперативной памяти при работе разложения Холецкого]]
| |
| | | | |
| − | На графике чтений из памяти на протяжении всего времени работы программы наблюдается достаточно интенсивная и не сильно изменяющаяся работа с памятью.
| + | Для проведения расчетов и получения полноценной картины поведения алгоритма в зависимости от входных данных и числа процессоров, программа была запущена на следующих параметрах: |
| − | [[file:Cholesky MemWrite.png|thumb|center|700px|Рисунок 15. График количества записей в оперативную память при работе разложения Холецкого]]
| + | * в качестве размера входной матрицы подавались значения в диапазоне [2000:30000] c шагом 2000. |
| | + | * Число процессоров варьировалось от 1 до 256. |
| | + | Ниже на рисунке изображен трехмерный график, показывающий зависимость времени выполнения программы от входных данных/ |
| | + | [[Файл:Lancos_SO.png|центр|мини|1000x1000пкс|График зависимости времени выполнения программы от входных данных]] |
| | + | [http://pastebin.com/SbNrh7nz ссылка код] |
| | | | |
| − | На графике записей в память видна периодичность: на каждой итерации к концу выполнения число записей в память достаточно сильно падает. Это коррелирует с возрастанием числа операций с плавающей точкой и может объясняться тем, что при меньшем числе записей в память программа уменьшает накладные расходы и увеличивает эффективность.
| + | == Динамические характеристики и эффективность реализации алгоритма == |
| − | [[file:Cholesky Inf Bps.png|thumb|center|700px|Рисунок 16. График скорости передачи по сети Infiniband в байт/сек при работе разложения Холецкого]]
| |
| | | | |
| − | На графике скорости передачи данных по сети Infiniband наблюдается достаточно интенсивное использование коммуникационной сети на каждой итерации. Причем к концу каждой итерации интенсивность передачи данных сильно возрастает. Это указывает на большую необходимость в обмене данными между процессами к концу итерации.
| + | == Выводы для классов архитектур == |
| − | [[file:Cholesky Inf Pps.png|thumb|center|700px|Рисунок 17. График скорости передачи по сети Infiniband в пакетах/сек при работе разложения Холецкого]]
| |
| | | | |
| − | На графике скорости передачи данных в пакетах в секунду наблюдается большая «кучность» показаний максимального минимального и среднего значений в сравнении с графиком скорости передачи в байт/сек. Это говорит о том, что, вероятно, процессы обмениваются сообщениями различной длины, что указывает на неравномерное распределение данных. Также наблюдается рост интенсивности использования сети к концу каждой итерации.
| |
| − | [[file:Cholesky LoadAVG.png|thumb|center|700px|Рисунок 18. График числа процессов, ожидающих вхождения в стадию счета (Loadavg), при работе разложения Холецкого]]
| |
| − | На графике числа процессов, ожидающих вхождения в стадию счета (Loadavg), видно, что на протяжении всей работы программы значение этого параметра постоянно и приблизительно равняется 8. Это свидетельствует о стабильной работе программы с восьмью процессами на каждом узле. Это указывает на рациональную и статичную загрузку аппаратных ресурсов процессами.
| |
| − | В целом, по данным системного мониторинга работы программы можно сделать вывод о том, что программа работала достаточно эффективно и стабильно. Использование памяти и коммуникационной среды достаточно интенсивное, что может стать фактором снижения эффективности при существенном росте размера задачи или же числа процессоров.
| |
| − | Для существующих параллельных реализаций характерно отнесение всего ресурса параллелизма на блочный уровень. Относительно низкая эффективность работы связана с проблемами внутри одного узла, следующим фактором является неоптимальное соотношение между «арифметикой» и обменами. Видно, что при некотором (довольно большом) оптимальном размере блока обмены влияют не так уж сильно.
| |
| | | | |
| − | === Выводы для классов архитектур === | + | == Существующие реализации алгоритма== |
| | + | Алгоритм Ланцоша реализован в различных пакетах, библиотеках и проектах |
| | | | |
| − | Как видно по показателям SCALAPACK на суперкомпьютерах, обмены при большом n хоть и уменьшают эффективность расчётов, но слабее, чем неоптимальность организации расчётов внутри одного узла. Поэтому, видимо, следует сначала оптимизировать не блочный алгоритм, а подпрограммы, используемые на отдельных процессорах: точечный метод Холецкого, перемножения матриц и др. подпрограммы. [[#Существующие реализации алгоритма|Ниже]] содержится информация о возможном направлении такой оптимизации.
| + | NAG Library http://www.nag.com/content/nag-library C, C++, Fortran, C#, MATLAB, R |
| | | | |
| − | Вообще эффективность метода Холецкого для параллельных архитектур не может быть высокой. Это связано со следующим свойством информационной структуры алгоритма: если операции деления или вычисления выражений <math>a - bc</math> являются не только массовыми, но и параллельными, и потому их вычисления сравнительно легко выстраивать в конвейеры или распределять по устройствам, то операции извлечения квадратных корней являются узким местом алгоритма. Поэтому для эффективной реализации алгоритмов, столь же хороших по вычислительным характеристикам, как и метод квадратного корня, следует использовать не метод Холецкого, а его давно известную модификацию без извлечения квадратных корней — [[%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%A5%D0%BE%D0%BB%D0%B5%D1%86%D0%BA%D0%BE%D0%B3%D0%BE_(%D0%BD%D0%B0%D1%85%D0%BE%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81%D0%B8%D0%BC%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%BD%D0%BE%D0%B3%D0%BE_%D1%82%D1%80%D0%B5%D1%83%D0%B3%D0%BE%D0%BB%D1%8C%D0%BD%D0%BE%D0%B3%D0%BE_%D1%80%D0%B0%D0%B7%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F)#.5C.28LDL.5ET.5C.29_.D1.80.D0.B0.D0.B7.D0.BB.D0.BE.D0.B6.D0.B5.D0.BD.D0.B8.D0.B5|разложение матрицы в произведение <math>L D L^T</math>]]<ref>Krishnamoorthy A., Menon D. Matrix Inversion Using Cholesky Decomposition. 2013. eprint arXiv:1111.4144</ref>.
| + | ARPACK https://people.sc.fsu.edu/~jburkardt/m_src/arpack/arpack.html MATLAB |
| | | | |
| − | === Существующие реализации алгоритма ===
| + | GrapLab https://turi.com/products/create/open_source.html C++ |
| | | | |
| − | Точечный метод Холецкого реализован как в основных библиотеках программ отечественных организаций, так и в западных пакетах LINPACK, LAPACK, SCALAPACK и др.
| + | Gaussian Belief Propagation Matlab Package http://www.cs.cmu.edu/~bickson/gabp/ MATLAB |
| − |
| |
| − | При этом в отечественных реализациях, как правило, выполнены стандартные требования к методу с точки зрения ошибок округления, то есть, реализован режим накопления, и обычно нет лишних операций. Ряд старых отечественных реализаций использует для экономии памяти упаковку матриц <math>A</math> и <math>L</math> в одномерный массив.
| |
| − |
| |
| − | Реализация точечного метода Холецкого в современных западных пакетах обычно происходит из одной и той же реализации метода в LINPACK, а та использует пакет BLAS. В BLAS скалярное произведение реализовано без режима накопления, но это легко исправляется при желании.
| |
| | | | |
| − | Интересно, что в крупнейших библиотеках алгоритмов до сих пор предлагается именно разложение Холецкого, а более быстрый алгоритм LU-разложения без извлечения квадратных корней используется только в особых случаях (например, для трёхдиагональных матриц), в которых количество диагональных элементов уже сравнимо с количеством внедиагональных.
| + | The IETL Project http://www.comp-phys.org/software/ietl/ C++ |
| | | | |
| − | == Литература ==
| + | LANSO/PLANSO http://web.cs.ucdavis.edu/~bai/ET/lanczos_methods/overview_PLANSO.html Fortran |
| | | | |
| − | <references \>
| + | Julia Math https://github.com/JuliaMath/IterativeSolvers.jl Julia |
| | | | |
| − | [[en:Cholesky decomposition]]
| + | = Литература = |
| | | | |
| − | [[Категория:Законченные статьи]]
| + | * Дж. Деммель, Вычислительная линейная алгебра. Теория и приложения. Пер. с англ. - М.: Мир, 2001. |
| − | [[Категория:Разложения матриц]]
| |
Автор: Абдулпотиев А.А.
| Алгоритм Ланцоша для арифметики с плавающей точкой с выборочной ортогонализацией
|
| Последовательный алгоритм
|
| Последовательная сложность
|
[math]O(kn^2 + k^2n)[/math]
|
| Объём входных данных
|
[math]{n (n + 1) \over 2} + n + 1[/math]
|
| Объём выходных данных
|
[math]k + nk[/math]
|
| Параллельный алгоритм
|
| Высота ярусно-параллельной формы
|
[math]O(kn + k^2)[/math]
|
| Ширина ярусно-параллельной формы
|
[math]O(n)[/math]
|
1 Свойства и структура алгоритма
1.1 Общее описание алгоритма
Алгоритм Ланцоша это итерационный метод нахождения небольшого количества собственных значений столь больших разреженных симметричных матриц, что к ним нельзя применить прямые методы. Иными словами алгоритм сильно оптимизирует использование памяти и вычислительной мощности, что является критически важным для больших вычислений.
Сам алгоритм объединяет метод Ланцоша для построения крыловского подпространства с процедурой Рэлея-Ритца интерпретации собственных значений некоторой вычисляемой матрицы как приближений к собственным значениям исходной матрицы.
Пусть [math]Q = [Q_k,Q_u][/math] - ортогональная матрица порядка [math]n[/math], причем [math]Q_k[/math] и [math]Q_u[/math] имеют соответственно размеры [math]n \times k[/math] и [math]n \times (n-k)[/math]. Столбцы матрицы [math]Q_k[/math] вычисляются методом Ланцоша..
Запишем следующие соотношения:
[math]T = Q^T A Q = [Q_k, Q_u]^T A [Q_k, Q_u] =
\left[ \begin{array}{cc}
Q_k^T A Q_k & Q_k^T A Q_u\\
Q_u^T A Q_k & Q_u^T A Q_u
\end{array} \right]
= \left[ \begin{array}{cc}
T_{k} & T_{ku}^T\\
T_{ku} & T_{u}
\end{array} \right][/math]
Метод Рэлея-Ритца заключается в интерпретации собственных значений матрицы [math]T_k = Q_k^T A Q_k[/math] как приближенных к собственным значениям матрицы [math]A[/math]. Эти приближения называются числами Ритца. Если [math]A = V \Lambda V^T[/math] есть спектральное разложение матрицы [math]T_k[/math], то столбцы матрицы [math]Q_k V[/math] являются приближениями соответствующих собственных векторов и называются векторами Ритца.
Числа и векторы Ритца являются оптимальными приближениями к собственным значениям и собственным векторам матрицы [math]A[/math].
При применении метода Ланцоша в арифметике с плавающей точкой ортогональность в вычисленных векторах Ланцоша [math]q_k[/math] пропадает из-за ошибок округления. Потеря ортогональности не заставляет алгоритм вести себя совершенно не предсказуемым образом. В самом деле, мы увидим, что цена, которую мы платим за потерю, это приобретение повторных копий сошедшихся чисел Ритца. Для того чтобы поддержать взаимную ортогональность векторов Ланцоша, существуют две модификации алгоритма.
- Алгоритм Ланцоша с полной переортогонализацией. На каждой итерации запускается повторный процесс ортогонализации Грамма-Шмидта [math]z = z - \textstyle \sum_{i=1}^{j-1} (z^T q_i)q_i \displaystyle[/math]
- Алгоритм Ланцоша с выборочной ортогонализацией. Согласно теореме Пейджа векторы [math]q_k[/math] теряют ортогональность весьма систематическим образом, а именно, приобретая большие компоненты в направлениях уже сошедшихся векторов Ритца (Именно это приводит к появлению повторных копий сошедшихся чисел Ритца). Поэтому можно выборочно ортогонализировать векторы [math]q_k[/math] вместо того, чтобы на каждом шаге ортогонализировать вектор ко всем ранее сошедшимся векторам, как это делается при полной ортогонализации. Таким образом достигается (почти) ортогональности векторов Ланцоша, затрачивая очень небольшая дополнительную работу.
1.2 Математическое описание алгоритма
Пусть [math]A[/math] - заданная симметричная матрица, [math]b[/math] - вектор начального приближения метода Ланцоша.
Тогда алгоритм Ланцоша вычисления собственных векторов и собственных значений матрицы [math]A[/math] с выборочной ортогонализацией имеет следующий вид:
[math]
\begin{align}
q_1 = & b / \Vert b \Vert_2, \; \beta_0 = 0,\; q_0 = 0\\
for \; & j = 1 \; to \; k \\
& z = A\,q_j\\
& \alpha_j = q_j^T z\\
& z = z - \alpha_j q_j - \beta_{j-1}q_{j-1}\\
& for \; i=1 \; to \; k \\
& \; \; \; if \; \beta_k \|v_i (k)\| \le \sqrt{\epsilon} \Vert T_k \Vert_2 \; then\\
& \; \; \; \; \; \; z = z - (y_{i,k} ^ T z) y_{i,k} \;/*\; y_{i,k} = Q_k v_i \;*/ \\
& end \; for\\
& \beta_j = \Vert z \Vert_2\\
& if \; \beta_j = 0 \; then\\
& \; \; \; Stop\; the\; algorithm\\
& q_{j+1} = z / \beta_j\\
& /*Calculate\; eigenvalues\; and\; eigenvektors\; of\; T_j\; */\\
end \; & for
\end{align}
[/math]
Где [math]v_i[/math] - это столбцы ортогональной матрицы [math]V[/math] из спектрального разложения [math]T_k = V \Lambda V^T[/math], а [math]y_{k,i} = Q_k v_i[/math] - столбцы матрицы [math]Q_k V[/math] - векторы Ритца.
Матрица [math]T_j[/math]
- [math]
T_j = \begin{pmatrix}
\alpha_1 & \beta_1 \\
\beta_1 & \alpha_2 & \beta_2 \\
& \beta_2 & \ddots & \ddots \\
& & \ddots & \ddots & \beta_{j-1} \\
& & & \beta_{j-1} & \alpha_j
\end{pmatrix}\;
[/math]
Согласно теореме Пейджа, [math]y_{k,i}^T q_{k+1} = O(\epsilon \Vert A \Vert_2) / \beta_k \Vert v_i(k) \Vert[/math], то есть компонента [math]y_{k,i}^T q_{k+1}[/math] вычисленного вектора Ланцоша [math]q_{k+1}[/math] в направлении вектора Ритца [math]y_{k,i} = Q_k v_i[/math] обратно пропорциональна величине [math]\beta_k \Vert v_i(k) \Vert[/math], являющейся оценкой погрешности для соответствующего числа Ритца. Поэтому, когда число Ритца сходится, а его оценка погрешности приближается к нулю, вектор Ланцоша приобретает большую компоненту в направлении вектора Ритца [math]q_{k,i}[/math], и следует произвести процедуру переортогонализации.
Величина погрешности [math]\beta_k \Vert v_i(k) \Vert[/math] считается малой, если она меньше, чем [math]\sqrt{\epsilon} \Vert A \Vert_2[/math], так как в этом случае, согласно теореме Пейджа, компонента [math]\Vert y_{i,k}^T q_{k+1} \Vert = \Vert y_{i,k}^T z \Vert / \Vert z \Vert_2[/math] скорее всего превосходит уровень [math]\sqrt{\epsilon}[/math] (на практике используется [math]\Vert T_k \Vert_2[/math] вместо [math]\Vert A \Vert_2[/math], так как первое известно, а второе не всегда).
1.3 Вычислительное ядро алгоритма
У описанного алгоритма два ядра, на которые приходится основное время работы алгоритма:
- Вычисление вектора [math]z = A q_j[/math]
- Выборочная переортогонализация [math]z = z - (y_{i,k} ^ T z) y_{i,k}[/math]
При больших [math]k[/math], сопоставимых с [math]n[/math] , к вычислительному ядру можно отнести вычисление собственных значений и собственных векторов трёхдиагональной матрицы. Однако на практике [math]k[/math] много меньше [math]n[/math].
1.4 Макроструктура алгоритма
Макроструктура алгоритма Ланцоша с выборочной переортогонализацией представляется в виде совокупности метода Ланцоша с выборочной переортогонализацией построения крыловского подпространства и процедуры Рэлея-Ритца.
Каждая итерация первого этапа может быть разложена на следующие макроединицы:
1 Умножение матрицы на вектор, [math]z=Aq_j[/math].
2. Вычисление вектора [math]q_{j+1} [/math] с помощью линейной комбинации других векторов:
[math]\alpha_j=q_j^Tz, [/math]
[math]z=z-\alpha_jq_j-\beta_{j-1}q_{j-1}, [/math]
[math]q_{j+1}=z/\|z\|_2[/math]
3. Ортогонализация вектора Ланцоша с помощью скалярного произведения:
[math]z = z-(y^T_{i,k},z)y_{i,k} [/math]
4. Нахождении собственных значений и собственных векторов матрицы и интерпретации их как приближенных значений собственных чисел и собственных векторов исходной матрицы, он может быть выполнен любым способом, например, разделяй и властвуй или же QR-итерацией.
1.5 Схема реализации последовательного алгоритма
На вход алгоритму подаются исходная матрица [math]A[/math], вектор начального приближения [math]b[/math] и число [math]k[/math].
Далее последовательно выполняются итерационно для всех [math]j: 1 \le j \le k[/math] следующие шаги:
- Умножается матрица на вектор для нахождения вектора [math]z[/math]
- Вычисляется коэффициент [math]\alpha_j[/math] посредством скалярного перемножения векторов
- Вычисляется новое значение вектора [math]z[/math]
- Производятся оценка погрешностей [math]\beta_k \Vert v_i(k) \Vert[/math] и выборочная переортогонализация
- Вычисление очередного значения [math]\beta_j[/math] - норма вектора [math]z[/math]
- Вычисление и добавление к матрице [math]Q[/math] нового столбца
- Вычисление собственных значений и собственных векторов матрицы [math]T_j[/math]
1.6 Последовательная сложность алгоритма
- Вычисление вектора [math]z[/math] - [math]n^2[/math] операций умножения и [math]n(n-1)[/math] операций сложения
- Вычисление скалярного произведения векторов - [math]n[/math] операций умножения и [math](n-1)[/math] сложений
- Вычисление вектора [math]z[/math] - [math]2n[/math] умножений и [math]2n[/math] сложений
- Оценка погрешностей - [math]kn[/math] операций умножения
- Выборочная переортогонализация - [math]O(2nj)[/math] умножений и [math]O(2j(n-1) + n)[/math] сложений
- Вычисление нормы вектора - [math]n[/math] операций умножения и [math](n-1)[/math] сложений
- Вычисление нового столбца матрицы [math]Q[/math] - [math]n[/math] операций умножения
Итого на каждой итерации:
- Умножений: [math]n^2 + n + 2n + kn + O(2nj) + n + n = n^2 + 5n + kn + O(2nj)[/math]
- Сложений: [math]n(n-1) + n-1 + 2n + O(2j(n-1) + n) + n-1 = n^2 + 3n + O(2j(n-1) + n) -2[/math]
Итого за все время выполнения алгоритма:
- Умножений: [math]kn^2 + 5kn + k^2n + O(k^2n + kn)[/math]
- Сложений: [math]kn^2 + 3kn + O((k^2+k)(n-1)+kn) = kn^2 + 3kn + O(k^2(n-1)+2kn-k)[/math]
Суммарная последовательная сложность алгоритма - [math]O(kn^2 + k^2n)[/math].
1.7 Информационный граф

рис. 1: Информационный граф
1.8 Ресурс параллелизма алгоритма
Поскольку алгоритм является итерационным, то выполнять параллельные операции возможно только внутри каждой итерации алгоритма. Сами итерации выполняются в строгой последовательности и не могут быть параллелизованны:
- Вычисление вектора [math]z[/math] - умножение матрицы размера [math]n \times n[/math] на вектор длины [math]n[/math] - [math]n[/math] ярусов сложений, [math]n[/math] операций умножений в каждом
- Вычисление коэффициента [math]\alpha_j[/math] - скалярное произведение векторов - [math]n[/math] ярусов сложений, 1 операция умножения в каждом
- Вычисление нового значения вектора [math]z[/math]: 2 яруса умножений длины [math]n[/math] (умножение вектора на число), 2 яруса вычитаний длины [math]n[/math]
- Выборочная переортогонализация: последовательно для всех [math]i \le k[/math] выполняется [math]j[/math] ярусов сложений, [math]n[/math] операций умножений в каждом, [math]n[/math] ярусов сложений, [math]j[/math] операций умножений в каждом, один ярус вычитаний размера [math]n[/math]
- Вычисление [math]\beta_j[/math] - скалярное произведение векторов - [math]n[/math] ярусов сложений, 1 операция умножения в каждом
- Вычисление [math]q_j[/math] - деление вектора на число - один ярус делений размера [math]n[/math]
Сложность алгоритма по ширине ярусно параллельной формы - [math]O(n)[/math].
1.9 Входные и выходные данные алгоритма
Входные данные
Вещественная матрица [math]A[/math] размера [math]n \times n[/math], вектор [math]b[/math] длины [math]n[/math], число [math]k[/math], но учитывая что матрица у нас симметричная количество входных данных можно уменьшить в два раза.
Объем входных данных: [math]{n (n + 1) \over 2} + n + 1[/math]
Выходные данные
Матрица собственных значений [math] \Lambda = diag(\theta_1 \dots \theta_k) [/math], матрица собственных векторов [math] V = [v_1 \dots v_k] [/math] размера [math] n \times k [/math]
Так, объем выходных данных: [math] k + kn [/math]
1.10 Свойства алгоритма
- Преимуществом алгоритма является то, что он начинает поиск собственных значений матрицы начиная с максимального в абсолютном смысле значения. Это выгодно отличает данный алгоритм с точки зрения поиска собственных значений матрицы, находящихся по краям её спектра.
- Вычислительная мощность алгоритма - отношение числа операций к суммарному объему входных и выходных данных - примерно равно [math]2k[/math] при [math]k \lt \lt n[/math]
- Алгоритм устойчив, так как операция переортогонализации как раз направлена на исключение проблемы округления вычисляемых значений
- Алгоритм не является детерминированным, так как, во-первых, используется для разряженных матриц, и, во-вторых, является итерационным с выходом по точности - число операций заранее не определено
2 Программная реализация алгоритма
2.1 Особенности реализации последовательного алгоритма
2.2 Локальность данных и вычислений
2.3 Возможные способы и особенности параллельной реализации алгоритма
2.4 Масштабируемость алгоритма и его реализации
Исследование масштабируемости алгоритма проводилось на суперкомпьютере IBM Blue Gene/P ВМК МГУ.
Для компиляции программы использовались компиляторы intel/15.0.090 и Openmpi/1.8.4-icc.
Для проведения расчетов и получения полноценной картины поведения алгоритма в зависимости от входных данных и числа процессоров, программа была запущена на следующих параметрах:
- в качестве размера входной матрицы подавались значения в диапазоне [2000:30000] c шагом 2000.
- Число процессоров варьировалось от 1 до 256.
Ниже на рисунке изображен трехмерный график, показывающий зависимость времени выполнения программы от входных данных/
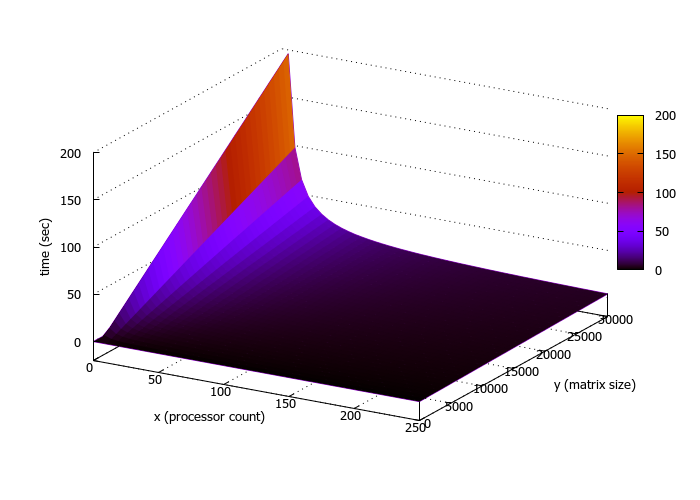
График зависимости времени выполнения программы от входных данных
ссылка код
2.5 Динамические характеристики и эффективность реализации алгоритма
2.6 Выводы для классов архитектур
2.7 Существующие реализации алгоритма
Алгоритм Ланцоша реализован в различных пакетах, библиотеках и проектах
NAG Library http://www.nag.com/content/nag-library C, C++, Fortran, C#, MATLAB, R
ARPACK https://people.sc.fsu.edu/~jburkardt/m_src/arpack/arpack.html MATLAB
GrapLab https://turi.com/products/create/open_source.html C++
Gaussian Belief Propagation Matlab Package http://www.cs.cmu.edu/~bickson/gabp/ MATLAB
The IETL Project http://www.comp-phys.org/software/ietl/ C++
LANSO/PLANSO http://web.cs.ucdavis.edu/~bai/ET/lanczos_methods/overview_PLANSO.html Fortran
Julia Math https://github.com/JuliaMath/IterativeSolvers.jl Julia
3 Литература
- Дж. Деммель, Вычислительная линейная алгебра. Теория и приложения. Пер. с англ. - М.: Мир, 2001.

