Участник:EasyBreezy/Стабилизированный метод бисопряженных градиентов (BiCGSTAB): различия между версиями
Перейти к навигации
Перейти к поиску
[math]Ax = b, A \in R^{N \times N}, b \in R^N[/math]
[math][/math]
[math]K = K^k(A, r^0), L = K^k(A, \overline r^0)[/math]
[math]x^{k + 1} = x^k + \alpha_k p_k + \omega_k s_k[/math]
[math]p^{k + 1} = r^{k + 1} + \beta_k p_k - \omega_k Ap_k[/math]
| Строка 109: | Строка 109: | ||
=== Ресурс параллелизма алгоритма === | === Ресурс параллелизма алгоритма === | ||
| − | Основной прирост производительности параллельной версии алгоритма дает использование параллельных операций вычисления скалярного произведения. Каждая из | + | Основной прирост производительности параллельной версии алгоритма дает использование параллельных операций вычисления скалярного произведения, суммы векторов, а так же произведения матрицы на вектор. Каждая из операций вычисления скалярного произведения и суммы векторов, выполняемая на p процессорах, за счет метода сдваивания может ускориться до \log_2 p раз. Ускорение же при умножении матрицы на вектор может достигать p раз. |
=== Входные и выходные данные алгоритма === | === Входные и выходные данные алгоритма === | ||
Версия 00:05, 16 октября 2016
Основные авторы описания:
Содержание
- 1 Свойства и структура алгоритма
- 1.1 Общее описание алгоритма
- 1.2 Математическое описание алгоритма
- 1.3 Вычислительное ядро алгоритма
- 1.4 Макроструктура алгоритма
- 1.5 Схема реализации последовательного алгоритма
- 1.6 Последовательная сложность алгоритма
- 1.7 Информационный граф
- 1.8 Ресурс параллелизма алгоритма
- 1.9 Входные и выходные данные алгоритма
- 1.10 Свойства алгоритма
- 2 Программная реализация алгоритма
- 2.1 Особенности реализации последовательного алгоритма
- 2.2 Локальность данных и вычислений
- 2.3 Возможные способы и особенности параллельной реализации алгоритма
- 2.4 Масштабируемость алгоритма и его реализации
- 2.5 Динамические характеристики и эффективность реализации алгоритма
- 2.6 Выводы для классов архитектур
- 2.7 Существующие реализации алгоритма
- 3 Литература
1 Свойства и структура алгоритма
1.1 Общее описание алгоритма
- Стабилизированный метод бисопряженных градиентов, так же известный как BiCGSTAB (Biconjugate gradient stabilized method), был предложен голландским математиком Хенком ван дер Ворстом в 1992 году. Статья, в которой описывался метод, стала самым цитируемым научным трудом в области математики в 1990х годах.
- Метод появился, как ответ на задачу о построении способа решения систем линейных алгебраических уравнений произвольного вида. На момент появления BiCGSTAB уже существовали методы решения СЛАУ произвольного типа, в том числе и в комплексном пространстве, например метод бисопряженных градиентов. Однако существующие на тот момент методы либо обладали недостаточной скоростью сходимости, либо использовали в вычислениях тяжелые операции, такие как транспонирования матрицы, которые усложняли распараллеливание на многопроцессорных машинах.
- BiCGSTAB является итерационным методом решения систем линейных алгебраических уравнений. Мощь метода заключается в том, что его можно применять к матрицам общего вида, в том числе с комплексными коэффициентами. В процессе выполнения BiCGSTAB не использует для вычисления плохо распараллеливаемых операций, не допускает накопления погрешностей округления и нестабильного поведения невязки. Эти факторы выгодно отличают его от предшественников: метода бисопряженных градиентов и квадратичного метода сопряженных градиентов, из которого BiCGSTAB фактически и вытекает. К преимуществам так же можно добавить более высокую в общем случае скорость сходимости относительно ближайших конкурентов. Тем не менее, для некоторых видов СЛАУ BiCGSTAB может уступать более простым методам.
- Благодаря свойствам алгоритма область применения метода весьма широка. Фактически, он используется во всех задачах, где требуется решать СЛАУ, в том числе СЛАУ большой размерности, к которым сводится большое количество численных методов, применяемых при решении задач математического моделирования.
- BiCGSTAB относится к классу так называемых проекционных методов. Основная идея методов данного класса: искать итерационным способом наилучшее приближение решения в некотором подпространстве пространства [math]R^n[/math], и чем шире подпространство, в котором ищется приближение решения, тем ближе будет приближенное решение к точному на каждой итерации. В качестве такого подпространства используются пространства Крылова, порожденные матрицей системы и невязкой первого приближения: [math]K^m (A, r^0) = span(r^0, Ar^0, A^2r^0, ..., A^{m-1} r^0).[/math]
- Изложим основную идею любого проекционного метода, заложенную в том числе и в BiCGSTAB. Для простоты выкладок и рассуждений здесь и далее будем считать, что матрица системы и ее правая часть вещественны. Без ограничения общности все дальнейшие рассуждения могут быть перенесены и на комплексный случай. Итак, пусть решается система [math]Ax=b[/math] с невырожденной матрицей [math]A \in R^{n \times n}[/math] и ненулевым вектором [math]b \in R^n[/math]. Имеются два подпространства [math]K_n[/math] и [math]L_n[/math]. Требуется найти вектор [math]x \in K_n[/math], который обеспечивает решение системы, оптимальное относительно подпространства L, то есть требуется выполнение условия Петрова-Галеркина: [math](Ax,z)=(b,z), \forall z \in L_n[/math]. В данном случае вектор x называется обобщенным решением системы.
- Условие Петрова-Галеркина можно записать и через определение невязки. Пусть [math]r = b - Ax[/math] - невязка, тогда условие Петрова-Галеркина перепишется в виде: [math](b - Ax, z)=(r, z),\forall z \in L_n[/math]. Это равносильно тому, что вектор невязки ортогонален пространству [math]L_n[/math].
- Пусть для СЛАУ известно некоторое приближение [math]x^0[/math] точного решения [math]x^*[/math]. Данное приближение требуется уточнить поправкой [math] \delta: b - Ax^0 + \delta \perp L[/math]. Невязка уточненного решения имеет вид: [math]r_{new} = b - Ax^0 + \delta = r^0- A\delta[/math]. Условие Петрова-Галеркина тогда можно переписать так: [math](r_{new}, z)= r^0 - (A\delta, z) = 0, \forall z \in L[/math]
- Пусть [math] dim K = dim L = m, V = (v_1, ..., v_n) \in R^{n \times m}, W = (w_1, ... w_n) \in R^{n \times m}[/math], где V и W – матрицы, столбцы которых образуют базисы пространств K и L соответственно. Пусть так же [math] \delta = Vy, z = Wq[/math], где y – коэффициенты разложения вектора поправки по базису пространства K, а q – коэффициенты разложения вектора z в пространстве L. Тогда новое приближение решения можно записать в виде: [math]x^1 = x^0 + \delta= x^0 + Vy[/math]. Из условия ортогональности Петрова-Галеркина получаем, что: [math](r - AVy, Wq) = (W^Tr^0 - AVy, q) = 0[/math]. Поскольку [math]q \neq 0[/math], то получаем СЛАУ для вектора y: [math]W^TAVy = W^Tr^0[/math]. Если предположить, что матрица [math]W^TAVy[/math] невырождена, то вектор y однозначно определяется и равен: [math]y = W^TAV^{-1}W^Tr^0[/math]. Подставляя найденные коэффициенты разложения в выражение для первого приближения получаем: [math]x^1 = x^0 + \delta = x^0 + W^TAV^{-1}W^Tr^0y[/math]
- Подведем итог. Общий порядок шагов любого проекционного метода следующий:
- Выбрать пару подпространств [math]K[/math] и [math]L[/math]
- Найти базис V пространства K и базис W пространства [math]L[/math];
- Вычислить невязку
- Найти [math]y = W^T AV^{-1} W^T r^0[/math]
- Положить [math]x = x + Vy[/math]
- Если не достигнут критерий остановки итерационного процесса, то повторить алгоритм, начиная с первого шага.
- Как будет показано далее, в BiCGSTAB не требуется вычислять матрицу [math]W^T AV^{-1}[/math] в явном виде.
1.2 Математическое описание алгоритма
- Рассмотрим СЛАУ с вещественными коэффициентами:
- В основу алгоритма ложиться идея проекционного метода и использование свойства A-бисопряженности системы векторов, а именно: векторы [math]p^1, p^2, ...[/math] и [math]\overline p^1, \overline p^2, ...[/math] бисопряжены, если [math](Ap^i,p^j ) = 0,[/math] при [math]i \neq j[/math]. Фактически, данное условие эквивалентно биортогональности относительно энергетического скалярного произведения.
- Общая концепция проекционных методов предписывает нам выбрать два подпространства. В нашем случае подпространства мы выберем два подпространства, задаваемые матрицей системы А, вектором невязки на нулевой итерации [math]r^0[/math] и вектором [math]\overline r^0[/math]. который выбирается из условия [math](r^0, \overline r^0) \neq 0[/math]:
- Метод основан на построении биортогонального базиса [math]p^0, p^1, ... p^k .. [/math] пространства [math]K^k (A, r^0) [/math] и вычислении поправки такой, что новое приближение на очередной итерации было бы ортогонально второму подпространству Крылова. Базисные вектора строятся до тех пор, пока не будет достигнут критерий остановки итерационного процесса, а каждое последующее приближение формируется, как сумма приближения на предыдущей итерации и найденной поправки. Критерием останова итерационного процесса является достижения невязкой значения, которое меньше некоторого наперед заданного числа [math]\epsilon[/math].
- Основной итерационный процесс задается формулами:
- где:
- [math]x^{k + 1}[/math] - приближение на следующей итерации
- [math]x^k[/math] - приближение на предыдущей итерации
- [math]p_k[/math] - базисный вектор подпространства Крылова, порожденного матрице СЛАУ и невязкой
- [math]\alpha_k, \omega_k[/math] - вспомогательные скаляры, определяемые для каждого шага итерации
- [math]s_k[/math] - вспомогательный вектор
- [math]p^{k + 1}[/math] - [math]k + 1[/math]-ый базисный вектор
- [math]r^{k + 1}[/math] - невязка [math]k + 1[/math]-ой итерации
- [math]\beta_k[/math] - вспомогательный коэффициент
- Вспомогательный вектор выражается следующим образом:
- [math]s_k = r^k - \alpha_k Ap_k[/math]
- Вспомогательные коэффициенты вычисляются по формулам:
- [math]\alpha_k = \frac{(r^k, \overline r^0}{(Ap_k, \overline r^0)}[/math]
- [math]\omega_k = \frac{(As_k, s_k)}{(As_k, As_k)}[/math]
- [math]\beta_k = \frac{(r^{k + 1}, \overline r^0)}{(r^k, \overline r^0}[/math]
- Подведем итог и запишем итерационный процесс
- Подготовительный этап:
- Выбирается некоторое начальное приближение [math]x^0[/math]
- По выбранному приближению находится невязка [math]r^0 = b - Ax^0[/math]
- Из условия [math](r^0, \overline r^0) \neq 0[/math] выбирается вектор [math]\overline r^0[/math]
- Положим [math]p^0 = r^0[/math]
- Устанавливаем счетчик итераций: [math]n = 0[/math]
- Итерационный процесс:
- Находим [math]\alpha_k[/math]
- По найденному [math]\alpha_k[/math] вычисляем [math]s_k[/math]
- По найденному [math]s_k[/math] вычисляется вспомогательный коэффициент [math]\omega_k[/math]
- Находится новое приближение [math]x^{k + 1}[/math]
- Вычисляется невязка [math]r^{k + 1}[/math]. Если выполнено условие [math]\parallel r^{k + 1} \parallel \lt \epsilon[/math], то алгоритм завершается.
- Вычисляется вспомогательный коэффициент [math]\beta_k[/math]
- Вычисляется новый базисный вектор: [math]p^{k + 1}[/math]
- Увеличивается номер итерации: [math]n = n + 1[/math]
- Переход к первому шагу итерационного процесса.
1.3 Вычислительное ядро алгоритма
- Вычислительное ядро полностью совпадает с итерационным процессом. Подготовка к итерационному процессу в ядро не включается.
1.4 Макроструктура алгоритма
На каждой итерации алгоритма используются:
- Трижды Скалярное произведение векторов, вещественная версия, последовательно-параллельный вариант
- Единожды Умножение плотной матрицы на вектор
1.5 Схема реализации последовательного алгоритма
1.6 Последовательная сложность алгоритма
- Всего в вычислительном блоке алгоритма присутствует 20 трудоемких операций: 2 операции умножения матрицы на вектор, 6 скалярных произведений и 6 сложений/вычитаний векторов и 6 умножений вектора на число.
- Каждое скалярное произведение требует [math]n[/math] произведений и [math]n - 1[/math] сложение, то есть [math]2n - 1[/math] операции. Скалярных произведений всего 6 штук (включая поиск нормы), что дает нам [math]12n - 6[/math] операций.
- Умножение матрицы размерности [math]n \times n[/math] на вектор эквивалентно взятию еще [math]n[/math] скаляров, и так как таких операций в вычислительном ядре 2, то дополнительно имеется еще [math]2n(2n - 1)[/math] операций.
- Наконец, сложение или вычитание векторов требует [math]6n[/math] соотвествующих операций. Столько же требует 6 произведений вектора на число.
- Итого: [math]2n(2n - 1) + 12n - 6 + 6n + 6n = 4n^2 + 22n - 6[/math] операций.
- Нетрудоемкие операции, вроде извлечение квадратного корня и деление вещественных чисел друг на друга, не принимаются в расчет, так как они не влияют на итоговый результат. Окончательно можно заключить, что последовательная сложность алгоритма эквивалента [math]O(n^2)[/math]
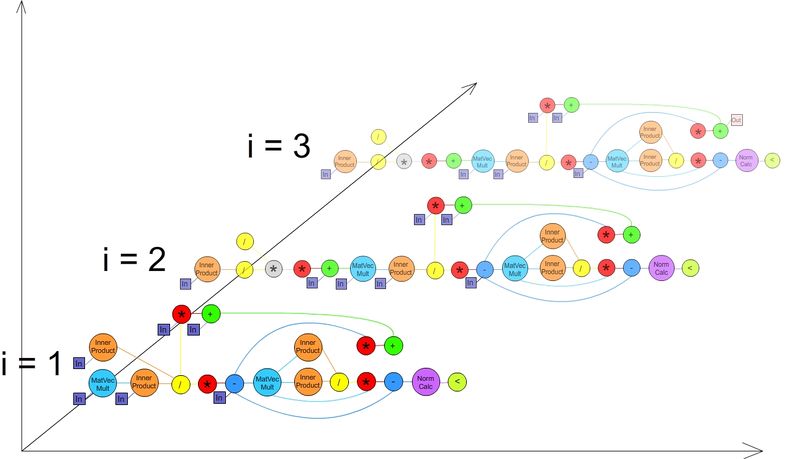
1.7 Информационный граф

Информационный граф. На графе представлены связи между операциями, выполняющимися в первых трех итерациях метода. При выполнении большего, чем 3, количества итераций, структура каждой новой будет повторять структуру третьей. Связи между итерациями не представлены, т.к. они не важны для понимания параллельной структуры алгоритма.
1.8 Ресурс параллелизма алгоритма
Основной прирост производительности параллельной версии алгоритма дает использование параллельных операций вычисления скалярного произведения, суммы векторов, а так же произведения матрицы на вектор. Каждая из операций вычисления скалярного произведения и суммы векторов, выполняемая на p процессорах, за счет метода сдваивания может ускориться до \log_2 p раз. Ускорение же при умножении матрицы на вектор может достигать p раз.
1.9 Входные и выходные данные алгоритма
- Входные данные
- Матрица [math]A \in R^{N \times N}[/math] ( [math]C^{N \times N}[/math] )
- Вектор правой части [math]b \in R^N[/math] ( [math]C^N[/math] )
- Выходные данные:
- Вектор решения СЛАУ [math]x \in R^N[/math] ( [math]C^N[/math] )
1.10 Свойства алгоритма
- BiCGSTAB хорошо зарекомендовал себя для решения систем линейных алгебраический уравнений, поскольку обладает некоторыми важными свойствами:
- Благодаря применению подхода Петрова-Галеркина и техники ортогонализации, он численно устойчив
- Не меняется вид матрицы в процессе решения
- Эффективен для решения систем большой размерности с разреженной матрицей, поскольку в методе самая трудоемкая операция - умножение матрицы на вектор
- Лучше подходит под распределенные системы, поскольку не содержит операции транспонирования матрицы
- Применим для решения систем с несимметричными матрицами.
2 Программная реализация алгоритма
2.1 Особенности реализации последовательного алгоритма
2.2 Локальность данных и вычислений
2.2.1 Локальность реализации алгоритма
2.2.1.1 Структура обращений в память и качественная оценка локальности
2.2.1.2 Количественная оценка локальности
2.2.1.3 Анализ на основе теста Apex-Map
2.3 Возможные способы и особенности параллельной реализации алгоритма
2.4 Масштабируемость алгоритма и его реализации
2.4.1 Масштабируемость алгоритма
2.4.2 Масштабируемость реализации алгоритма
2.5 Динамические характеристики и эффективность реализации алгоритма
2.6 Выводы для классов архитектур
2.7 Существующие реализации алгоритма
- Параллельная реализация алгоритма, предложенная MIT: MIT BiCGSTAB
- Параллельная реализация алгоритма в бесплатной библиотеке, поддерживающей MPI и OpenMP, HYPRE: Официальная страница Исходный код
- Параллельная реализация алгоритма на CUDA в условно бесплатной библиотеке NVIDIA AmgX: [1]