Метод Гивенса (вращений) QR-разложения квадратной матрицы (вещественный точечный вариант)
| Метод Гивенса (вращений) QR-разложения квадратной матрицы | |
| Последовательный алгоритм | |
| Последовательная сложность | 2n^3 |
| Объём входных данных | n^2 |
| Объём выходных данных | n^2 |
| Параллельный алгоритм | |
| Высота ярусно-параллельной формы | 11n-16 |
| Ширина ярусно-параллельной формы | O(n^2) |
Основные авторы описания: А.В.Фролов.
Содержание
- 1 Свойства и структура алгоритма
- 1.1 Общее описание алгоритма
- 1.2 Математическое описание алгоритма
- 1.3 Вычислительное ядро алгоритма
- 1.4 Макроструктура алгоритма
- 1.5 Схема реализации последовательного алгоритма
- 1.6 Последовательная сложность алгоритма
- 1.7 Информационный граф
- 1.8 Ресурс параллелизма алгоритма
- 1.9 Входные и выходные данные алгоритма
- 1.10 Свойства алгоритма
- 2 Программная реализация
- 3 Литература
1 Свойства и структура алгоритма
1.1 Общее описание алгоритма
Метод Гивенса (в отечественной математической литературе называется также методом вращений) используется для разложения матриц в виде A = QR (Q - унитарная, R — правая треугольная матрица)[1]. При этом матрица Q хранится и используется не в явном виде, а в виде произведения матриц вращения. Каждая из матриц вращения (Гивенса)
номера столбцов: \begin{matrix} \ _{i-1}\quad _i\quad _{i+1} & \ & _{j-1}\ \ _j\quad _{j+1}\end{matrix}
T_{ij} = \begin{bmatrix} 1 & \cdots & 0\quad 0\quad 0 & \cdots & 0\quad 0\quad 0 & \cdots & 0 \\ \vdots & \ddots & \vdots & \vdots & \vdots & \vdots \\ 0 & \cdots & 1\quad 0\quad 0 & \cdots & 0\quad 0\quad 0 & \cdots & 0 \\ 0 & \cdots & 0\quad c\quad 0 & \cdots & 0\ -s\ 0 & \cdots & 0 \\ 0 & \cdots & 0\quad 0\quad 1 & \cdots & 0\quad 0\quad 0 & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \vdots \\ 0 & \cdots & 0\quad 0\quad 0 & \cdots & 1\quad 0\quad 0 & \cdots & 0 \\ 0 & \cdots & 0\quad s\quad 0 & \cdots & 0\quad c\quad 0 & \cdots & 0 \\ 0 & \cdots & 0\quad 0\quad 0 & \cdots & 0\quad 0\quad 1 & \cdots & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & \cdots & 0\quad 0\quad 0 & \cdots & 0\quad 0\quad 0 & \cdots & 1 \\ \end{bmatrix}
может быть определена парой индексов и одним параметром. Это позволяет в стандартной реализации метода Гивенса хранить результаты разложения на месте матрицы A без использования дополнительных массивов. QR-разложение матрицы A может быть использовано в разных целях: как для решения СЛАУ вида Ax = b, так и в качестве одного из шагов так называемого QR-алгоритма нахождения собственных чисел матрицы.
На каждом шаге алгоритма две строки преобразуемой матрицы подвергаются преобразованию вращения. При этом параметр такого преобразования подбирается так, чтобы один из поддиагональных элементов преобразуемой матрицы стал нулевым. Сначала в нуль последовательно обращаются элементы 1-го столбца, затем 2-го, и т.д. до n-1-го, после чего получившаяся матрица - это и есть матрица R. Сам шаг алгоритма распадается на две части: подбор параметра вращения и выполнение вращения над двумя строками матрицы. Поскольку слева от "рабочего" столбца элементы вращаемых строк равны 0, то там выполнять вращение не нужно. Вращение элементов строк в текущем столбце выполняется одновременно с подбором параметра вращения. Таким образом, вторая часть шага заключается в выполнении вращения двумерных векторов, составленных из элементов вращаемых строк в столбцах справа от "рабочего". Каждое такое вращение эквивалентно перемножению двух комплексных чисел (или в сумме 4 умножениям, 1 сложению и 1 вычитанию действительных), одно из которых имеет модуль 1. Подбор параметра вращения по двум элементам "рабочего" столбца является более сложной операцией, что связано в том числе и с необходимостью минимизации влияния ошибок округления. Обычно для хранения матрицы вращения используется тангенс половинного угла t, с которым простыми формулами (т.н. "боевыми формулами тригонометрии") связаны косинус c и синус s самого угла:
c = (1 - t^2)/(1 + t^2), s = 2t/(1 + t^2)
Именно t обычно и хранится в соответствующем элементе массива.
1.2 Математическое описание алгоритма
Для получения QR-разложения квадратной матрицы A последнюю приводят к правой треугольной (R - от слова right) последовательностью умножений её слева на матрицы вращения T_{1 2}, T_{1 3}, ..., T_{1 n}, T_{2 3}, T_{2 4}, ..., T_{2 n}, ... , T_{n-2 n}, T_{n-1 n}.
Каждая из матриц T_{i j} задаёт вращение в 2-мерном подпространстве, связанном с i-й и j-й компонентами столбцов, остальные компоненты не меняются. При этом вращение подбирается так, чтобы элемент новой матрицы в j-й строке и i-м столбце стал нулевым. Поскольку вращения и тождественные преобразования нулевых векторов оставляют их нулевыми, то последующие вращения сохраняют полученные ранее нули слева и сверху от текущего обнуляемого элемента.
В конце процесса имеем R=T_{n-1 n}T_{n-2 n}T_{n-2 n-1}...T_{1 3}T_{1 2}A.
Так как матрицы вращения унитарны, то естественно получается Q=(T_{n-1 n}T_{n-2 n}T_{n-2 n-1}...T_{1 3}T_{1 2})^* =T_{1 2}^* T_{1 3}^* ...T_{1 n}^* T_{2 3}^* T_{2 4}^* ...T_{2 n}^* ...T_{n-2 n}^* T_{n-1 n}^* и A=QR.
В вещественном случае матрицы вращения ортогональны и Q=(T_{n-1 n}T_{n-2 n}T_{n-2 n-1}...T_{1 3}T_{1 2})^T =T_{1 2}^T T_{1 3}^T ...T_{1 n}^T T_{2 3}^T T_{2 4}^T ...T_{2 n}^T ...T_{n-2 n}^T T_{n-1 n}^T.
Для завершения математического описания остаётся записать вычисление[2] матрицы вращения T_{i j} и формулы её умножения на текущую промежуточную матрицу.
Пусть в позиции (i,i) преобразуемой матрицы стоит число x, а в позиции (i,j) - число y.
Тогда для минимизации влияния ошибок округления сначала вычисляется равномерная норма вектора z = max (|x|,|y|).
Если она равна 0, то поворот не требуется: t=s=0, c=1.
Если z=|x|, то вычисляем y_1=y/x и далее c = \frac {1}{\sqrt{1+y_1^2}}, s=-c y_1, t=\frac {1-\sqrt{1+y_1^2}}{y_1}, а в позиции (i,i) после поворота будет число x \sqrt{1+y_1^2}.
Если же z=|y|, то вычисляем x_1=x/y и далее t=x_1 - x_1^2 sign(x_1), s=\frac{sign(x_1)}{\sqrt{1+x_1^2}}, c = s x_1, а в позиции (i,i) после поворота будет число y \sqrt{1+x_1^2} sign(x).
После получения элементов c и s матрицы вращения T_{i j} запись преобразования для каждого столбца правее i-го выглядит просто. Если в k-м столбце в позиции c номером i стоит x, а в позиции с номером j стоит y, то их новые значения будут cx - sy и sx + cy, соответственно, как если бы комплексное число с действительной частью x и мнимой y умножили на комплексное число (c,s).
1.3 Вычислительное ядро алгоритма
Вычислительное ядро алгоритма можно представить состоящим из операций двух типов. Первый - операции вычисления параметров вращения, второй - вращение (может быть эквивалентно записано как произведение двух комплексных чисел, модуль одного из которых равен 1).
1.4 Макроструктура алгоритма
Операции вычисления параметров вращений образуют из себя треугольник на двумерной сетке, операции двумерных вращений - пирамиду на трёхмерной сетке.
1.5 Схема реализации последовательного алгоритма
Последовательность выполнения алгоритма обычно записывается как последовательное "обнуление" поддиагональных элементов столбцов, начиная с 1-го столбца и заканчивая предпоследним (n-1)-м.
При этом в рамках "обнуления" i-го столбца последовательно "обнуляются" его элементы, начиная с (i+1)-го и заканчивая n-м.
Каждое "обнуление" элемента в позиции (j, i) состоит из двух шагов: а) вычисление параметров матрицы вращения T_{ij} таких, чтобы обнулился элемент в позиции (j, i); б) умножение слева матрицы вращения T_{ij} на текущую версию матрицы.
1.6 Последовательная сложность алгоритма
В последовательной версии основная сложность алгоритма определяется прежде всего массовыми операциями вращения. Они, если не учитывать возможную разреженность, составляют (в главном члене) n^3/3 операций комплексного умножения или, если не прибегать к ухищрениям, 4n^3/3 вещественных умножений и 2n^3/3 вещественных сложений/вычитаний.
При классификации по последовательной сложности, таким образом, метод Гивенса относится к алгоритмам с кубической сложностью.
1.7 Информационный граф
Макрограф алгоритма изображён на рисунке 1, графы макровершин - на последующих.

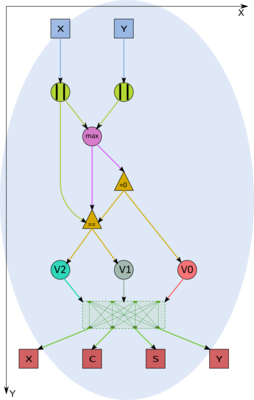
Рисунок 2. Выбор метода вычисления параметров поворота в вершинах F1.
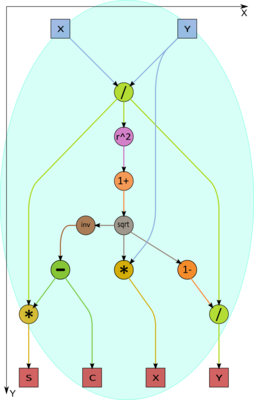
Рисунок 3. Вычисление параметров поворота для различных x и y в вершине V2.
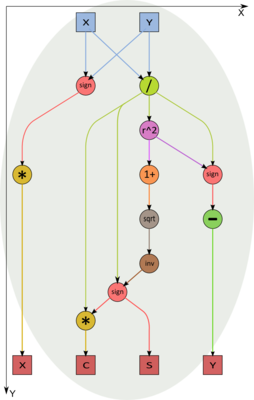
Рисунок 4. Вычисление параметров поворота для одинаковых x и у в вершине V1.



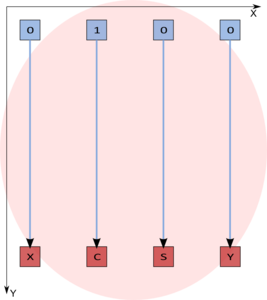
Рисунок 5. Вычисление параметров поворота для нулевых x и у в вершине V0.
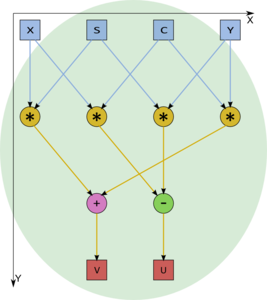
Рисунок 6. Внутренний граф вершин F2 с входными и выходными параметрами: (u,v) = (c,s)(x,y)


{kind=link}
1.8 Ресурс параллелизма алгоритма
Для понимания ресурса параллелизма в разложении матрицы порядка n методом Гивенса нужно рассмотреть критический путь графа.
Как видно из описания подграфов, макровершина вычисления параметров поворота F1 в графе намного "весомее" вершины поворота F2. А именно, в макровершине поворота критический путь - всего-навсего одно умножение (их 4, но все можно выполнить параллельно) и одно сложение/вычитание (их 2, но они тоже параллельны). Макровершина же вычисления параметров даёт в худшем случае критический путь, в котором одно вычисление квадратного корня, и по две операции деления, умножения, сложения/вычитания.
Поэтому по грубой оценке критический путь в основном будет идти через 2n-3 макровершины вычисления параметров F1, а также через n-1 макровершин поворотов. В сумме это даёт критический путь, проходящий по 2n-3 операциям вычисления квадратного корня, 4n-6 делениям, по 5n-7 умножениям и сложениям/вычитаниям. В макрографе, представленном на рисунке, один из критических путей может быть представлен, например, как прохождение по "верхней линии" вершин F1 (это n-1 штук) и затем попеременное выполнение F2 и F1 (n-2 раза), после чего ещё одно выполнение F2.
Поэтому в параллельном варианте, в отличие от последовательного, вычисления квадратных корней и деления будут определять довольно значительную долю требуемого времени. При реализации на конкретных вычислительных архитектурах наличие в отдельных ярусах ЯПФ отдельных вычислений квадратных корней и делений может породить и другие проблемы. Например, при реализации на ПЛИСах остальные вычисления (умножения и сложения/вычитания) могут быть конвейеризованы, что даёт экономию и по ресурсам на программируемых платах; вычисления же квадратных корней из-за их изолированности приведут к занятию ресурсов на платах, которые будут простаивать большую часть времени.
При классификации по высоте ЯПФ, таким образом, метод Гивенса относится к алгоритмам с линейной сложностью. При классификации по ширине ЯПФ его сложность будет квадратичной.
1.9 Входные и выходные данные алгоритма
Входные данные: плотная квадратная матрица A (элементы a_{ij}).
Объём входных данных: n^2.
Выходные данные: правая треугольная матрица R (ненулевые элементы r_{ij} в последовательном варианте хранятся в элементах исходной матрицы a_{ij}), унитарная (ортогональная) матрица Q - как произведение матриц вращения (их параметры t_{ij} в последовательном варианте хранятся в элементах исходной матрицы a_{ij}).
Объём выходных данных: n^2.
1.10 Свойства алгоритма
Соотношение последовательной и параллельной сложности, как хорошо видно, является квадратичным, что даёт хороший стимул для распараллеливания.
При этом вычислительная мощность алгоритма, как отношение числа операций к суммарному объему входных и выходных данных, линейна.
Алгоритм в рамках выбранной версии полностью детерминирован.
Вычислительная погрешность в методе Гивенса (вращений) растет линейно, как и в методе отражений (Хаусхолдера).
2 Программная реализация
2.1 Особенности реализации последовательного алгоритма
В простейшем варианте метод Гивенса (вращений) QR-разложения квадратной вещественной матрицы на Фортране можно записать так:
DO I = 1, N-1
DO J = I+1, N
CALL PARAMS (A(I,I), A(J,I), C, S)
DO K = I+1, N
CALL ROT2D (C, S, A(I,K), A(J,K))
END DO
END DO
END DO
Подпрограмма вращения ROT2D может быть записана, если операции с комплексными числами реализованы в трансляторе грамотно, так:
SUBROUTINE ROT2D (C, S, X, Y)
COMPLEX Z
REAL ZZ(2)
EQUIVALENCE Z, ZZ
Z = CMPLX(C, S)*CMPLX(X,Y)
X = ZZ(1)
Y = ZZ(2)
RETURN
END
или же так:
SUBROUTINE ROT2D (C, S, X, Y)
ZZ = C*X - S*Y
Y = S*X + C*Y
X = ZZ
RETURN
END
(с точки зрения графа алгоритма эти записи эквивалентны).
Подпрограмма вычисления параметров вращения может быть такой:
SUBROUTINE PARAMS (X, Y, C, S)
Z = MAX (ABS(X), ABS(Y))
IF (Z.EQ.0.) THEN
C OR (Z.LE.OMEGA) WHERE OMEGA - COMPUTER ZERO
C = 1.
S = 0.
ELSE IF (Z.EQ.ABS(X))
R = Y/X
RR = R*R
RR2 = SQRT(1+RR)
X = X*RR2
Y = (1-RR2)/R
C = 1./RR2
S = -C*R
ELSE
R = X/Y
RR = R*R
RR2 = SQRT (1+RR)
X = SIGN(Y, X)*RR
Y = R - SIGN(RR,R)
S = SIGN(1./RR2, R)
C = S*R
END IF
RETURN
END
В приведенной реализации параметр матрицы вращения t записывается туда, где освобождается место (элемент преобразованной матрицы c этими индексами заведомо равен нулю), что позволяет легко восстанавливать матрицы вращения при надобности.
2.2 Возможные способы и особенности параллельной реализации алгоритма
На суперкомпьютерах кластерной (или подобной) архитектуры вполне возможна блочная нарезка алгоритма (с использованием координатных обобщённых развёрток графа алгоритма) и его распределение по разным узлам (MPI). В то же время внутренний параллелизм в блоках будет реализовывать частично многоядерные возможности узлов (OpenMP), а частично даже суперскалярность ядер. На такую реализацию следует нацелиться, исходя из структуры графа алгоритма.
Несмотря на то, что на данный момент это пока нельзя проверить на реализациях, структура графа такова, что позволяет надеяться на получение хорошей масштабируемости. За это говорит не только хороший (линейный) показатель критического пути графа, но и хорошая координатная структура обобщённых развёрток графа, что даёт возможность хорошей блочной нарезки графа алгоритма.
Поиски по известным пакетам программ привели к неожиданному результату [3]. Несмотря на то, что в большинстве старых "последовательных" пакетов как правило наличествует и программа QR-разложения методом Гивенса, в новых, рассчитанных на параллельное исполнение, пакетах QR-разложение осуществляют только с помощью метода Хаусхолдера (отражений), который именно по параллельным свойствам проигрывает методу Гивенса. Мы связываем это с тем, что метод Хаусхолдера (отражений) легко записывается через BLAS-процедуры и не требует переупорядочивания обычного хода циклов (разве что при введении блочности, но это не "косая", а координатная нарезка циклов), а вот для параллельной реализации метода Гивенса (вращений) не избежать перезаписи циклов, поскольку максимально параллельный вариант в нём требует применения cкошенного (в узком понимании этого термина) параллелизма. Поэтому временно описание масштабируемости реализаций данного алгоритма невозможно - пока нет материала для исследования этой масштабируемости.
2.3 Результаты прогонов
2.4 Выводы для классов архитектур
Сложность логической структуры модуля вычисления параметров матриц вращения позволяет нам рекомендовать читателю не использовать для работы в качестве ускорителей универсальных процессоров такие модули, как ПЛИСы, поскольку значительная часть их оборудования будет простаивать. Определённые сложности это может вызвать и на архитектуре с универсальными процессорами, однако общая структура алгоритма всё же позволяет надеяться там на хорошие показатели: так, на суперкомпьютерах кластерной архитектуры вполне возможна блочная нарезка алгоритма для распределения по разным узлам, в то время как внутренний параллелизм в блоках будет реализовывать частично многоядерные возможности узлов, а частично даже суперскалярность ядер.
3 Литература
- ↑ В.В.Воеводин, Ю.А.Кузнецов. Матрицы и вычисления. М.: Наука, 1984.
- ↑ Воеводин В.В. Вычислительные основы линейной алгебры. М.: Наука, 1977.
- ↑ Фролов А.В., Антонов А.С., Воеводин Вл.В., Теплов А.М. Сопоставление разных методов решения одной задачи по методике проекта Algowiki // Подана на конференцию "Параллельные вычислительные технологии (ПаВТ'2016)".