|
|
| (49 intermediate revisions by 3 users not shown) |
| Line 1: |
Line 1: |
| − | Primary authors of this description: [[:ru:Участник:Daryin|A.N.Daryin]], [[:ru:Участник:VadimVV|Vad.V.Voevodin]] ([[#Locality of data and computations|Section 2.2]]). | + | {{level-a}} |
| | + | Primary authors of this description: [[:ru:Участник:Daryin|A.N.Daryin]]. |
| | | | |
| | == Properties and structure of the algorithm == | | == Properties and structure of the algorithm == |
| Line 58: |
Line 59: |
| | === Serial complexity of the algorithm === | | === Serial complexity of the algorithm === |
| | | | |
| − | Последовательная сложность алгоритма равна <math>O(C_1 m + C_2n)</math>, где
| + | The serial complexity of the algorithm is <math>O(C_1 m + C_2n)</math>, where |
| − | * <math>C_1</math> – количество операций уменьшения расстояния до вершины; | + | * <math>C_1</math> is the number of operations for decreasing the distance to a node; |
| − | * <math>C_2</math> – количество операций вычисления минимума. | + | * <math>C_2</math> is the number of operations for calculating minima. |
| | | | |
| − | Оригинальный алгоритм Дейкстры использовал в качестве внутренней структуры данных списки, для которых <math>C_1 = O(1)</math>, <math>C_2 = O(n)</math>, так что общая сложность составляла <math>O(n^2)</math>.
| + | The original Dijkstra's algorithm used lists as an internal data structure. For such lists, <math>C_1 = O(1)</math>, <math>C_2 = O(n)</math>, and the total complexity is <math>O(n^2)</math>. |
| | | | |
| − | При использовании фибоначчиевой кучи<ref name=FibHeap /> время вычисления минимума сокращается до <math>C_2 = O(\ln n)</math>, так что общая сложность равна <math>O(m + n \ln n)</math>, что является асимптотически наилучшим известным результатом для данного класса задач.
| + | If Fibonacci heaps <ref name=FibHeap /> are used, then the time for calculating a minimum decreases to <math>C_2 = O(\ln n)</math> and the total complexity is <math>O(m + n \ln n)</math>, which, asymptotically, is the best known result for this class of problems. |
| | | | |
| | === Information graph === | | === Information graph === |
| | | | |
| − | Приводится граф алгоритма для базовой реализации алгоритма Дейкстры на списках или массивах.
| + | Figure 1 shows the graph of the basic implementation of Dijkstra's algorithm based on lists or arrays. |
| − | [[file:Deikstra.png|thumb|center|600px|Рисунок 1. Граф алгоритма без отображения входных и выходных данных. n=3. Желтым цветом обозначены операции сравнения, зеленым - операции изменения меток вершин, синим - пометка вершины.]] | + | [[file:Deikstra.png|thumb|center|600px|Figure 1. Information graph of Dijkstra's algorithm. The input and output data are not shown. n=3. Comparison operations, operations for changing node labels, and node labeling operations are indicated in yellow, green, and blue, respectively.]] |
| | | | |
| | === Parallelization resource of the algorithm === | | === Parallelization resource of the algorithm === |
| | | | |
| − | Алгоритм Дейкстры допускает эффективную параллелизацию<ref>Crauser, A, K Mehlhorn, U Meyer, and P Sanders. “A Parallelization of Dijkstra's Shortest Path Algorithm,” Proceedings of Mathematical Foundations of Computer Science / Lecture Notes in Computer Science, 1450:722–31, Berlin, Heidelberg: Springer, 1998. doi:10.1007/BFb0055823.</ref>, среднее время работы <math>O(n^{1/3}\ln n)</math> с объёмом вычислений <math>O(n \ln n + m)</math>.
| + | Dijkstra's algorithm admits an efficient parallelization <ref>Crauser, A, K Mehlhorn, U Meyer, and P Sanders. “A Parallelization of Dijkstra's Shortest Path Algorithm,” Proceedings of Mathematical Foundations of Computer Science / Lecture Notes in Computer Science, 1450:722–31, Berlin, Heidelberg: Springer, 1998. doi:10.1007/BFb0055823.</ref> Its average execution time is <math>O(n^{1/3}\ln n)</math>, and the computational complexity is <math>O(n \ln n + m)</math>. |
| | | | |
| − | [[Алгоритм Δ-шагания]] может рассматриваться как параллельная версия алгоритма Дейкстры. | + | The [[algorithm of Δ-stepping]] can be regarded as a parallel version of Dijkstra's algorithm. |
| | | | |
| | === Input and output data of the algorithm === | | === Input and output data of the algorithm === |
| | | | |
| − | '''Входные данные''': взвешенный граф <math>(V, E, W)</math> (<math>n</math> вершин <math>v_i</math> и <math>m</math> рёбер <math>e_j = (v^{(1)}_{j}, v^{(2)}_{j})</math> с весами <math>f_j</math>), вершина-источник <math>u</math>. | + | '''Input data''': weighted graph <math>(V, E, W)</math> (<math>n</math> nodes <math>v_i</math> and <math>m</math> arcs <math>e_j = (v^{(1)}_{j}, v^{(2)}_{j})</math> with weights <math>f_j</math>), source node <math>u</math>. |
| | | | |
| − | '''Объём входных данных''': <math>O(m + n)</math>. | + | '''Size of input data''': <math>O(m + n)</math>. |
| | | | |
| − | '''Выходные данные''' (возможные варианты): | + | '''Output data''' (possible variants): |
| − | # для каждой вершины <math>v</math> исходного графа – последнее ребро <math>e^*_v = (w, v)</math>, лежащее на кратчайшем пути от вершины <math>u</math> к <math>v</math>, или соответствующая вершина <math>w</math>; | + | |
| − | # для каждой вершины <math>v</math> исходного графа – суммарный вес <math>f^*(v)</math> кратчайшего пути от от вершины <math>u</math> к <math>v</math>. | + | # for each node <math>v</math> of the original graph, the last arc <math>e^*_v = (w, v)</math> lying on the shortest path from <math>u</math> to <math>v</math> or the corresponding node <math>w</math>; |
| | + | # for each node <math>v</math> of the original graph, the summarized weight <math>f^*(v)</math> of the shortest path from <math>u</math> to <math>v</math>. |
| | | | |
| − | '''Объём выходных данных''': <math>O(n)</math>. | + | '''Size of output data''': <math>O(n)</math>. |
| | | | |
| | === Properties of the algorithm === | | === Properties of the algorithm === |
| Line 94: |
Line 96: |
| | | | |
| | === Implementation peculiarities of the serial algorithm === | | === Implementation peculiarities of the serial algorithm === |
| − |
| |
| − | === Locality of data and computations ===
| |
| − | ==== Locality of implementation ====
| |
| − | ===== Structure of memory access and a qualitative estimation of locality =====
| |
| − |
| |
| − | [[file:dijkstra_1.png|thumb|center|700px|Рисунок 1. Реализация алгоритма Дейкстры. Общий профиль обращений в память]]
| |
| − |
| |
| − | На рис. 1 представлен профиль обращений в память для реализации алгоритма Дейкстры. Первое, что бросается в глаза, – большая разрозненность обращений. В частности, значительные области выше и ниже фрагмента 2 остаются пустыми, при этом сами обращения объединены лишь в небольшие группы. Это говорит о низкой эффективности, поскольку: а) повторные обращения практически отсутствуют и либо происходят через значительный промежуток времени; 2) расстояния между идущими подряд обращениями может быть очень большим.
| |
| − |
| |
| − | Однако при ближайшем рассмотрении может оказаться, что такие участки обладают высокой локальностью и состоят из значительного числа обращений. Более того, на общем профиле есть несколько областей (фрагменты 1 и 2), в которых обращения хорошо локализованы. Необходимо исследовать отдельные участки более подробно.
| |
| − |
| |
| − | Перейдем к изучению фрагмента 1 (рис. 2), в рамках которого выполняются обращения к двум небольшим массивам. Можно увидеть, что здесь задействованы только примерно 500 элементов, при этом к ним выполняется около 100 тысяч обращений. Весь профиль составляет около 120 тысяч обращений, поэтому получается, что подавляющая их часть выполняется именно к этим элементам.
| |
| − |
| |
| − | [[file:dijkstra_2.png|thumb|center|700px|Рисунок 2. Профиль обращений, фрагмент 1]]
| |
| − |
| |
| − | Поскольку число элементов невелико, локальность в данном случае заведомо будет достаточно высокой, независимо от структуры самого фрагмента. Однако на рис. 2, где представлены два участка из фрагмента 1, можно увидеть, что фрагмент в основном состоит из последовательных переборов, при этом данные зачастую задействованы повторно через не очень большие промежутки. Все это позволяет говорить, что данный фрагмент обладает высокой как пространственной, так и временной локальностью.
| |
| − |
| |
| − | [[file:dijkstra_3.png|thumb|center|700px|Рисунок 3. Профили двух участков фрагмента 1 (выделены зеленым на рис. 2)]]
| |
| − |
| |
| − | Рассмотрим теперь более подробно фрагмент 2 (рис. 4), в рамках которого выполняются обращения к еще служебному массиву. Здесь профиль состоит из двух этапов. На первом заметен достаточно хаотичный разброс обращений, напоминающий случайный доступ. На втором обращения образуют подобие последовательного перебора. В целом такой профиль характеризуется очень низкой временной локальностью (повторные обращения практически или полностью отсутствуют) и достаточно низкой пространственной локальностью (из-за случайного доступа на первом этапе).
| |
| − |
| |
| − | Заметим, что при этом число задействованных элементов здесь больше, чем во фрагменте 1, однако число обращений гораздо меньше.
| |
| − |
| |
| − | [[file:dijkstra_4.png|thumb|center|500px|Рисунок 4. Профиль обращений, фрагмент 2]]
| |
| − |
| |
| − | Далее остаются для рассмотрения два массива (область между фрагментами 1 и 2 и область ниже фрагмента 2). Характер обращений к этим массивам во многом похож, поэтому достаточно изучить более подробно только один из них.
| |
| − |
| |
| − | Фрагмент 3 рассмотрен на рис. 5. Этот участок отражают достаточно большую область, что не позволяет проанализировать профиль вплоть до отдельных обращений, однако здесь этого и не требуется. Из данного фрагмента видно, что основу профиля составляют участки с последовательным (или с небольшим шагом) перебором, состоящие из небольшого числа элементов – выделенный желтым самый большой фрагмента участок состоит всего из пары сотен обращений. При этом между разными участками расстояние может быть существенным. Все это говорит об очень низкой локальности (как пространственной, так и временной) в случае двух рассматриваемых массивов.
| |
| − |
| |
| − | [[file:dijkstra_5.png|thumb|center|500px|Рисунок 5. Профиль обращений, фрагмент 3]]
| |
| − |
| |
| − | В целом, несмотря на положительный вклад массивов из фрагмента 1, локальность общего профиля должна быть достаточно низкой, вследствие неэффективного использования данных в остальной части профиля.
| |
| − |
| |
| − | ===== Quantitative estimation of locality =====
| |
| − |
| |
| − | Основной фрагмент реализации, на основе которого были получены количественные оценки, приведен [http://git.parallel.ru/shvets.pavel.srcc/locality/blob/master/benchmarks/dijkstra/dijkstra.h здесь] (функция Kernel). Условия запуска описаны [http://git.parallel.ru/shvets.pavel.srcc/locality/blob/master/README.md здесь].
| |
| − |
| |
| − | Первая оценка выполняется на основе характеристики daps, которая оценивает число выполненных обращений (чтений и записей) в память в секунду. Данная характеристика является аналогом оценки flops применительно к работе с памятью и является в большей степени оценкой производительности взаимодействия с памятью, чем оценкой локальности. Однако она служит хорошим источником информации, в том числе для сравнения с результатами по следующей характеристике cvg.
| |
| − |
| |
| − | На рисунке 6 приведены значения daps для реализаций распространенных алгоритмов, отсортированные по возрастанию (чем больше daps, тем в общем случае выше производительность). Можно увидеть, что производительность работы с памятью достаточно низка. Это неудивительно, поскольку реализации алгоритмов над графами почти всегда обладают низкой эффективностью вследствие нерегулярности доступа к данным, что мы и увидели при анализе профиля обращений.
| |
| − |
| |
| − | [[file:dijkstra_daps.png|thumb|center|700px|Рисунок 6. Сравнение значений оценки daps]]
| |
| − |
| |
| − | Вторая характеристика – cvg – предназначена для получения более машинно-независимой оценки локальности. Она определяет, насколько часто в программе необходимо подтягивать данные в кэш-память. Соответственно, чем меньше значение cvg, тем реже это нужно делать, тем лучше локальность.
| |
| − |
| |
| − | На рисунке 7 приведены значения cvg для того же набора реализаций, отсортированные по убыванию (чем меньше cvg, тем в общем случае выше локальность). Можно увидеть, что в данном случае значение cvg хорошо коррелирует с оценкой производительности и отражает низкую локальность, что соответствует выводам, сделанным при качественной оценке локальности.
| |
| − |
| |
| − | [[file:dijkstra_cvg.png|thumb|center|700px|Рисунок 7. Сравнение значений оценки cvg]]
| |
| | | | |
| | === Possible methods and considerations for parallel implementation of the algorithm === | | === Possible methods and considerations for parallel implementation of the algorithm === |
| − | | + | === Run results === |
| − | === Scalability of the algorithm and its implementations === | |
| − | ==== Scalability of the algorithm ====
| |
| − | ==== Scalability of of the algorithm implementation ====
| |
| − | | |
| − | Проведём исследование масштабируемости параллельной реализации алгоритма согласно [[Scalability methodology|методике]]. Исследование проводилось на суперкомпьютере "Ломоносов"<ref name="Lom">Воеводин Вл., Жуматий С., Соболев С., Антонов А., Брызгалов П., Никитенко Д., Стефанов К., Воеводин Вад. Практика суперкомпьютера «Ломоносов» // Открытые системы, 2012, N 7, С. 36-39.</ref> [http://parallel.ru/cluster Суперкомпьютерного комплекса Московского университета].
| |
| − | Набор и границы значений изменяемых [[Глоссарий#Параметры запуска|параметров запуска]] реализации алгоритма:
| |
| − | | |
| − | * число процессоров [4, 8 : 128] со значениями квадрата целого числа;
| |
| − | * размер графа [16000:64000] с шагом 16000.
| |
| − | | |
| − | На следующем рисунке приведен график [[Глоссарий#Производительность|производительности]] выбранной реализации алгоритма в зависимости от изменяемых параметров запуска.
| |
| − | | |
| − | [[file:Dijkstra perf.png|thumb|center|700px|Рисунок 8. Параллельная реализация алгоритма. Изменение производительности в зависимости от числа процессоров и размера области.]]
| |
| − | | |
| − | В силу особенностей параллельной реализации алгоритма производительность в целом достаточно низкая и с ростом числа процессов увеличивается медленно, а при приближении к числу процессов 128 начинает уменьшаться.
| |
| − | Это объясняется использованием коллективных операций на каждой итерации алгоритма и тем, что затраты на коммуникационные обмены существенно возрастают с ростом числа использованных процессов. Вычисления на каждом процессе проходят достаточно быстро и потому декомпозиция графа слабо компенсирует эффект от затрат на коммуникационные обмены.
| |
| − | | |
| − | [https://code.google.com/p/prir-dijkstra-mpi/source/browse/trunk/project/dijkstra_mpi.c Исследованная параллельная реализация на языке C]
| |
| − | | |
| − | === Dynamic characteristics and efficiency of the algorithm implementation ===
| |
| − | | |
| − | Для проведения экспериментов использовалась реализация алгоритма Дейкстры. Все результаты получены на суперкомпьютере "Ломоносов". Использовались процессоры Intel Xeon X5570 с пиковой производительностью в 94 Гфлопс, а также компилятор intel 13.1.0.
| |
| − | На рисунках показана эффективность реализации алгоритма Дейкстры на 32 процессах.
| |
| − | | |
| − | [[file:Dijkstra CPU User.png|thumb|center|700px|Рисунок 9. График загрузки CPU при выполнении алгоритма Дейкстры]]
| |
| − | | |
| − | На графике загрузки процессора видно, что почти все время работы программы уровень загрузки составляет около 50%. Это указывает на равномерную загруженность вычислениями процессоров, при использовании 8 процессов на вычислительный узел и без использования Hyper Threading.
| |
| − | | |
| − | [[file:Dijkstra Flops.png|thumb|center|700px|Рисунок 10. График операций с плавающей точкой в секунду при выполнении алгоритма Дейкстры]]
| |
| − | | |
| − | На Рисунке 10 показан график количества операций с плавающей точкой в секунду. На графике видна общая очень низкая производительность вычислений около 250 Kфлопс в пике и около 150 Кфлопс в среднем по всем узлам. Это указывает то, что в программе почти все вычисления производятся с целыми числами.
| |
| − | [[file:Dijkstra L1.png|thumb|center|700px|Рисунок 11. График кэш-промахов L1 в секунду при работе алгоритма Дейкстры]]
| |
| − |
| |
| − | На графике кэш-промахов первого уровня видно, что число промахов очень большое для нескольких ядер и находится на уровне 15 млн/сек (в пике до 60 млн/сек), что указывает на интенсивные вычисления в части процессов. В среднем по всем узлам значения значительно ниже (около 9 млн/сек). Это указывает на неравномерное распределение вычислений.
| |
| − | [[file:Dijkstra L3.png|thumb|center|700px|Рисунок 12. График кэш-промахов L3 в секунду при работе алгоритма Дейкстры]]
| |
| − | | |
| − | На графике кэш-промахов третьего уровня видно, что число промахов очень немного и находится на уровне 1,2 млн/сек, однако в среднем по всем узлам значения около 0,5 млн/сек. Соотношение кэш промахов L1|L3 для процессов с высокой производительностью доходит до 60, однако в среднем около 30. Это указывает на очень хорошую локальность вычислений как у части процессов, так и для всех в среднем, и это является признаком высокой производительности.
| |
| − | [[file:Dijkstra Mem Load.png|thumb|center|700px|Рисунок 13. График количества чтений из оперативной памяти при работе алгоритма Дейкстры]]
| |
| − | | |
| − | На графике обращений в память видна достаточно типичная картина для таких приложений. Активность чтения достаточно низкая, что в совокупности с низкими значениями кэш-промахов L3 указывает на хорошую локальность. Хорошая локальность приложения так же указывает на то, что значения около 1 млн/сек для задачи является результатом высокой производительности вычислений, хотя и присутствует неравномерность между процессами.
| |
| − | [[file:Dijkstra Mem Store.png|thumb|center|700px|Рисунок 14. График количества записей в оперативную память при работе алгоритма Дейкстры]]
| |
| − | | |
| − | На графике записей в память видна похожая картина неравномерности вычислений, при которой одновременно активно выполняют запись только несколько процессов. Это коррелирует с другими графиками выполнения. Стоит отметить, достаточно низкое число обращений на запись в память. Это указывает на хорошую организацию вычислений, и достаточно эффективную работу с памятью.
| |
| − | [[file:Dijkstra Inf DATA.png|thumb|center|700px|Рисунок 15. График скорости передачи по сети Infiniband в байт/сек при работе алгоритма Дейкстры]]
| |
| − | | |
| − | На графике скорости передачи данных по сети Infiniband наблюдается достаточно высокая скорость передачи данных в байтах в секунду. Это говорит о том, что процессы между собой обмениваются интенсивно и вероятно достаточно малыми порциями данных, потому как производительность вычислений высока. Стоит отметить, что скорость передачи отличается между процессами, что указывает на дисбаланс вычислений.
| |
| − | [[file:Dijkstra Inf PCKTS.png|thumb|center|700px|Рисунок 16. График скорости передачи по сети Infiniband в пакетах/сек при работе алгоритма Дейкстры]]
| |
| − | | |
| − | На графике скорости передачи данных в пакетах в секунду наблюдается крайне высокая интенсивность передачи данных выраженная в пакетах в секунду. Это говорит о том, что, вероятно, процессы обмениваются не очень существенными объемами данных, но очень интенсивно. Используются коллективные операции на каждом шаге с небольшими порциями данных, что объясняет такую картину. Так же наблюдается почти меньший дизбаланс между процессами чем наблюдаемый в графиках использования памяти и вычислений и передачи данных в байтах/сек. Это указывает на то, что процессы обмениваются по алгоритму одинаковым числом пакетов, однако получают разные объемы данных и ведут неравномерные вычисления.
| |
| − | [[file:Dijkstra Load ABG.png|thumb|center|700px|Рисунок 17. График числа процессов, ожидающих вхождения в стадию счета (Loadavg), при работе алгоритма Дейкстры]]
| |
| − | На графике числа процессов, ожидающих вхождения в стадию счета (Loadavg), видно, что на протяжении всей работы программы значение этого параметра постоянно и приблизительно равняется 8. Это свидетельствует о стабильной работе программы с загруженными вычислениями всеми узлами. Это указывает на очень рациональную и статичную загрузку аппаратных ресурсов процессами. И показывает достаточно хорошую эффективность выполняемой реализации.
| |
| − | В целом, по данным системного мониторинга работы программы можно сделать вывод о том, что программа работала достаточно эффективно, и стабильно. Использование памяти очень интенсивное, а использование коммуникационной среды крайне интенсивное, при этом объемы передаваемых данных не являются высокими. Это указывает на требовательность к латентности коммуникационной среды алгоритмической части программы.
| |
| − | Низкая эффективность связана судя по всему с достаточно высоким объемом пересылок на каждом процессе, интенсивными обменами сообщениями.
| |
| − | | |
| | === Conclusions for different classes of computer architecture === | | === Conclusions for different classes of computer architecture === |
| − | === Existing implementations of the algorithm ===
| |
| − |
| |
| − | * C++: [http://www.boost.org/libs/graph/doc/ Boost Graph Library] (функции <code>[http://www.boost.org/libs/graph/doc/dijkstra_shortest_paths.html dijkstra_shortest_paths]</code>, <code>[http://www.boost.org/libs/graph/doc/dijkstra_shortest_paths_no_color_map.html dijkstra_shortest_paths_no_color_map]</code>), сложность <math>O(m + n \ln n)</math>.
| |
| − | * C++, MPI: [http://www.boost.org/libs/graph_parallel/doc/html/index.html Parallel Boost Graph Library]:
| |
| − | ** функция <code>[http://www.boost.org/libs/graph_parallel/doc/html/dijkstra_shortest_paths.html#eager-dijkstra-s-algorithm eager_dijkstra_shortest_paths]</code> – непосредственная реализация алгоритма Дейкстры;
| |
| − | ** функция <code>[http://www.boost.org/libs/graph_parallel/doc/html/dijkstra_shortest_paths.html#crauser-et-al-s-algorithm crauser_et_al_shortest_paths]</code> – реализация алгоритма Дейкстры в виде алгоритма из статьи Краузера и др.<ref>Crauser, A, K Mehlhorn, U Meyer, and P Sanders. “A Parallelization of Dijkstra's Shortest Path Algorithm,” Proceedings of Mathematical Foundations of Computer Science / Lecture Notes in Computer Science, 1450:722–31, Berlin, Heidelberg: Springer, 1998. doi:10.1007/BFb0055823.</ref>
| |
| − | * Python: [https://networkx.github.io NetworkX] (функция <code>[http://networkx.github.io/documentation/networkx-1.9.1/reference/generated/networkx.algorithms.shortest_paths.weighted.single_source_dijkstra.html single_source_dijkstra]</code>).
| |
| − | * Python/C++: [https://networkit.iti.kit.edu NetworKit] (класс <code>[https://networkit.iti.kit.edu/data/uploads/docs/NetworKit-Doc/python/html/graph.html#networkit.graph.Dijkstra networkit.graph.Dijkstra]</code>).
| |
| | | | |
| | == References == | | == References == |
Primary authors of this description: A.N.Daryin.
1 Properties and structure of the algorithm
1.1 General description of the algorithm
Dijkstra's algorithm[1] was designed for finding the shortest paths between nodes in a graph. For a given weighted digraph with nonnegative weights, the algorithm finds the shortest paths between a singled-out source node and the other nodes of the graph.
Dijkstra's algorithm (using Fibonacci heaps [2]) is executed in [math]O(m + n \ln n)[/math] time and, asymptotically, is the fastest of the known algorithms for this class of problems.
1.2 Mathematical description of the algorithm
Let [math]G = (V, E)[/math] be a given graph with arc weights [math]f(e)[/math] and the single-out source node [math]u[/math]. Denote by [math]d(v)[/math] the shortest distance between the source [math]u[/math] and the node [math]v[/math].
Suppose that one has already calculated all the distances not exceeding a certain number [math]r[/math], that is, the distances to the nodes in the set [math]V_r = \{ v \in V \mid d(v) \le r \}[/math]. Let
- [math]
(v, w) \in \arg\min \{ d(v) + f(e) \mid v \in V, e = (v, w) \in E \}.
[/math]
Then [math]d(w) = d(v) + f(e)[/math] and [math]v[/math] lies on the shortest path from [math]u[/math] to [math]w[/math].
The values [math]d^+(w) = d(v) + f(e)[/math], where [math]v \in V_r[/math], [math]e = (v, w) \in E[/math], are called expected distances and are upper bounds for the actual distances: [math]d(w) \le d^+(w)[/math].
Dijkstra's algorithm finds at each step the node with the least expected distance, marks this node as a visited one, and updates the expected distances to the ends of all arcs outgoing from this node.
1.3 Computational kernel of the algorithm
The basic computations in the algorithm concern the following operations with priority queues:
- retrieve the minimum element (
delete_min);
- decrease the priority of an element (
decrease_key).
1.4 Macro structure of the algorithm
Pseudocode of the algorithm:
Input data:
graph with nodes V and arcs E with weights f(e);
source node u.
Output data: distances d(v) to each node v ∈ V from the node u.
Q := new priority queue
for each v ∈ V:
if v = u then d(v) := 0 else d(v) := ∞
Q.insert(v, d(v))
while Q ≠ ∅:
v := Q.delete_min()
for each e = (v, w) ∈ E:
if d(w) > d(v) + f(e):
d(w) := d(v) + f(e)
Q.decrease_key(w, d(w))
1.5 Implementation scheme of the serial algorithm
A specific implementation of Dijkstra's algorithm is determined by the choice of an algorithm for priority queues. In the simplest case, it can be an array or a list in which search for the minimum requires the inspection of all nodes. Algorithms that use heaps are more efficient. The variant using Fibonacci heaps [2] has the best known complexity estimate.
It is possible to implement the version in which nodes are added to the queue at the moment of the first visit rather than at the initialization stage.
1.6 Serial complexity of the algorithm
The serial complexity of the algorithm is [math]O(C_1 m + C_2n)[/math], where
- [math]C_1[/math] is the number of operations for decreasing the distance to a node;
- [math]C_2[/math] is the number of operations for calculating minima.
The original Dijkstra's algorithm used lists as an internal data structure. For such lists, [math]C_1 = O(1)[/math], [math]C_2 = O(n)[/math], and the total complexity is [math]O(n^2)[/math].
If Fibonacci heaps [2] are used, then the time for calculating a minimum decreases to [math]C_2 = O(\ln n)[/math] and the total complexity is [math]O(m + n \ln n)[/math], which, asymptotically, is the best known result for this class of problems.
1.7 Information graph
Figure 1 shows the graph of the basic implementation of Dijkstra's algorithm based on lists or arrays.
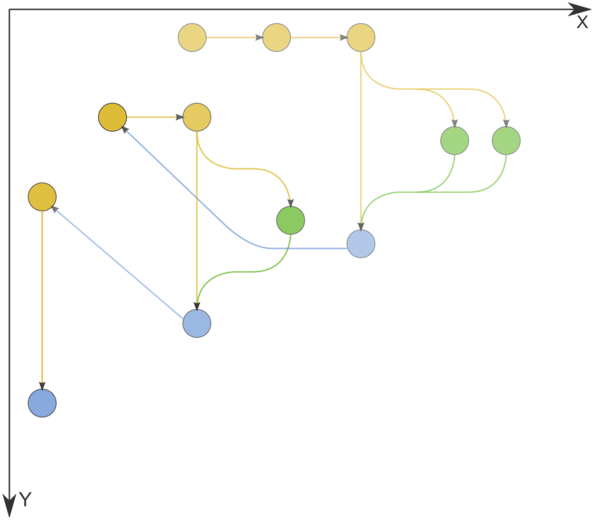
Figure 1. Information graph of Dijkstra's algorithm. The input and output data are not shown. n=3. Comparison operations, operations for changing node labels, and node labeling operations are indicated in yellow, green, and blue, respectively.
1.8 Parallelization resource of the algorithm
Dijkstra's algorithm admits an efficient parallelization [3] Its average execution time is [math]O(n^{1/3}\ln n)[/math], and the computational complexity is [math]O(n \ln n + m)[/math].
The algorithm of Δ-stepping can be regarded as a parallel version of Dijkstra's algorithm.
1.9 Input and output data of the algorithm
Input data: weighted graph [math](V, E, W)[/math] ([math]n[/math] nodes [math]v_i[/math] and [math]m[/math] arcs [math]e_j = (v^{(1)}_{j}, v^{(2)}_{j})[/math] with weights [math]f_j[/math]), source node [math]u[/math].
Size of input data: [math]O(m + n)[/math].
Output data (possible variants):
- for each node [math]v[/math] of the original graph, the last arc [math]e^*_v = (w, v)[/math] lying on the shortest path from [math]u[/math] to [math]v[/math] or the corresponding node [math]w[/math];
- for each node [math]v[/math] of the original graph, the summarized weight [math]f^*(v)[/math] of the shortest path from [math]u[/math] to [math]v[/math].
Size of output data: [math]O(n)[/math].
1.10 Properties of the algorithm
2 Software implementation of the algorithm
2.1 Implementation peculiarities of the serial algorithm
2.2 Possible methods and considerations for parallel implementation of the algorithm
2.3 Run results
2.4 Conclusions for different classes of computer architecture
3 References
- ↑ Dijkstra, E W. “A Note on Two Problems in Connexion with Graphs.” Numerische Mathematik 1, no. 1 (December 1959): 269–71. doi:10.1007/BF01386390.
- ↑ 2.0 2.1 2.2 Fredman, Michael L, and Robert Endre Tarjan. “Fibonacci Heaps and Their Uses in Improved Network Optimization Algorithms.” Journal of the ACM 34, no. 3 (July 1987): 596–615. doi:10.1145/28869.28874.
- ↑ Crauser, A, K Mehlhorn, U Meyer, and P Sanders. “A Parallelization of Dijkstra's Shortest Path Algorithm,” Proceedings of Mathematical Foundations of Computer Science / Lecture Notes in Computer Science, 1450:722–31, Berlin, Heidelberg: Springer, 1998. doi:10.1007/BFb0055823.
