Участник:Артем Таран/Графо-ориентированный алгоритм кластеризации CHAMELEON: различия между версиями
Kronberg (обсуждение | вклад) |
|||
| (не показаны 62 промежуточные версии 3 участников) | |||
| Строка 1: | Строка 1: | ||
| + | {{Assignment|Algoman|Kronberg}} | ||
| + | |||
{{algorithm | {{algorithm | ||
| name = Графо-ориентированный алгоритм кластеризации CHAMELEON | | name = Графо-ориентированный алгоритм кластеризации CHAMELEON | ||
| serial_complexity = <math>O(n^2+nm+m^2log(m))</math> | | serial_complexity = <math>O(n^2+nm+m^2log(m))</math> | ||
| − | | pf_height = <math>O(n + log(n) + m^2log(m))</math> | + | | pf_height = <math>O(n + log(n) + mlog(m) + m^2log(m))</math> |
| pf_width = <math>O(n)</math> | | pf_width = <math>O(n)</math> | ||
| input_data = <math>\frac{n (n - 1)}{2}</math> | | input_data = <math>\frac{n (n - 1)}{2}</math> | ||
| Строка 8: | Строка 10: | ||
}} | }} | ||
| − | Статью подготовили: [[Участник:Артем_Таран|Артём Таран Иванович]]( разделы 1.1 - 1.10), [[Участник:ShimchikN|Шимчик Никита Владимирович]]( разделы 1.1 - 1.10). | + | Статью подготовили: [[Участник:Артем_Таран|Артём Таран Иванович]] (разделы 1.1 - 1.10, 2.7), [[Участник:ShimchikN|Шимчик Никита Владимирович]] (разделы 1.1 - 1.10, 2.7). |
== Свойства и структура алгоритма == | == Свойства и структура алгоритма == | ||
| Строка 15: | Строка 17: | ||
Кластеризация — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры) с минимизацией межкластерного сходства и максимизацией внутрикластерного сходства. | Кластеризация — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры) с минимизацией межкластерного сходства и максимизацией внутрикластерного сходства. | ||
| − | Графо-ориентированный алгоритм кластеризации CHAMELEON - | + | Графо-ориентированный алгоритм кластеризации CHAMELEON<ref name="rt">http://www-users.cs.umn.edu/~han/dmclass/chameleon.pdf</ref> - алгоритм, который измеряет сходство двух кластеров на основе |
динамической модели. В процессе кластеризации два кластера объединяются, только если показатели взаимосвязанности и близости между двумя кластерами являются высокими по отношению к показателям внутренней взаимосвязанности кластеров и близости элементов внутри этих кластеров. Процесс слияния с использованием динамической модели, использующийся в данном алгоритме облегчает открытие | динамической модели. В процессе кластеризации два кластера объединяются, только если показатели взаимосвязанности и близости между двумя кластерами являются высокими по отношению к показателям внутренней взаимосвязанности кластеров и близости элементов внутри этих кластеров. Процесс слияния с использованием динамической модели, использующийся в данном алгоритме облегчает открытие | ||
природных и однородных кластеров. Методология динамического моделирования кластеров, использующаяся в CHAMELEON, | природных и однородных кластеров. Методология динамического моделирования кластеров, использующаяся в CHAMELEON, | ||
применима ко всем типам данных, для которых может быть построена матрица подобия. | применима ко всем типам данных, для которых может быть построена матрица подобия. | ||
| + | |||
| + | Следует отметить, что конечное число кластеров не задаётся явным образом и зависит как от выбора параметров алгоритма, так и от внутренней структуры входных данных. | ||
Алгоритм кластеризации CHAMELEON включает в себя три этапа: | Алгоритм кластеризации CHAMELEON включает в себя три этапа: | ||
| Строка 27: | Строка 31: | ||
3) Формирование набора кластеров, на основе множества подграфов, полученных на предыдущем этапе. | 3) Формирование набора кластеров, на основе множества подграфов, полученных на предыдущем этапе. | ||
| + | |||
| + | [[Файл:Графы k ближайших соседей.jpg|1000px|thumb|center|Графы k ближайших соседей: 1) объекты в пространстве, 2) граф по принципу 1-го ближайшего соседа, 3) граф по принципу 2-го ближайшего соседа, 4) граф по принципу 3-х ближайших соседей<ref name="rt">http://www-users.cs.umn.edu/~han/dmclass/chameleon.pdf</ref>]] | ||
=== Математическое описание алгоритма === | === Математическое описание алгоритма === | ||
==== Данные ==== | ==== Данные ==== | ||
| − | * '''Исходные данные''': множество из <math>n</math> точек <math>V = \{v_{i}\}</math> в метрическом пространстве, которое может быть задано в виде треугольной матрицы расстояний <math>A</math> размера <math>n\times n</math>. | + | * '''Исходные данные''': множество из <math>n</math> точек <math>V = \{v_{i}\}</math> в метрическом пространстве, которое может быть задано в виде треугольной матрицы расстояний <math>A</math> размера <math>n\times n</math>; натуральное число <math>k</math>, используемое в качестве параметра алгоритма поиска k ближайших соседей. |
* '''Промежуточный результат после первого этапа''': граф <math>G = (V, E)</math>, полученный путём соединения каждой точки с её <math>k</math> ближайшими соседями. | * '''Промежуточный результат после первого этапа''': граф <math>G = (V, E)</math>, полученный путём соединения каждой точки с её <math>k</math> ближайшими соседями. | ||
| Строка 72: | Строка 78: | ||
<math>RI_{(C_{i},C_{j})}*RC_{(C_{i},C_{j})}^\alpha</math>, | <math>RI_{(C_{i},C_{j})}*RC_{(C_{i},C_{j})}^\alpha</math>, | ||
| − | где <math>\alpha</math> выбирается пользователем. Если <math>\alpha > 1 </math>, то алгоритм придает большее значение относительному взаимному сходству, а если <math>\alpha < 1 </math>, то большее значение имеет относительная взаимная связность. Разумеется, данный подход позволяет получить полную дендрограмму кластерного анализа. | + | где <math>\alpha</math> выбирается пользователем. Если <math>\alpha > 1 </math>, то алгоритм придает большее значение относительному взаимному сходству, а если <math>\alpha < 1 </math>, то большее значение имеет относительная взаимная связность. Разумеется, данный подход позволяет получить полную дендрограмму кластерного анализа<ref name="rty">http://studopedia.ru/7_41934_algoritm-dinamicheskoy-ierarhicheskoy-klasterizatsii-CHAMELEON.html</ref>. |
=== Вычислительное ядро алгоритма === | === Вычислительное ядро алгоритма === | ||
| Строка 101: | Строка 107: | ||
integer E[n][n]; // Верхняя треугольная матрица рёбер графа G - изначально инициализирована нулями. | integer E[n][n]; // Верхняя треугольная матрица рёбер графа G - изначально инициализирована нулями. | ||
foreach (integer i in (1,n-1) ) { | foreach (integer i in (1,n-1) ) { | ||
| − | integer | + | integer Neighbours[k]; // матрица, используемая хранения ближайших соседей |
integer countN = 0; | integer countN = 0; | ||
foreach (integer j in (i+1, n) ) { | foreach (integer j in (i+1, n) ) { | ||
| − | // Заполняем матрицу | + | // Заполняем матрицу Neighbours, добавляя новые элементы и увеличивая счётчик countN. |
// Когда countN станет равен k, новые элементы будут вставляться на место старых, либо отбрасываться. | // Когда countN станет равен k, новые элементы будут вставляться на место старых, либо отбрасываться. | ||
} | } | ||
| Строка 131: | Строка 137: | ||
=== Информационный граф === | === Информационный граф === | ||
| + | |||
| + | [[File:Chameleon_inforgraph.png|811px]] | ||
=== Ресурс параллелизма алгоритма === | === Ресурс параллелизма алгоритма === | ||
| − | Первый этап работы алгоритма можно распределить между <math>n</math> процессами: в этом случае каждому процессу назначается своя точка и происходит поиск <math>k</math> ближайших соседей. Таким образом, его параллельная сложность составляет O(n). | + | Первый этап работы алгоритма можно распределить между <math>n</math> процессами: в этом случае каждому процессу назначается своя точка и происходит поиск <math>k</math> ближайших соседей. Таким образом, его параллельная сложность составляет <math>O(n)</math>. |
На втором этапе количество задействованных процессов может варьироваться в зависимости от входных данных. В худшем случае число итераций можно оценить как <math>O(log(n))</math>. | На втором этапе количество задействованных процессов может варьироваться в зависимости от входных данных. В худшем случае число итераций можно оценить как <math>O(log(n))</math>. | ||
| − | + | На третьем этапе можно распараллелить процесс расчёта метрик сходства между кластерами, однако итоговое слияние всё равно должно выполняться последовательно. | |
| + | Поскольку процесс сравнения кластеров возможно распараллелить, сложность 3-го этапа составляет <math>mlog(m) + m^2log(m)</math>. | ||
| − | Таким образом, суммарная параллельная сложность оказывается равна <math>O(n + log(n) + m^2log(m))</math> | + | Таким образом, суммарная параллельная сложность оказывается равна <math>O(n + log(n) + mlog(m) + m^2log(m))</math>. |
=== Входные и выходные данные алгоритма === | === Входные и выходные данные алгоритма === | ||
| Строка 162: | Строка 171: | ||
Первый этап алгоритма обладает хорошим ресурсом параллелизма: параллельная сложность его выполнения составляет <math>O(n)</math>, что намного лучше последовательной оценки <math>O(n^2)</math>. | Первый этап алгоритма обладает хорошим ресурсом параллелизма: параллельная сложность его выполнения составляет <math>O(n)</math>, что намного лучше последовательной оценки <math>O(n^2)</math>. | ||
| + | У второго и третьего этапов алгоритма сложно полностью оценить ресурсы параллелизма. Но оба этапа возможно частично распараллелить. | ||
| + | '''Вычислительную мощность''' для разных этапов алгоритма можно оценить как: | ||
| + | |||
| + | 1 этап: <math>O(1)</math> | ||
| + | |||
| + | 2 этап: <math>O(\frac{nm}{n^2+m^2})</math> | ||
| + | |||
| + | 3 этап: <math>O(\frac{m^2log(m)}{m^2+n})</math> | ||
| + | |||
| + | <b>Детерминированность:</b> Важной особенностью данного алгоритма является его недетерминированность. Несмотря на то, что 1-й этап детерминирован, алгоритм в целом является недетерминированным, так как на 2-ом этапе могут быть найдены различные разбиения на подграфы, а это повлияет и на итоговый результат работы алгоритма. | ||
== Программная реализация алгоритма == | == Программная реализация алгоритма == | ||
| Строка 173: | Строка 192: | ||
=== Масштабируемость алгоритма и его реализации === | === Масштабируемость алгоритма и его реализации === | ||
| + | |||
| + | Проводилось исследование масштабируемости экспериментальной версии параллельной реализации алгоритма для малого числа потоков<ref name="tr">http://research.ijcaonline.org/volume79/number8/pxc3891600.pdf</ref>. | ||
| + | |||
| + | Его результаты отражены на графиках. Из графиков видно, что ускорение и эффективность алгоритма растут с увеличением объема данных. | ||
| + | |||
| + | Однако можно заметить, что с увеличением числа потоков эффективность алгоритма падает. | ||
| + | |||
| + | [[File:Plot cham.jpg|850px|center]] | ||
| + | |||
| + | [[File:Cham_speedup.png]] [[File:Cham_eff.png]] | ||
=== Динамические характеристики и эффективность реализации алгоритма === | === Динамические характеристики и эффективность реализации алгоритма === | ||
| Строка 180: | Строка 209: | ||
=== Существующие реализации алгоритма === | === Существующие реализации алгоритма === | ||
| − | Существует несколько последовательных реализаций алгоритма. С одной из них можно ознакомиться по ссылке | + | Существует несколько последовательных реализаций алгоритма. С одной из них можно ознакомиться по ссылке <ref name="tra">http://www.codeforge.com/article/192925</ref>. |
| − | Возможна реализация алгоритма CHAMELEON с использованием графовых библиотек, как, например METIS | + | Возможна реализация алгоритма CHAMELEON с использованием графовых библиотек, как, например METIS <ref name="tru">http://glaros.dtc.umn.edu/gkhome/metis/metis/overview</ref> , hMETIS <ref name="tri">http://glaros.dtc.umn.edu/gkhome/metis/hmetis/overview</ref> и RANN <ref name="tro">https://cran.r-project.org/web/packages/RANN/index.html</ref>. |
| − | Параллельных реализаций алгоритма CHAMELEON найдено не было. Однако существует исследование, связанное с реализацией CHAMELEON посредством технологии OpenMP, с которым можно ознакомиться здесь | + | Параллельных реализаций алгоритма CHAMELEON найдено не было. Однако существует исследование, связанное с реализацией CHAMELEON посредством технологии OpenMP, с которым можно ознакомиться здесь <ref name="tr">http://research.ijcaonline.org/volume79/number8/pxc3891600.pdf</ref>. |
== Литература == | == Литература == | ||
| − | + | <references \> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
Текущая версия на 17:31, 29 ноября 2016
 | Эта работа успешно выполнена Преподавателю: в основное пространство, в подстраницу Данное задание было проверено и зачтено. Проверено Kronberg и Algoman. |
| Графо-ориентированный алгоритм кластеризации CHAMELEON | |
| Последовательный алгоритм | |
| Последовательная сложность | [math]O(n^2+nm+m^2log(m))[/math] |
| Объём входных данных | [math]\frac{n (n - 1)}{2}[/math] |
| Объём выходных данных | [math]n[/math] |
| Параллельный алгоритм | |
| Высота ярусно-параллельной формы | [math]O(n + log(n) + mlog(m) + m^2log(m))[/math] |
| Ширина ярусно-параллельной формы | [math]O(n)[/math] |
Статью подготовили: Артём Таран Иванович (разделы 1.1 - 1.10, 2.7), Шимчик Никита Владимирович (разделы 1.1 - 1.10, 2.7).
Содержание
- 1 Свойства и структура алгоритма
- 1.1 Общее описание алгоритма
- 1.2 Математическое описание алгоритма
- 1.3 Вычислительное ядро алгоритма
- 1.4 Макроструктура алгоритма
- 1.5 Схема реализации последовательного алгоритма
- 1.6 Последовательная сложность алгоритма
- 1.7 Информационный граф
- 1.8 Ресурс параллелизма алгоритма
- 1.9 Входные и выходные данные алгоритма
- 1.10 Свойства алгоритма
- 2 Программная реализация алгоритма
- 2.1 Особенности реализации последовательного алгоритма
- 2.2 Локальность данных и вычислений
- 2.3 Возможные способы и особенности параллельной реализации алгоритма
- 2.4 Масштабируемость алгоритма и его реализации
- 2.5 Динамические характеристики и эффективность реализации алгоритма
- 2.6 Выводы для классов архитектур
- 2.7 Существующие реализации алгоритма
- 3 Литература
1 Свойства и структура алгоритма
1.1 Общее описание алгоритма
Кластеризация — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы (кластеры) с минимизацией межкластерного сходства и максимизацией внутрикластерного сходства.
Графо-ориентированный алгоритм кластеризации CHAMELEON[1] - алгоритм, который измеряет сходство двух кластеров на основе динамической модели. В процессе кластеризации два кластера объединяются, только если показатели взаимосвязанности и близости между двумя кластерами являются высокими по отношению к показателям внутренней взаимосвязанности кластеров и близости элементов внутри этих кластеров. Процесс слияния с использованием динамической модели, использующийся в данном алгоритме облегчает открытие природных и однородных кластеров. Методология динамического моделирования кластеров, использующаяся в CHAMELEON, применима ко всем типам данных, для которых может быть построена матрица подобия.
Следует отметить, что конечное число кластеров не задаётся явным образом и зависит как от выбора параметров алгоритма, так и от внутренней структуры входных данных.
Алгоритм кластеризации CHAMELEON включает в себя три этапа:
1) Построение графа, путём добавления рёбер по принципу k ближайших соседей.
2) Выделение множества сравнительно малых связных подграфов.
3) Формирование набора кластеров, на основе множества подграфов, полученных на предыдущем этапе.

1.2 Математическое описание алгоритма
1.2.1 Данные
- Исходные данные: множество из [math]n[/math] точек [math]V = \{v_{i}\}[/math] в метрическом пространстве, которое может быть задано в виде треугольной матрицы расстояний [math]A[/math] размера [math]n\times n[/math]; натуральное число [math]k[/math], используемое в качестве параметра алгоритма поиска k ближайших соседей.
- Промежуточный результат после первого этапа: граф [math]G = (V, E)[/math], полученный путём соединения каждой точки с её [math]k[/math] ближайшими соседями.
- Промежуточный результат после второго этапа: разбиение множества [math]V[/math] на набор [math]K = \{K_{i}\}[/math] попарно непересекающихся связных подмножеств, из которого образуется взвешенный граф [math]G_{2} = (K, E_{2})[/math].
- Промежуточный результат после третьего этапа: итоговое разбиение множества вершин графа [math]G_{2}[/math] на набор кластеров [math]C = \{C_{i}\}[/math].
- Вычисляемые данные: n-мерный вектор [math]v[/math] (элементы [math]v_{i}[/math]), показывающий отображение исходного множества точек на набор кластеров [math]C[/math].
1.2.2 Определения
- Абсолютная взаимная связность между парой кластеров [math]C_{i}[/math] и [math]C_{j}[/math] определяется как сумма весов ребер, соединяющих вершины, принадлежащие [math]C_{i}[/math] с вершинами из [math]C_{j}[/math]. Эти ребра, фактически, входят в разделитель ребер графа, состоящего из кластеров [math]C_{i}[/math] и [math]C_{j}[/math], и разбивающим его на подграфы [math]C_{i}[/math] и [math]C_{j}[/math]. Обозначается эта величина как
[math]EC_{(C_{i},C_{j})}[/math]. Внутреннюю связность [math]EC_{C_{i}}[/math] кластера [math]C_{i}[/math] можно вычислить как сумму ребер, входящих в разделитель ребер, разбивающий [math]C_{i}[/math] на два совершенно равных подграфа.
- Относительная взаимная [math]RI_{(C_{i},C_{j})}[/math] связность пары кластеров [math]C_{i}[/math] и [math]C_{j}[/math] определяется формулой:
[math]RI_{(C_{i},C_{j})} = \frac{2*|EC_{(C_{i},C_{j})}|}{|EC_{C_{i}}|+|EC_{C_{j}}|}[/math]
Учитывая значения относительной взаимной связности, можно добиться получения кластеров разного размера, формы и плотности, то есть общего внутреннего сходства.
- Абсолютное взаимное сходство между парой кластеров [math]C_{i}[/math] и [math]C_{j}[/math] подсчитывается как среднее сходство между соединенными вершинами, принадлежащими [math]C_{i}[/math] и [math]C_{j}[/math] соответственно. Эти соединения обусловлены предыдущим разбиением общего графа, полученного на матрице сходства.
- Относительное взаимное сходство [math]RC_{(C_{i},C_{j})}[/math] между парой кластеров [math]C_{i}[/math] и [math]C_{j}[/math] определяется как абсолютное сходство между этой парой кластеров, нормализованное с учетом их внутреннего сходства и вычисляется по формуле:
[math] RC_{(C_{i},C_{j})}= \frac{S_{EC_{(C_{i},C_{j})}}}{\frac{|C_{i}|}{|C_{i}+C_{j}|}*S_{EC_{(C_{i})}}+\frac{|C_{i}|}{|C_{i}+C_{j}|}*S_{EC_{(C_{j})}}}[/math],
где [math]S_{EC_{(C_{i})}}[/math] и [math]S_{EC_{(C_{i})}}[/math] - средние веса ребер (значения сходства), принадлежащих разделителю ребер кластеров [math]C_{i}[/math] и [math]C_{j}[/math] соответственно, и [math]S_{EC_{(C_{i},C_{j})}}[/math] - средний вес ребер, соединяющих вершины [math]C_{i}[/math] с вершинами [math]C_{j}[/math], причем ребра принадлежат разделителю ребер [math]EC_{(C_{i})}[/math], определенному ранее.
Далее, алгоритм применяет агломеративную иерархическую кластеризацию с использованием вышеозначенных показателей. Причем существует две стратегии их учета. Первая подразумевает наличие некоторых пороговых значений [math]T_{RI}[/math] и [math]T_{RC}[/math]. В соответствии с этой стратегией, алгоритм для каждого кластера [math]C_{i}[/math] проверяет, отвечают ли смежные (наиболее близкие) ему кластеры условиям:
- [math]RI_{(C_{i},C_{j})} \geqslant T_{RI}[/math]
- [math]RC_{(C_{i},C_{j})} \geqslant T_{RC}[/math]
Если более одного смежного кластера отвечает этим условиям, то алгоритм выбирает для объединения наиболее связный кластер (граф), то есть такой кластер [math]C_{j}[/math], с которым у кластера [math]C_{i}[/math] получается наибольшая абсолютная взаимная связность. По завершению прохода по всем кластерам, созданные таким образом пары объединяются. Параметры [math]T_{RI}[/math] и [math]T_{RC}[/math] могут использоваться для изменения характеристик получаемых кластеров.
Вторая стратегия заключается в использовании специальной функции, объединяющей понятия относительной взаимной связности и относительного взаимного сходства. На каждом шаге выбираются те кластеры для объединения, которые максимизируют эту функцию:
[math]RI_{(C_{i},C_{j})}*RC_{(C_{i},C_{j})}^\alpha[/math],
где [math]\alpha[/math] выбирается пользователем. Если [math]\alpha \gt 1 [/math], то алгоритм придает большее значение относительному взаимному сходству, а если [math]\alpha \lt 1 [/math], то большее значение имеет относительная взаимная связность. Разумеется, данный подход позволяет получить полную дендрограмму кластерного анализа[2].
1.3 Вычислительное ядро алгоритма
На первом этапе работы алгоритма вычислительным ядром можно считать процесс нахождения k ближайших соседей для каждой отдельной вершины.
На втором этапе работы алгоритма вычислительным ядром является поиск разбиения графа на два подграфа с минимизацией разделителя рёбер графа.
На третьем этапе работы алгоритма вычислительным ядром является расчёт [math]EC_{(C_{i},C_{j})}[/math], [math]RC_{(C_{i},C_{j})}[/math] и [math]RI_{(C_{i},C_{j})}[/math] для пары смежных кластеров, а также их слияние.
1.4 Макроструктура алгоритма
Алгоритм CHAMELEON выполняется в 3 этапа, последовательных относительно друг друга. Каждый этап соответствует отдельному алгоритму.
- Макрооперацией на первом этапе является процедура выделения k ближайших соседей.
- Макрооперацией на втором этапе является процедура разбиения наибольшего подграфа на каждой итерации.
- Макрооперациями на третьем этапе являются процедуры вычисления метрики для принятия решения об объединении кластеров и объединение кластеров на каждой итерации.
1.5 Схема реализации последовательного алгоритма
- Первый этап (псевдокод):
integer n; // Количество точек.
integer k; // Параметр k
integer A[n][n]; // Верхняя треугольная матрица расстояний между точками.
integer E[n][n]; // Верхняя треугольная матрица рёбер графа G - изначально инициализирована нулями.
foreach (integer i in (1,n-1) ) {
integer Neighbours[k]; // матрица, используемая хранения ближайших соседей
integer countN = 0;
foreach (integer j in (i+1, n) ) {
// Заполняем матрицу Neighbours, добавляя новые элементы и увеличивая счётчик countN.
// Когда countN станет равен k, новые элементы будут вставляться на место старых, либо отбрасываться.
}
foreach (integer j in (0, countN) ) {
E[min(i,j), max(i,j)] = 1;
}
}
return E;
- Второй этап:


- Третий этап:


1.6 Последовательная сложность алгоритма
1) Построение графа на основе метода k ближайших соседей в худшем случае требует [math]O(n^2)[/math] операций;
2) Для выделения множества сравнительно малых связных подграфов требуется [math]nm[/math] операций;
3) Формирование набора кластеров, на основе множества подграфов, полученных на предыдущем этапе, требует [math]m^2log(m)[/math] операций.
Итого, получаем последовательную сложность [math]O(n^2+nm+m^2log(m))[/math].
1.7 Информационный граф
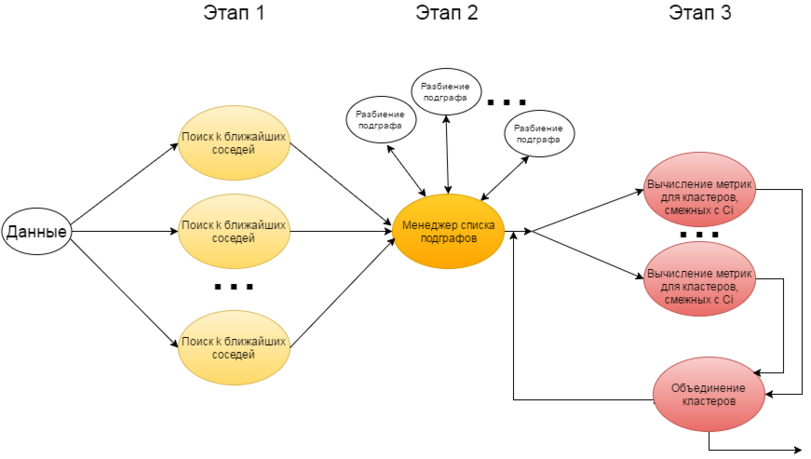

1.8 Ресурс параллелизма алгоритма
Первый этап работы алгоритма можно распределить между [math]n[/math] процессами: в этом случае каждому процессу назначается своя точка и происходит поиск [math]k[/math] ближайших соседей. Таким образом, его параллельная сложность составляет [math]O(n)[/math].
На втором этапе количество задействованных процессов может варьироваться в зависимости от входных данных. В худшем случае число итераций можно оценить как [math]O(log(n))[/math].
На третьем этапе можно распараллелить процесс расчёта метрик сходства между кластерами, однако итоговое слияние всё равно должно выполняться последовательно. Поскольку процесс сравнения кластеров возможно распараллелить, сложность 3-го этапа составляет [math]mlog(m) + m^2log(m)[/math].
Таким образом, суммарная параллельная сложность оказывается равна [math]O(n + log(n) + mlog(m) + m^2log(m))[/math].
1.9 Входные и выходные данные алгоритма
- Входные данные:
1) Треугольная матрица [math]A[/math] размера [math]n\times n[/math] (где n — количество объектов), в которой элементу [math]a_{ij}[/math] соответствует расстояние между i-м и j-м объектами.
2) Количество ближайших соседей [math]k[/math] для вершин (рекомендуемое значение [math]k[/math] от 5 до 20 в зависимости от количества анализируемых объектов).
3) Наименьшее число вершин, которое может содержать наибольший подграф на 2-м этапе [math]l[/math]. Величина этого параметра варьируется от 1 до 5 % от общего числа объектов.
- Объём входных данных: [math]\frac{n (n - 1)}{2}[/math]
- Выходные данные: n-мерный вектор [math]v[/math], в котором элементу [math]v_{i}[/math] соответствует номер кластера, присвоенный i-му объекту
- Объём выходных данных: [math]n[/math]
1.10 Свойства алгоритма
Первый этап алгоритма обладает хорошим ресурсом параллелизма: параллельная сложность его выполнения составляет [math]O(n)[/math], что намного лучше последовательной оценки [math]O(n^2)[/math].
У второго и третьего этапов алгоритма сложно полностью оценить ресурсы параллелизма. Но оба этапа возможно частично распараллелить.
Вычислительную мощность для разных этапов алгоритма можно оценить как:
1 этап: [math]O(1)[/math]
2 этап: [math]O(\frac{nm}{n^2+m^2})[/math]
3 этап: [math]O(\frac{m^2log(m)}{m^2+n})[/math]
Детерминированность: Важной особенностью данного алгоритма является его недетерминированность. Несмотря на то, что 1-й этап детерминирован, алгоритм в целом является недетерминированным, так как на 2-ом этапе могут быть найдены различные разбиения на подграфы, а это повлияет и на итоговый результат работы алгоритма.
2 Программная реализация алгоритма
2.1 Особенности реализации последовательного алгоритма
2.2 Локальность данных и вычислений
2.3 Возможные способы и особенности параллельной реализации алгоритма
2.4 Масштабируемость алгоритма и его реализации
Проводилось исследование масштабируемости экспериментальной версии параллельной реализации алгоритма для малого числа потоков[3].
Его результаты отражены на графиках. Из графиков видно, что ускорение и эффективность алгоритма растут с увеличением объема данных.
Однако можно заметить, что с увеличением числа потоков эффективность алгоритма падает.



2.5 Динамические характеристики и эффективность реализации алгоритма
2.6 Выводы для классов архитектур
2.7 Существующие реализации алгоритма
Существует несколько последовательных реализаций алгоритма. С одной из них можно ознакомиться по ссылке [4].
Возможна реализация алгоритма CHAMELEON с использованием графовых библиотек, как, например METIS [5] , hMETIS [6] и RANN [7].
Параллельных реализаций алгоритма CHAMELEON найдено не было. Однако существует исследование, связанное с реализацией CHAMELEON посредством технологии OpenMP, с которым можно ознакомиться здесь [3].
3 Литература
<references \>
- ↑ 1,0 1,1 http://www-users.cs.umn.edu/~han/dmclass/chameleon.pdf
- ↑ http://studopedia.ru/7_41934_algoritm-dinamicheskoy-ierarhicheskoy-klasterizatsii-CHAMELEON.html
- ↑ 3,0 3,1 http://research.ijcaonline.org/volume79/number8/pxc3891600.pdf
- ↑ http://www.codeforge.com/article/192925
- ↑ http://glaros.dtc.umn.edu/gkhome/metis/metis/overview
- ↑ http://glaros.dtc.umn.edu/gkhome/metis/hmetis/overview
- ↑ https://cran.r-project.org/web/packages/RANN/index.html