Welcome! Join us!
AlgoWiki is an open encyclopedia of algorithms’ properties and features of their implementations on different hardware and software platforms from mobile to extreme scale, which allows for collaboration with the worldwide computing community on algorithm descriptions.
AlgoWiki provides an exhaustive description of an algorithm. In addition to classical algorithm properties such as serial complexity, AlgoWiki also presents additional information, which together provides a complete description of the algorithm: its parallel complexity, parallel structure, determinacy, data locality, performance and scalability estimates, communication profiles for specific implementations, and many others.
Read more: About project.
Project structure
Algorithm classification — the main section of AlgoWiki which contains descriptions of all algorithms. Algorithms are added to the appropriate category of the classification, and classification is expanded with new sections if necessary.
Featured article
|
Properties of the algorithm:
- Sequential complexity: O(n^3)
- Height of the parallel form: O(n)
- Width of the parallel form: O(n^2)
- Amount of input data: \frac{n (n + 1)}{2}
- Amount of output data: \frac{n (n + 1)}{2}
|
1 Properties and structure of the algorithm
1.1 General description
The Cholesky decomposition algorithm was first proposed by Andre-Louis Cholesky (October 15, 1875 - August 31, 1918) at the end of the First World War shortly before he was killed in battle. He was a French military officer and mathematician. The idea of this algorithm was published in 1924 by his fellow officer and, later, was used by Banachiewicz in 1938 [7]. In the Russian mathematical literature, the Cholesky decomposition is also known as the square-root method [1-3] due to the square root operations used in this decomposition and not used in Gaussian elimination.
Originally, the Cholesky decomposition was used only for dense real symmetric positive definite matrices. At present, the application of this decomposition is much wider. For example, it can also be employed for the case of Hermitian matrices. In order to increase the computing performance, its block versions are often applied.
In the case of sparse matrices, the Cholesky decomposition is also widely used as the main stage of a direct method for solving linear systems. In order to reduce the memory requirements and the profile of the matrix, special reordering strategies are applied to minimize the number of arithmetic operations. A number of reordering strategies are used to identify the independent matrix blocks for parallel computing systems.
1.2 Mathematical description
Input data: a symmetric positive definite matrix A whose elements are denoted by a_{ij}).
Output data: the lower triangular matrix L whose elements are denoted by l_{ij}).
The Cholesky algorithm can be represented in the form
-
\begin{align}
l_{11} & = \sqrt{a_{11}}, \\
l_{j1} & = \frac{a_{j1}}{l_{11}}, \quad j \in [2, n], \\
l_{ii} & = \sqrt{a_{ii} - \sum_{p = 1}^{i - 1} l_{ip}^2}, \quad i \in [2, n], \\
l_{ji} & = \left (a_{ji} - \sum_{p = 1}^{i - 1} l_{ip} l_{jp} \right ) / l_{ii}, \quad i \in [2, n - 1], j \in [i + 1, n].
\end{align}
There exist block versions of this algorithm; however, here we consider only its “dot” version.
In a number of implementations, the division by the diagonal element l_{ii} is made in the following two steps: the computation of \frac{1}{l_{ii}} and, then, the multiplication of the result by the modified values of a_{ji} . Here we do not consider this computational scheme, since this scheme has worse parallel characteristics than that given above.
1.3 Sequential complexity of the algorithm
The following number of operations should be performed to decompose a matrix of order n using a sequential version of the Cholesky algorithm:
- n square roots,
- \frac{n(n-1)}{2} divisiona,
- \frac{n^3-n}{6} multiplications and \frac{n^3-n}{6} additions (subtractions): the main amount of computational work.
In the accumulation mode, the multiplication and subtraction operations should be made in double precision (or by using the corresponding function, like the DPROD function in Fortran), which increases the overall computation time of the Cholesky algorithm.
Thus, a sequential version of the Cholesky algorithm is of cubic complexity.
- Read more…
|
Today’s featured picture
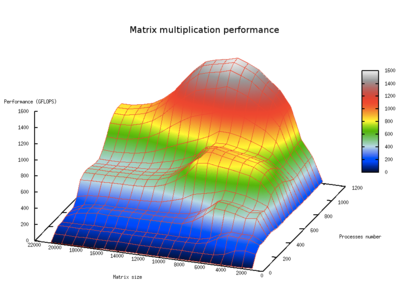 Performance for dense matrix multiplication
Readiness of articles
Finished articles:
Articles in progress:
- PageRank, VGL
- HITS, VGL
- Dijkstra, VGL, pull
- Dijkstra, VGL, push
- BFS, VGL
- Poisson equation, solving with DFT, PFFT
- Poisson equation, solving with DFT, MKL FFT
- Poisson equation, solving with DFT, AccFFT
- Poisson equation, solving with DFT, cuFFT
- Poisson equation, solving with DFT, P3DFFT
- Poisson equation, solving with DFT, FFTE
- Poisson equation, solving with DFT, FFTW
- Poisson equation, solving with DFT, scalability
- Poisson equation, solving with DFT, locality
- K-means clustering, SAP HANA
- K-means clustering, RapidMiner
- K-means clustering, SAS
- K-means clustering, MATLAB
- K-means clustering, Mathematica
- K-means clustering, Stata
- K-means clustering, Ayasdi
- Single-qubit transform of a state vector, scalability
- Single-qubit transform of a state vector, locality
- Backward substitution, locality
- Two-sided Thomas, locality
- Thomas, locality
- Thomas algorithm, locality
- Linpack, HPL
- Linpack, locality
- Householder (reflections) method for reducing a symmetric matrix to tridiagonal form, SCALAPACK
- Householder (reflections) method for reducing a symmetric matrix to tridiagonal form, locality
- Givens method, locality
- LU decomposition via Gaussian elimination, scalability
- LU decomposition via Gaussian elimination, locality
- The serial-parallel summation method, scalability
- The serial-parallel summation method, locality
- Dot product, scalability
- Dot product, locality
- Dense matrix multiplication, scalability
- Dense matrix multiplication, locality
- Horners, locality
- One step of the dqds, LAPACK
- DFS, Python, NetworkX
- DFS, C++, MPI, Parallel Boost Graph Library
- DFS, C++, Boost Graph Library
- Longest shortest path, Python/C++, NetworKit
- Longest shortest path, Java, WebGraph
- Hopcroft–Karp, Java, JGraphT
- Hungarian, Java, JGraphT
- Preflow-Push, Python, NetworkX
- Preflow-Push, C++, Boost Graph Library
- Ford–Fulkerson, Java, JGraphT
- Ford–Fulkerson, Python, NetworkX
- Ford–Fulkerson, C++, Boost Graph Library
- Tarjan's biconnected components, Java, JGraphT
- Tarjan's biconnected components, Python, NetworkX
- Tarjan's biconnected components, C++, Boost Graph Library
- DCSC for finding the strongly connected components, C++, MPI, Parallel Boost Graph Library
- Tarjan's strongly connected components, Python/C++, NetworKit
- Tarjan's strongly connected components, Python, NetworkX
- Tarjan's strongly connected components, Java, JGraphT
- Tarjan's strongly connected components, Java, WebGraph
- Tarjan's strongly connected components, C++, Boost Graph Library
- Disjoint set union, Java, JGraphT
- Disjoint set union, Boost Graph Library
- VF2, Python, NetworkX
- VF2, C++, Boost Graph Library
- VF2, C++, VF Library
- Ullman's, C++, VF Library
- Ullman's, C++, Chemical Descriptors Library
- Prim's, Java, JGraphT
- Prim's, C++, Boost Graph Library
- Kruskal's, Java, JGraphT
- Kruskal's, Python, NetworkX
- Kruskal's, C++, MPI, Parallel Boost Graph Library
- Kruskal's, C++, Boost Graph Library
- Boruvka's, locality
- Boruvka's, scalability
- Boruvka's, RCC for GPU
- Boruvka's, RCC for CPU
- Boruvka's, C++, MPI, Parallel Boost Graph Library
- Purdom's, Boost Graph Library
- Floyd-Warshall, Java, JGraphT
- Floyd-Warshall, Python, NetworkX
- Floyd-Warshall, C++, Boost Graph Library
- Johnson's, C++, Boost Graph Library
- Δ-stepping, Gap
- Δ-stepping, C++, MPI, Parallel Boost Graph Library
- BFS, MPI, Graph500
- Bellman-Ford, scalability
- Bellman-Ford, locality
- Bellman-Ford, Ligra
- Bellman-Ford, MPI, Graph500
- Bellman-Ford, Nvidia nvGraph
- Bellman-Ford, OpenMP, Stinger
- Bellman-Ford, Java, JGraphT
- Bellman-Ford, Python, NetworkX
- Bellman-Ford, C++, Boost Graph Library
- Dijkstra, Google
- Dijkstra, locality
- Dijkstra, C++, MPI: Parallel Boost Graph Library, 2
- Dijkstra, C++, MPI: Parallel Boost Graph Library, 1
- Dijkstra, Python/C++
- Dijkstra, Python
- Dijkstra, C++, Boost Graph Library
- Cholesky decomposition, scalability
- Cholesky decomposition, SCALAPACK
- Cholesky decomposition, locality
- Cooley-Tukey, scalability
- Cooley-Tukey, locality
- BFS, Ligra
- BFS, Python/C++, NetworKit
- BFS, Python, NetworkX
- BFS, Java, WebGraph
- BFS, GAP
- BFS, C++, MPI, Boost Graph Library
- BFS, C++, Boost Graph Library
- BFS, RCC for GPU
- BFS, RCC for CPU
- Boruvka's algorithm
- DCSC algorithm for finding the strongly connected components
- Purdom's algorithm
- Bellman-Ford algorithm
- Dijkstra's algorithm
- Breadth-first search (BFS)
- Linpack benchmark
- Glossary
- Assignment problem
- Finding maximal flow in a transportation network
- Graph connectivity
- Search for isomorphic subgraphs
- Construction of the minimum spanning tree (MST)
- Transitive closure of a directed graph
- All Pairs Shortest Path (APSP)
- Single Source Shortest Path (SSSP)
- Pairwise summation of numbers
- Dense matrix-vector multiplication
- Cooley–Tukey Fast Fourier Transform, radix-2 case
- Forward substitution
Started articles:
- Meet-in-the-middle attack, implementation3
- Meet-in-the-middle attack, implementation2
- Meet-in-the-middle attack, implementation1
- Meet-in-the-middle attack, scalability
- Numerical quadrature (cubature) rules on an interval (for a multidimensional cube), scalability
- Newton's method for systems of nonlinear equations, parallel3
- Newton's method for systems of nonlinear equations, parallel2
- Newton's method for systems of nonlinear equations, parallel1
- Newton's method for systems of nonlinear equations, PETSc
- Newton's method for systems of nonlinear equations, Numerical Mathematics - NewtonLib
- Newton's method for systems of nonlinear equations, Sundials
- Newton's method for systems of nonlinear equations, Numerical Recipes
- Newton's method for systems of nonlinear equations, ALIAS C++
- Newton's method for systems of nonlinear equations, scalability4
- Newton's method for systems of nonlinear equations, scalability3
- Newton's method for systems of nonlinear equations, scalability2
- Newton's method for systems of nonlinear equations, scalability1
- SDDP, scalability
- Face recognition, scalability
- K-means clustering, ELKI
- K-means clustering, R
- K-means clustering, scikit-learn
- K-means clustering, SciPy
- K-means clustering, MLPACK
- K-means clustering, OpenCV
- K-means clustering, Accord.NET
- K-means clustering, Weka
- K-means clustering, Torch
- K-means clustering, Spark
- K-means clustering, Octave
- K-means clustering, Apache Mahout
- K-means clustering, Julia
- K-means clustering, CrimeStat
- K-means clustering, scalability4
- K-means clustering, scalability3
- K-means clustering, scalability2
- K-means clustering, scalability1
- Binary search, Python
- Binary search, .NET Framework 2.0
- Binary search, Java
- Binary search, C++
- Binary search, С
- Binary search, locality
- Backward substitution, scalability
- Complete cyclic reduction, scalability
- Complete cyclic reduction, locality
- Repeated two-sided Thomas, locality
- Repeated Thomas, locality
- Kaczmarz's, MATLAB3
- Kaczmarz's, MATLAB2
- Kaczmarz's, MATLAB1
- BiCGStab, NVIDIA AmgX
- BiCGStab, HYPRE
- BiCGStab, MIT
- HPCG, scalability
- HPCG, locality
- Householder (reflections) reduction of a matrix to bidiagonal form, SCALAPACK
- Householder (reflections) reduction of a matrix to bidiagonal form, locality
- Householder (reflections) method for the QR decomposition, SCALAPACK
- Householder (reflections) method for the QR decomposition, locality
- Uniform norm of a vector, locality
- Pairwise summation of numbers, scalability
- Pairwise summation of numbers, locality
- Dense matrix-vector multiplication, scalability
- Dense matrix-vector multiplication, locality
- Lanczos, C++, MPI, 3
- Lanczos, C, MPI
- Lanczos, C++, MPI, 2
- Lanczos, C++, MPI
- Lanczos, MPI, OpenMP
- Tarjan-Vishkin biconnected components, scalability
- Tarjan-Vishkin biconnected components algorithm
- Floyd-Warshall, scalability
- Givens (rotations) method for the QR decomposition of a matrix
- Meet-in-the-middle attack
- Numerical quadrature (cubature) rules on an interval (for a multidimensional cube)
- Cubature rules
- Newton's method for systems of nonlinear equations
- Stochastic dual dynamic programming (SDDP)
- Face recognition
- K-means clustering
- Two-qubit transform of a state vector
- Hopcroft–Karp algorithm
- Auction algorithm
- Hungarian algorithm
- Finding minimal-cost flow in a transportation network
- Preflow-Push algorithm
- Ford–Fulkerson algorithm
- Gabow's edge connectivity algorithm
- Vertex connectivity of a graph
- Tarjan's algorithm for finding the bridges of a graph
- Tarjan's biconnected components algorithm
- Tarjan's strongly connected components algorithm
- Disjoint set union
- Shiloach-Vishkin algorithm for finding the connected components
- VF2 algorithm
- Ullman's algorithm
- GHS algorithm
- Prim's algorithm
- Kruskal's algorithm
- Longest shortest path
- Floyd-Warshall algorithm
- Johnson's algorithm
- Δ-stepping algorithm
- Depth-first search (DFS)
- Binary search: Finding the position of a target value within a sorted array
- Jacobi (rotations) method for finding singular values
- Lanczos algorithm in exact algorithm (without reorthogonalization)
- Serial Jacobi (rotations) method with thresholds for symmetric matrices
- Serial Jacobi (rotations) method for symmetric matrices
- The classical Jacobi (rotations) method with pivoting for symmetric matrices
- The Jacobi (rotations) method for solving the symmetric eigenvalue problem
- QR algorithm for complex Hermitian matrices as implemented in SCALAPACK
- Symmetric QR algorithm as implemented in SCALAPACK
- Hessenberg QR algorithm as implemented in SCALAPACK
- QR algorithm as implemented in SCALAPACK
- QR algorithm
- Kaczmarz's algorithm
- Biconjugate gradient stabilized method (BiCGStab)
- High Performance Conjugate Gradient (HPCG) benchmark
- Two-sided Thomas algorithm, block variant
- Block Thomas algorithm
- Complete cyclic reduction
- Repeated two-sided Thomas algorithm, pointwise version
- Serial-parallel method for solving tridiagonal matrices based on the LU decomposition and backward substitutions
- Stone doubling algorithm
- Repeated Thomas algorithm, pointwise version
- Thomas algorithm
- Stone doubling algorithm for solving bidiagonal SLAEs
- Singular value decomposition (finding singular values and singular vectors)
- Householder (reflections) reduction of a matrix to bidiagonal form
- Eigenvalue decomposition (finding eigenvalues and eigenvectors)
- Householder (reflections) method for reducing a complex Hermitian matrix to symmetric tridiagonal form
- Unitary reductions to tridiagonal form
- Classical point-wise Householder (reflections) method for reducing a matrix to Hessenberg form
- Unitary reductions to Hessenberg form
- Reducing matrices to compact forms
- Orthogonalization method with reorthogonalization
- Classical orthogonalization method
- Householder (reflections) method for the QR decomposition of a square matrix, real point-wise version
- Gaussian elimination with complete pivoting
- Gaussian elimination with diagonal pivoting
- Gaussian elimination with row pivoting
- Gaussian elimination with column pivoting
- Serial-parallel algorithm for the LU decomposition of a tridiagonal matrix
- Compact scheme for Gaussian elimination and its modifications: Tridiagonal matrix
- Gaussian elimination (finding the LU decomposition)
- Triangular decompositions
- Matrix decomposition problem
- Dense matrix multiplication
- Fast Fourier transform for powers-of-two
- Uniform norm of a vector: Real version, serial-parallel variant
- Parallel prefix scan algorithm using pairwise summation
- Pairwise summation
- LU decomposition via Gaussian elimination
|
